#cofacts
2020-02-01
bil
00:01:54
大專院校延後開學喔我覺得沒那麼容易xD
不戴口罩也沒關係啦我是要說這不是個不能戴口罩的場域
不戴口罩也沒關係啦我是要說這不是個不能戴口罩的場域
mrorz
21:19:03
我剛才發現 URL resolve 出來的順序是亂的,應該是上週上新版 API 導致的。這有點糟糕,因為之前抓錯的文件都已經寫入資料庫了,之後會繼續錯⋯⋯
https://cofacts.g0v.tw/reply/JWXgAHABd3n3h-WYH10s
讓我想想如何補救⋯⋯
https://cofacts.g0v.tw/reply/JWXgAHABd3n3h-WYH10s
讓我想想如何補救⋯⋯
mrorz
2020-02-01 22:20:47
Fixed, 求 @changhc84 review
mrorz
22:20:47
Fixed, 求 @changhc84 review
mrorz
23:44:58
GitHub
gRPC calls will return out-of-order URL fetch results. This PR reorders the result from gRPC call using original URL order. We first modify the unit test to create a failing test case: We can see ...
2020-02-02
ggm
14:26:22
[Rollbar] Free plan limit reached for account mrorz
mrorz
15:53:04
對 QAQ
新版網站一直噴 error 很 GG
新版網站一直噴 error 很 GG
- 😢1
mrorz
2020-02-02 16:07:20
我覺得先處理這兩個好了
mrorz
2020-02-02 16:08:25
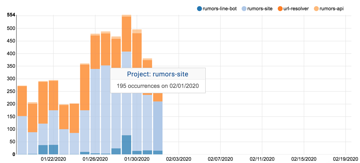
看起來是 rumors-site 一直花 quota
mrorz
2020-02-02 16:08:53
mrorz
16:08:53
mrorz
17:40:36
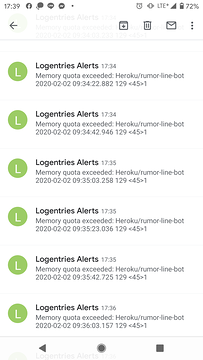
今天 chatbot 記憶體一直爆炸
到底發生什麼事情囧
到底發生什麼事情囧
mrorz
17:44:42
1/30 也很多 囧
mrorz
17:47:30
@ggm 我們可能需要升級到 standard-2X dynos / 1 GB memory
mrorz
2020-02-02 17:49:29
但他每個月 50usd / month……
Linode 便宜得多
Linode 便宜得多
好啊
mrorz
2020-02-02 17:52:14
我們目前是有那個 capacity 直接就地升級沒錯
mrorz
2020-02-02 17:56:59
還是開 2 個 standard 呀
Heroku 可以 1 個 2 個 autoscale 嗎?
1 個 standard 2x 與兩個 standard 我沒有太大經驗
Heroku 可以 1 個 2 個 autoscale 嗎?
1 個 standard 2x 與兩個 standard 我沒有太大經驗
mrorz
2020-02-02 18:08:06
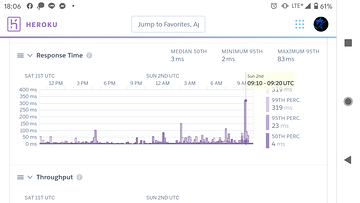
都忘了 heroku dashboard 有 metrics tab
mrorz
2020-02-02 18:08:08
mrorz
2020-02-02 18:09:08
Response time 一直不大
mrorz
2020-02-02 18:09:26
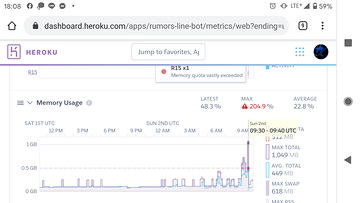
就是偶爾 memory 爆炸
mrorz
2020-02-02 18:09:58
mrorz
2020-02-03 19:26:23
今天是使用 Standard 1x (依舊是512mb)
看起來這種 memory spike 會持續數分鐘,所以可以弄個 autoscale script
如果有 memory quota 問題就 scale up 成 2 ~ 3 台
然後如果 memory 降下來就 scale down 成 1 台
之類的。
看起來這種 memory spike 會持續數分鐘,所以可以弄個 autoscale script
如果有 memory quota 問題就 scale up 成 2 ~ 3 台
然後如果 memory 降下來就 scale down 成 1 台
之類的。
mrorz
2020-02-03 19:29:13
至於 scale up 變成 2 台 512mb 的機器會不會改善,其實現在就是開 2 台
下午開了兩台之後, memory 到現在為止沒有異狀
下午開了兩台之後, memory 到現在為止沒有異狀
mrorz
2020-02-04 03:22:38
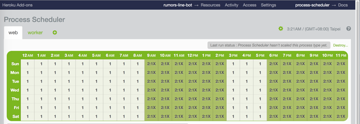
目前先這樣設定
1 是 1 台 25USD 的 standard-1x (512MB RAM)
2:1X 就是 2 台 25USD 的 standard-1x (還是 512MB RAM 但有兩台)
1 是 1 台 25USD 的 standard-1x (512MB RAM)
2:1X 就是 2 台 25USD 的 standard-1x (還是 512MB RAM 但有兩台)
mrorz
2020-02-04 03:23:31
設定的參考依據是 production LINE bot google analytics
mrorz
17:49:29
但他每個月 50usd / month……
Linode 便宜得多
Linode 便宜得多
ggm
17:51:20
好啊
mrorz
17:52:14
我們目前是有那個 capacity 直接就地升級沒錯
mrorz
17:56:59
還是開 2 個 standard 呀
Heroku 可以 1 個 2 個 autoscale 嗎?
1 個 standard 2x 與兩個 standard 我沒有太大經驗
Heroku 可以 1 個 2 個 autoscale 嗎?
1 個 standard 2x 與兩個 standard 我沒有太大經驗
mrorz
17:58:23
blog.heroku.com
We’re excited to announce that Heroku Autoscaling is now generally available for apps using web dynos. We’ve always made it seamless and simple to scale...
mrorz
18:08:06
都忘了 heroku dashboard 有 metrics tab
mrorz
18:09:08
Response time 一直不大
mrorz
18:09:26
就是偶爾 memory 爆炸

bil
18:40:33
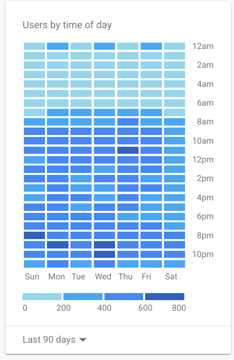
• 過去一個月送出資料庫的新文章成長近九成、工作量大增,單日使用人數也超過1,400人
• chatbot活躍使用者超過去年同期四倍
• 本月使用者轉傳的訊息也上升6成
• 農曆新年時期其實是最忙碌的時期,不實訊息全年無休,感謝所有年節大德貢獻與參與
鄰鄰蹦蹦跳跳!!!!!!!!
• chatbot活躍使用者超過去年同期四倍
• 本月使用者轉傳的訊息也上升6成
• 農曆新年時期其實是最忙碌的時期,不實訊息全年無休,感謝所有年節大德貢獻與參與
鄰鄰蹦蹦跳跳!!!!!!!!
- ❤️8
 4
4- 👯♀️5
- 🔮3
2020-02-03
mrorz
19:26:23
今天是使用 Standard 1x (依舊是512mb)
看起來這種 memory spike 會持續數分鐘,所以可以弄個 autoscale script
如果有 memory quota 問題就 scale up 成 2 ~ 3 台
然後如果 memory 降下來就 scale down 成 1 台
之類的。
看起來這種 memory spike 會持續數分鐘,所以可以弄個 autoscale script
如果有 memory quota 問題就 scale up 成 2 ~ 3 台
然後如果 memory 降下來就 scale down 成 1 台
之類的。

mrorz
19:29:13
至於 scale up 變成 2 台 512mb 的機器會不會改善,其實現在就是開 2 台
下午開了兩台之後, memory 到現在為止沒有異狀
下午開了兩台之後, memory 到現在為止沒有異狀
2020-02-04
bil
00:58:32
賀。過年人很多、人旺chatbot旺
mrorz
02:34:16
今天討論完 article reply 與 postgres,回頭看了一下 postgresql 的 fulltext search
雖然 postgresql 可以做 tokenization 與 cosine similarity search,但其實一些 text retrieval 會用的像是 tf-idf 與 smoothing 之類 elasticsearch 會做的東西都沒有這樣。
讓我想到是否該認真考慮 ZomboDB,這幾年來 ZomboDB 的開發居然都沒斷過真的很神:
https://github.com/zombodb/zombodb
雖然 postgresql 可以做 tokenization 與 cosine similarity search,但其實一些 text retrieval 會用的像是 tf-idf 與 smoothing 之類 elasticsearch 會做的東西都沒有這樣。
讓我想到是否該認真考慮 ZomboDB,這幾年來 ZomboDB 的開發居然都沒斷過真的很神:
https://github.com/zombodb/zombodb
Making Postgres and Elasticsearch work together like it's 2020 - zombodb/zombodb
mrorz
03:22:38
目前先這樣設定
1 是 1 台 25USD 的 standard-1x (512MB RAM)
2:1X 就是 2 台 25USD 的 standard-1x (還是 512MB RAM 但有兩台)
1 是 1 台 25USD 的 standard-1x (512MB RAM)
2:1X 就是 2 台 25USD 的 standard-1x (還是 512MB RAM 但有兩台)
ggm
11:31:05
The Google News Initiative is stepping up its work to train journalists and strengthen media literacy in India, building on a successful first year.
 2
2
ggm
11:31:25
google 朋友轉給我的 XD
annahung
17:59:40
@fbiannahung has joined the channel
Mike
18:01:31
@a3804430 has joined the channel
WeiLing
18:12:42
@weling.su has joined the channel
bess
19:24:15
想來敲敲這週 Cofacts 小聚有沒有防疫措施,我們想參考看看 ._.
 1
1
bess
2020-02-04 19:24:30
cc @chiehg0v
mrorz
2020-02-04 21:26:42
印這個算嗎
bess
19:24:30
cc @chiehg0v

tmonk
22:04:37
洗手七式很有幫助,在醫院也很常看到。
Dawn
23:05:34
@me1614 has joined the channel
AlcHawk
23:51:37
@alchawk has joined the channel
2020-02-05
Gary
10:01:30
@ma.gary729 has joined the channel
turtalk
11:22:30
@turtalk has joined the channel
Angel Lee
14:06:22
@fangyulee0102 has joined the channel
mrorz
16:52:26

bil
20:13:07
嗨嗨有台南小松的朋友嗎
delightfullychaotic
20:17:11
那邊有朋友
bil
20:17:59
感謝感謝
kuro
20:18:56
@kuro has joined the channel
delightfullychaotic
20:34:34
規範問題II
```- 提供更好的服務之目的,本團隊得將部分用戶資訊再授權與第三方專業聊天機器人資料分析團隊,以了解用戶的背景與喜好,並對本服務進行修正,以求更符合用戶需求。
- 本團隊將嚴格要求合作之第三方專業聊天機器人資料分析團隊恪守尊重用戶隱私權與隱私法規之規定,並確保用戶資訊不外流。
- 若用戶對本服務產生疑慮,得聯繫本團隊要求刪除、修改其在本服務或合作之第三方專業聊天機器人資料分析團隊中的用戶資料。```
```- 提供更好的服務之目的,本團隊得將部分用戶資訊再授權與第三方專業聊天機器人資料分析團隊,以了解用戶的背景與喜好,並對本服務進行修正,以求更符合用戶需求。
- 本團隊將嚴格要求合作之第三方專業聊天機器人資料分析團隊恪守尊重用戶隱私權與隱私法規之規定,並確保用戶資訊不外流。
- 若用戶對本服務產生疑慮,得聯繫本團隊要求刪除、修改其在本服務或合作之第三方專業聊天機器人資料分析團隊中的用戶資料。```
delightfullychaotic
20:35:08
這些應該不用了
delightfullychaotic
20:35:13
確認一下
bil
20:45:04
在說botimizer媽,是的是的
delightfullychaotic
20:46:13
我想要確認一下 我們現在刪掉 Chatbot 使用者的常見原因有哪些?
bil
20:49:23
咦咦什麼刪掉使用者?是指把發送訊息這個功能鎖起來嗎?
delightfullychaotic
21:04:02
對
delightfullychaotic
21:04:22
其實我也想要這件事情如何發生
bil
21:07:56
會先把行為模式留下紀錄(例如大量放送沒有道理的亂碼、機器人攻擊),放在facebook編輯公開社團和slack公開,然後鎖權限。
delightfullychaotic
22:31:39
後來發現要改的比我想像的少,很多其實當初都有寫,只是我們都忘了(包括我)
```Chatbot使用規範
https://docs.google.com/document/d/1-SHWpV8NBI5u79dhvJUjkDaCfBJ0cYxwXoV4sIxPzOo/edit#
編輯使用規範
https://docs.google.com/document/d/1hyoC9xEeKqvaKN5ahfyczUZCs2-j1a9mkg3qHQDcfK0/edit#```
```Chatbot使用規範
https://docs.google.com/document/d/1-SHWpV8NBI5u79dhvJUjkDaCfBJ0cYxwXoV4sIxPzOo/edit#
編輯使用規範
https://docs.google.com/document/d/1hyoC9xEeKqvaKN5ahfyczUZCs2-j1a9mkg3qHQDcfK0/edit#```
- 🙏1
- 🙌1
youz
22:35:35
@chenyuzu1221 has joined the channel
lucien
22:53:56

mrorz
2020-02-13 12:12:49
@lucien 我把探索 elasticsearch query 可能性的研究放進 hackmd 囉。
因為 Elasticsearch 的限制,其實我們無法在 query 的時候 (包含 sort by script, scripted field, scripted score 等等 context),去存取 `articleReplies` 裡的 nested object。硬去存取 `doc['articleReplies']` 只會造成 `No field found for [articleReplies] in mapping with types []` 這個 error。
> Ref: https://discuss.elastic.co/t/help-for-painless-iterate-nested-fields/162394/2
不過,用最新 `articleReply` 排序文章是完全沒有問題的,請見 hackmd 裡頭的 query 與 search result。
我在「複查」的現況是,會點開 https://cofacts.g0v.tw/articles?filter=solved 這個文章列表,但不足的地方是,他的排序是按照「文章被問的時間」而不是回應被加的時間,導致我不知道要看到哪一文章才算是「看完所有的新回應」;另外,我也要點開進去才能看到回應,很不方便。
因此,我覺得結合下面這些功能,對我來說就很有「需複查列表」的感覺:
• 現有的「已回覆文章列表」
• 預設用「最新回覆時間」排序(現有的 sort dropdown 新增排序選項)
• 同時在列表呈現訊息與最新回覆內文(新外觀)
以上是我的研究結果以及分享我的使用 scenario。我覺得定義「需要複查的訊息」的討論應該可以塵埃落定了,現在比較急迫的可能是如何在 UI 上達成「同時在列表呈現訊息與最新回覆內文」。
因為 Elasticsearch 的限制,其實我們無法在 query 的時候 (包含 sort by script, scripted field, scripted score 等等 context),去存取 `articleReplies` 裡的 nested object。硬去存取 `doc['articleReplies']` 只會造成 `No field found for [articleReplies] in mapping with types []` 這個 error。
> Ref: https://discuss.elastic.co/t/help-for-painless-iterate-nested-fields/162394/2
不過,用最新 `articleReply` 排序文章是完全沒有問題的,請見 hackmd 裡頭的 query 與 search result。
我在「複查」的現況是,會點開 https://cofacts.g0v.tw/articles?filter=solved 這個文章列表,但不足的地方是,他的排序是按照「文章被問的時間」而不是回應被加的時間,導致我不知道要看到哪一文章才算是「看完所有的新回應」;另外,我也要點開進去才能看到回應,很不方便。
因此,我覺得結合下面這些功能,對我來說就很有「需複查列表」的感覺:
• 現有的「已回覆文章列表」
• 預設用「最新回覆時間」排序(現有的 sort dropdown 新增排序選項)
• 同時在列表呈現訊息與最新回覆內文(新外觀)
以上是我的研究結果以及分享我的使用 scenario。我覺得定義「需要複查的訊息」的討論應該可以塵埃落定了,現在比較急迫的可能是如何在 UI 上達成「同時在列表呈現訊息與最新回覆內文」。
yajc44
2020-02-13 13:28:06
如果把現在的列表轉換成card對網頁
yajc44
2020-02-13 13:28:15
的loading會很大嗎?
yajc44
2020-02-13 13:30:08
假設說在列表夠明顯展示訊息、目前的判定(是否含有不實)、最新的回覆摘要,是否能解你現在的問題?
lucien
2020-02-13 13:31:05
我們會有獨立的頁面做文章及需複查的回覆聚合設計
yajc44
2020-02-13 13:32:22
原來如此
lucien
2020-02-13 13:33:35
卡片是可以考慮的,感謝分享
mrorz
2020-02-17 14:00:53
@lucien :所以如果 @yanglin5689446 這個禮拜要實作,請問應該會是獨立頁面,還是我說的那種「現有列表、新排序方式」呢?
2020-02-06
CTWu
08:12:44
@neilctwu has joined the channel
foxfirejack
08:54:08
@foxfirejack has joined the channel
yanglin
09:50:00
@yanglin5689446 has joined the channel
JerryLin
13:59:04
@kc50047 has joined the channel
koko5823
17:01:06
@zzxxcc921012 has joined the channel
ash
20:20:28
@ashleyhsieh328 has joined the channel
wuulong
20:42:32
@wuulong has joined the channel
2020-02-07
reio
01:01:36
@reiokai has joined the channel
TANGCHENGLEE
01:03:14
@virgil246 has joined the channel
AlfieYFC
05:02:07
@alfieyfc has joined the channel
frank
09:15:29
@pacoou has joined the channel
cybai
09:42:05
@cyb.ai.815 has joined the channel
Jacky
09:47:12
@jong.shianns has joined the channel
FunnyQ
14:07:05
@funnyq has joined the channel
leira322
18:00:35
@leira322 has joined the channel
bil
19:21:59
嗨嗨嗨大家,cofacts明天有編輯小聚唷,還有本專案隨時都需要寫react.js和node.js的工程師還有公民查核十方大德,感謝大家加入這個頻道◉‿◉
- 👍1
yanglin
2020-02-07 19:49:25
幾點哇
我可以去嗎?
我可以去嗎?
下午2點唷來來來
yanglin
2020-02-07 21:12:30
兩點我可能有一點點緊繃 Q___Q
我以為傍晚 Q___Q
我以為傍晚 Q___Q
JustinLee
2020-02-07 21:40:52
人不能到,但 node.js 跟 line bot 可以幫忙唷 XDD
好唷好唷下次見xD
遠方的工程師(狂揮手)
遠方的工程師(狂揮手)
yanglin
19:49:25
幾點哇
我可以去嗎?
我可以去嗎?
mrorz
20:11:54
cofacts.kktix.cc
2 個月一次,用一個下午的時間與 Cofacts 一起工作闢謠解惑,讓不同意見突破同溫層。 來編輯小聚就送限量 Cofacts 貼紙。回應超過200篇,送委外設計的LINE貼圖!
bil
21:11:44
下午2點唷來來來
yanglin
21:12:30
兩點我可能有一點點緊繃 Q___Q
我以為傍晚 Q___Q
我以為傍晚 Q___Q
JustinLee
21:40:52
人不能到,但 node.js 跟 line bot 可以幫忙唷 XDD
2020-02-08
cai
09:04:43
@iacmai has joined the channel

tumi
15:01:52
拍謝有好心人可幫開門嗎⋯⋯?
tumi
15:02:00
@1樓
ronnywang
15:03:20
我幫妳開

astroerin0407
17:12:32
@astroerin0407 has joined the channel
2020-02-10
John Huang
14:31:30
@little78926 has joined the channel
Yung
18:24:48
@yangchiyung12 has joined the channel
yanglin
18:43:44
想問一下
我在裝 `rumors-api` 環境跑 `npm install` 的時候
用 `node v13.5` 會 build fail
fail 原因是 grpc build 不起來
後來切換成 `node v10.6` 之後 build 完了
但是 `docker-compose up` 的時候會一直噴 error:
```Error: Failed to load gRPC binary module because it was not installed for the current system
Found: [node-v64-darwin-x64-unknown]
Expected directory: node-v72-linux-x64-glibc
This problem can often be fixed by running "npm rebuild" on the current system```
我想原因應該是我在外面 npm install 時會裝 osx 版本的 glibc
但是 container 吃 linux 版的
想問一下有沒有人遇過類似的狀況
我在裝 `rumors-api` 環境跑 `npm install` 的時候
用 `node v13.5` 會 build fail
fail 原因是 grpc build 不起來
後來切換成 `node v10.6` 之後 build 完了
但是 `docker-compose up` 的時候會一直噴 error:
```Error: Failed to load gRPC binary module because it was not installed for the current system
Found: [node-v64-darwin-x64-unknown]
Expected directory: node-v72-linux-x64-glibc
This problem can often be fixed by running "npm rebuild" on the current system```
我想原因應該是我在外面 npm install 時會裝 osx 版本的 glibc
但是 container 吃 linux 版的
想問一下有沒有人遇過類似的狀況
- 🦒1
 1
1
mrorz
21:09:31
This PR updates README and docker-compose.yml so that it can docker-compose up without problem. cc/ @yanglin5689446 currently if you docker-compose up you may encounter error about gRPC binaries. T...
yanglin
2020-02-10 22:17:00
喔喔感謝你~
mrorz
2020-02-11 11:17:59
會 work 的話可以來個 approve XD
yanglin
2020-02-11 11:18:19
好的
我等等看
我等等看
mrorz
2020-02-11 11:18:44
幫我按個喜歡
或者是按小喇叭訂閱 (?
或者是按小喇叭訂閱 (?
yanglin
2020-02-11 13:11:57
我切到這 branch 刪除 node_modules 重裝之後跑起來了
但是 localhost:3000 或 localhost:5000 還是拒絕連線
是 docker 還需要什麼設定嗎?
抱歉跟 docker 不太熟
但是 localhost:3000 或 localhost:5000 還是拒絕連線
是 docker 還需要什麼設定嗎?
抱歉跟 docker 不太熟
yanglin
2020-02-11 13:13:19
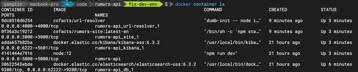
`docker container ls` 之後的結果
yanglin
2020-02-11 13:53:44
懂了
mapping 到 docker-machine 的 ip
mapping 到 docker-machine 的 ip
mrorz
2020-02-11 16:45:18
Hmm 如果你用的是 docker for mac 的話,理論上 localhost:3000 或 localhost:5000 應該要有東西捏
yanglin
2020-02-11 16:45:50
我用 docker-machine
host 在 virtual box vm 上 XD
host 在 virtual box vm 上 XD
yanglin
2020-02-11 16:45:53
要從 host 連
mrorz
2020-02-11 16:46:54
真 hardcore
yanglin
22:17:00
喔喔感謝你~
2020-02-11
Derek T
09:55:46
@derek_tzeng has joined the channel
mrorz
11:17:59
會 work 的話可以來個 approve XD
yanglin
11:18:19
好的
我等等看
我等等看
mrorz
13:07:56
@yanglin5689446 @lucien 我這個禮拜也是三四會在 Workis 唷
- 👍4
mrorz
2020-02-11 16:45:45
明天 11am 開始會在 Workis
yanglin
2020-02-12 14:20:45
hi hi 我明天再去 workis 跟你 sync
因為我發現明天晚上有活動 又我的口罩存量堪慮
想減少搭捷運的次數 XD
你明天下午會在 workis 嗎?
因為我發現明天晚上有活動 又我的口罩存量堪慮
想減少搭捷運的次數 XD
你明天下午會在 workis 嗎?
mrorz
2020-02-12 14:49:15
會唷
mrorz
2020-02-12 14:50:53
btw 疾管署針對捷運要不要戴口罩是這樣說
https://www.mohw.gov.tw/cp-4343-51410-1.html
https://www.mohw.gov.tw/cp-4343-51410-1.html
yanglin
2020-02-12 14:55:12
我大概知道
但是捷運搭比較久還是有點怕 ><
而且我同學說他感冒反而買不到口罩
還是會有點擔心會不會有人不健康(不一定是肺炎)在捷運上然後沒口罩可用之類的
總之我的想法就是盡量少出門然後搭捷運還是帶一下這樣
但是捷運搭比較久還是有點怕 ><
而且我同學說他感冒反而買不到口罩
還是會有點擔心會不會有人不健康(不一定是肺炎)在捷運上然後沒口罩可用之類的
總之我的想法就是盡量少出門然後搭捷運還是帶一下這樣
yanglin
13:11:57
我切到這 branch 刪除 node_modules 重裝之後跑起來了
但是 localhost:3000 或 localhost:5000 還是拒絕連線
是 docker 還需要什麼設定嗎?
抱歉跟 docker 不太熟
但是 localhost:3000 或 localhost:5000 還是拒絕連線
是 docker 還需要什麼設定嗎?
抱歉跟 docker 不太熟
yanglin
13:53:44
懂了
mapping 到 docker-machine 的 ip
mapping 到 docker-machine 的 ip
mrorz
16:42:34
好哇明天
因為他很大 QQ
因為他很大 QQ
mrorz
16:43:15
我會建議你直接用 GraphQL playground 呼叫 CreateArticle API 塞幾個 seed data 進去
- 👌1
yanglin
2020-02-11 16:46:30
我試試
不行的話可能明天去看看
不行的話可能明天去看看
mrorz
16:45:18
Hmm 如果你用的是 docker for mac 的話,理論上 localhost:3000 或 localhost:5000 應該要有東西捏
mrorz
16:45:45
明天 11am 開始會在 Workis
yanglin
16:45:50
我用 docker-machine
host 在 virtual box vm 上 XD
host 在 virtual box vm 上 XD
yanglin
16:45:53
要從 host 連
yanglin
16:46:30
我試試
不行的話可能明天去看看
不行的話可能明天去看看
mrorz
16:46:54
真 hardcore
2020-02-12
mrorz
12:51:28
yanglin
14:45:06
https://beta.hackfoldr.org/1yXwRJwFNFHNJibKENnLCAV5xB8jnUvEwY_oUq-KcETU/https%253A%252F%252Fhackmd.io%252Fs%252FBkxbQ8ZbM
想問下這份 mapping 圖是 up to date 的嗎?
想問下這份 mapping 圖是 up to date 的嗎?
mrorz
2020-02-12 14:45:25
almost (?)
mrorz
2020-02-12 14:45:54
可能缺一兩個 field 但 index 之間的關係是對的
mrorz
2020-02-12 14:48:37
例如說 `articlereplyfeedbacks` 其實應該有 `articleId` 與 `replyId` 兩個欄位
https://github.com/cofacts/rumors-db/blob/master/schema/articlereplyfeedbacks.js
但忘記為什麼沒畫出來
https://github.com/cofacts/rumors-db/blob/master/schema/articlereplyfeedbacks.js
但忘記為什麼沒畫出來
mrorz
14:45:54
可能缺一兩個 field 但 index 之間的關係是對的
mrorz
14:48:37
例如說 `articlereplyfeedbacks` 其實應該有 `articleId` 與 `replyId` 兩個欄位
https://github.com/cofacts/rumors-db/blob/master/schema/articlereplyfeedbacks.js
但忘記為什麼沒畫出來
https://github.com/cofacts/rumors-db/blob/master/schema/articlereplyfeedbacks.js
但忘記為什麼沒畫出來
Scripts for managing rumors db. Contribute to cofacts/rumors-db development by creating an account on GitHub.
mrorz
14:49:15
會唷
yanglin
14:55:12
我大概知道
但是捷運搭比較久還是有點怕 ><
而且我同學說他感冒反而買不到口罩
還是會有點擔心會不會有人不健康(不一定是肺炎)在捷運上然後沒口罩可用之類的
總之我的想法就是盡量少出門然後搭捷運還是帶一下這樣
但是捷運搭比較久還是有點怕 ><
而且我同學說他感冒反而買不到口罩
還是會有點擔心會不會有人不健康(不一定是肺炎)在捷運上然後沒口罩可用之類的
總之我的想法就是盡量少出門然後搭捷運還是帶一下這樣
- 👌1
ael
19:42:56
@bil @mrorz Disfactory 正在參考你們的 landing page https://cofacts.g0v.tw/,最下面的按鈕「我想學用真的假的」連到英文 toolkit 是正常的嗎?
bil
19:54:45
是XDD那是之前特別手動改過的
mrorz
20:06:40
啊 忘記改回來wwwwww
2020-02-13
Norman
03:32:31
@normanlin.net has joined the channel
mrorz
12:12:49
Replied to a thread: 2020-02-05 22:53:56
@lucien 我把探索 elasticsearch query 可能性的研究放進 hackmd 囉。
因為 Elasticsearch 的限制,其實我們無法在 query 的時候 (包含 sort by script, scripted field, scripted score 等等 context),去存取 `articleReplies` 裡的 nested object。硬去存取 `doc['articleReplies']` 只會造成 `No field found for [articleReplies] in mapping with types []` 這個 error。
> Ref: https://discuss.elastic.co/t/help-for-painless-iterate-nested-fields/162394/2
不過,用最新 `articleReply` 排序文章是完全沒有問題的,請見 hackmd 裡頭的 query 與 search result。
我在「複查」的現況是,會點開 https://cofacts.g0v.tw/articles?filter=solved 這個文章列表,但不足的地方是,他的排序是按照「文章被問的時間」而不是回應被加的時間,導致我不知道要看到哪一文章才算是「看完所有的新回應」;另外,我也要點開進去才能看到回應,很不方便。
因此,我覺得結合下面這些功能,對我來說就很有「需複查列表」的感覺:
• 現有的「已回覆文章列表」
• 預設用「最新回覆時間」排序(現有的 sort dropdown 新增排序選項)
• 同時在列表呈現訊息與最新回覆內文(新外觀)
以上是我的研究結果以及分享我的使用 scenario。我覺得定義「需要複查的訊息」的討論應該可以塵埃落定了,現在比較急迫的可能是如何在 UI 上達成「同時在列表呈現訊息與最新回覆內文」。
因為 Elasticsearch 的限制,其實我們無法在 query 的時候 (包含 sort by script, scripted field, scripted score 等等 context),去存取 `articleReplies` 裡的 nested object。硬去存取 `doc['articleReplies']` 只會造成 `No field found for [articleReplies] in mapping with types []` 這個 error。
> Ref: https://discuss.elastic.co/t/help-for-painless-iterate-nested-fields/162394/2
不過,用最新 `articleReply` 排序文章是完全沒有問題的,請見 hackmd 裡頭的 query 與 search result。
我在「複查」的現況是,會點開 https://cofacts.g0v.tw/articles?filter=solved 這個文章列表,但不足的地方是,他的排序是按照「文章被問的時間」而不是回應被加的時間,導致我不知道要看到哪一文章才算是「看完所有的新回應」;另外,我也要點開進去才能看到回應,很不方便。
因此,我覺得結合下面這些功能,對我來說就很有「需複查列表」的感覺:
• 現有的「已回覆文章列表」
• 預設用「最新回覆時間」排序(現有的 sort dropdown 新增排序選項)
• 同時在列表呈現訊息與最新回覆內文(新外觀)
以上是我的研究結果以及分享我的使用 scenario。我覺得定義「需要複查的訊息」的討論應該可以塵埃落定了,現在比較急迫的可能是如何在 UI 上達成「同時在列表呈現訊息與最新回覆內文」。
- 👍1
Ada
12:25:41
@n2130213 has joined the channel
yajc44
13:28:06
如果把現在的列表轉換成card對網頁
yajc44
13:28:15
的loading會很大嗎?
yajc44
13:30:08
假設說在列表夠明顯展示訊息、目前的判定(是否含有不實)、最新的回覆摘要,是否能解你現在的問題?
lucien
13:31:05
我們會有獨立的頁面做文章及需複查的回覆聚合設計
yajc44
13:32:22
原來如此
lucien
13:33:35
卡片是可以考慮的,感謝分享
stanwu
16:27:20
@stanwu.tw has joined the channel
2020-02-14
Stone Yen
11:18:05
@stone.yen has joined the channel
Yi-Chung Dzeng
12:59:15
@ycdzeng has joined the channel
JunWeiChen
20:04:03
@a58j006 has joined the channel
CodingCoke
23:32:21
@brad61517 has joined the channel
2020-02-15
mrorz
10:14:58
m.ltn.com.tw
武漢肺炎疫情慘烈,最初的吹哨者李文亮醫師不幸染病逝世,網路近日瘋傳一封據傳是李妻子代發的遺書,通篇總計394字;對此,闢謠機器人「Cofacts真的假的」今(8)日指出,文章後半部僅有文字流傳,不能確認是否為真實。最早揭發武漢肺炎的中國醫師李文亮,日前因染疫不治身亡,消息震驚世界;然而,中國網路近日流傳李文亮妻子的「求助書」,李文亮妻子付雪潔已出面闢謠,表示「不接受任何人捐款」後,證實為不實消息。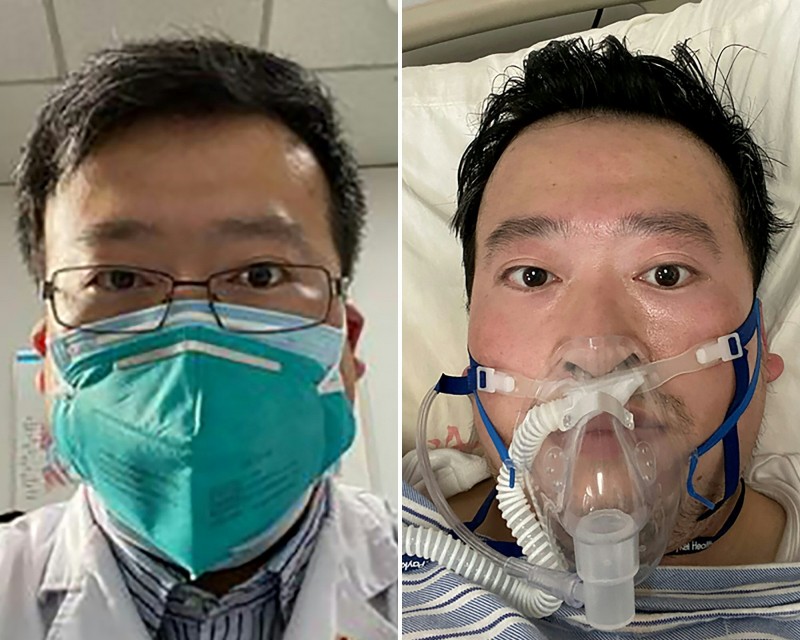
- 😮4
 2
2
rockhung
2020-02-15 10:53:49
推 闢謠機器人指出
mrorz
2020-02-15 12:11:05
只好寫一個回應說自由時報指出(慢著
AlcHawk
2020-02-17 11:09:47
這個編輯室也太混了lol
rockhung
10:53:49
推 闢謠機器人指出
Norman
20:02:49
不知道為什麼 `CopyButton` 的行為在 production 網頁上和 localhost 上不一樣耶,production 在手機上會顯示 native 的分享選項、但另一個不會,localhost 我是用 IP address 在手機上打開的
mrorz
2020-02-15 23:25:06
ohhhh 因為要 https
mrorz
2020-02-15 23:25:28
https://developer.mozilla.org/en-US/docs/Web/API/Navigator/share
> This feature is available only in secure contexts (HTTPS), in some or all supporting browsers.
> This feature is available only in secure contexts (HTTPS), in some or all supporting browsers.
mrorz
2020-02-15 23:28:28
Norman
2020-02-16 00:45:18
原來如此,感謝!
mrorz
23:25:06
ohhhh 因為要 https
mrorz
23:25:28
https://developer.mozilla.org/en-US/docs/Web/API/Navigator/share
> This feature is available only in secure contexts (HTTPS), in some or all supporting browsers.
> This feature is available only in secure contexts (HTTPS), in some or all supporting browsers.
MDN Web Docs
The navigator.share() method of the Web Share API invokes the native sharing mechanism of the device.
mrorz
23:28:28
ngrok.com
ngrok secure introspectable tunnels to localhost webhook development tool and debugging tool
2020-02-16
2020-02-17
AlcHawk
11:09:47
這個編輯室也太混了lol
mrorz
13:36:36
Category API 上 staging ( https://cofacts-api.hacktabl.org/ ) 囉
Detail: https://github.com/cofacts/rumors-api/issues/142
Detail: https://github.com/cofacts/rumors-api/issues/142
完成 Cofacts crowd-source label mechanism API mock (for 訊息列表 label 過濾器、訊息頁面 crowd-source label 標記與回饋機制) 與 AI module 對接 AI 自動分類與 confidence level,在新文章送入時(CreateArticle API),取得 AI 自動分類,加進文章中。 (Not mock...
yanglin
13:55:00
@mrorz
所以如果按照 https://hackmd.io/dfAkGHLCShacnOoruGxr0w 第一種設計的話
是對 article 下 query
然後把關聯的 articleReplies aggregate 起來?
所以如果按照 https://hackmd.io/dfAkGHLCShacnOoruGxr0w 第一種設計的話
是對 article 下 query
然後把關聯的 articleReplies aggregate 起來?
mrorz
2020-02-17 13:58:34
第一種設計在 elasticsearch 層不會使用到 elasticsearch aggregation 功能,elasticsearch aggregation result 也無法用來 filter 與 sort
mrorz
2020-02-17 13:59:33
我只用到 sort within nested field 的功能
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-sort.html#nested-sorting
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-sort.html#nested-sorting
yanglin
2020-02-17 14:03:41
喔我的 aggregate 可能不是一個好的 term XD
但我想表達的意思是
這樣會是從 ListReplies query 裡面去 query articles 然後把關聯的 replies 抽出來嗎?
如果是這樣會不會有點奇怪
因為一般打 request 給 ListReplies 的話應該會想說他後面會打 replies 這個 index
但實作上卻是打 articles 然後透過 articles 關聯取得 replies
但我想表達的意思是
這樣會是從 ListReplies query 裡面去 query articles 然後把關聯的 replies 抽出來嗎?
如果是這樣會不會有點奇怪
因為一般打 request 給 ListReplies 的話應該會想說他後面會打 replies 這個 index
但實作上卻是打 articles 然後透過 articles 關聯取得 replies
mrorz
2020-02-17 14:17:54
不是耶,是打 ListArticles
mrorz
2020-02-17 14:18:50
這也是為什麼我會在 https://g0v-tw.slack.com/archives/C2PPMRQGP/p1581567169085300?thread_ts=1580914436.048200&cid=C2PPMRQGP 裡面建議,實作在現有的「已回覆『文章』列表」
mrorz
2020-02-17 14:19:07
不過
mrorz
2020-02-17 14:19:38
@lucien 可能會想要做成獨立的頁面 (詳細希望)
但即使是獨立頁面,資料也會從 `ListArticles` API 撈就是了
但即使是獨立頁面,資料也會從 `ListArticles` API 撈就是了
yanglin
2020-02-17 14:19:46
喔喔
所以是要列出「有『有需要複查的回應』的文章』?
所以是要列出「有『有需要複查的回應』的文章』?
mrorz
2020-02-17 14:20:03
對
yanglin
2020-02-17 14:20:21
okok
我之前搞錯了
3Q
我之前搞錯了
3Q
yanglin
2020-02-19 16:09:22
@mrorz 我想問一下
用最新的回應的 createdAt 還是 updatedAt 好?
會不會有人編輯了他的回覆內容之類的
用最新的回應的 createdAt 還是 updatedAt 好?
會不會有人編輯了他的回覆內容之類的
mrorz
2020-02-19 16:13:19
目前會動到 updatedAt 的好像是刪除與復原?可能要看一下 api code
我覺得 `createAt` 的好處是不會一直出現在列表上。如果用 updatedAt,可能會發生:
1. A 發了個回應
2. B 開始看待複查列表,讀完了 10 篇回應,與 A 的回應。心裡記著「我上次看到這篇」。
3. C 寫了一篇新的回應。
4. A 修改了自己的回應,此時若為 updatedAt 排序,它會在第一個。
5. B 又回來看待複查列表,在第一個看到 A 的回應,就以為其他都看過了。
我覺得 `createAt` 的好處是不會一直出現在列表上。如果用 updatedAt,可能會發生:
1. A 發了個回應
2. B 開始看待複查列表,讀完了 10 篇回應,與 A 的回應。心裡記著「我上次看到這篇」。
3. C 寫了一篇新的回應。
4. A 修改了自己的回應,此時若為 updatedAt 排序,它會在第一個。
5. B 又回來看待複查列表,在第一個看到 A 的回應,就以為其他都看過了。
mrorz
13:58:34
第一種設計在 elasticsearch 層不會使用到 elasticsearch aggregation 功能,elasticsearch aggregation result 也無法用來 filter 與 sort
mrorz
13:59:33
我只用到 sort within nested field 的功能
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-sort.html#nested-sorting
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-request-sort.html#nested-sorting
mrorz
14:00:53
@lucien :所以如果 @yanglin5689446 這個禮拜要實作,請問應該會是獨立頁面,還是我說的那種「現有列表、新排序方式」呢?
yanglin
14:03:41
喔我的 aggregate 可能不是一個好的 term XD
但我想表達的意思是
這樣會是從 ListReplies query 裡面去 query articles 然後把關聯的 replies 抽出來嗎?
如果是這樣會不會有點奇怪
因為一般打 request 給 ListReplies 的話應該會想說他後面會打 replies 這個 index
但實作上卻是打 articles 然後透過 articles 關聯取得 replies
但我想表達的意思是
這樣會是從 ListReplies query 裡面去 query articles 然後把關聯的 replies 抽出來嗎?
如果是這樣會不會有點奇怪
因為一般打 request 給 ListReplies 的話應該會想說他後面會打 replies 這個 index
但實作上卻是打 articles 然後透過 articles 關聯取得 replies
mrorz
14:18:50
這也是為什麼我會在 https://g0v-tw.slack.com/archives/C2PPMRQGP/p1581567169085300?thread_ts=1580914436.048200&cid=C2PPMRQGP 裡面建議,實作在現有的「已回覆『文章』列表」
Johnson Liang
@lucien 我把探索 elasticsearch query 可能性的研究放進 hackmd 囉。
因為 Elasticsearch 的限制,其實我們無法在 query 的時候 (包含 sort by script, scripted field, scripted score 等等 context),去存取 `articleReplies` 裡的 nested object。硬去存取 `doc['articleReplies']` 只會造成 `No field found for [articleReplies] in mapping with types []` 這個 error。
> Ref: https://discuss.elastic.co/t/help-for-painless-iterate-nested-fields/162394/2
不過,用最新 `articleReply` 排序文章是完全沒有問題的,請見 hackmd 裡頭的 query 與 search result。
我在「複查」的現況是,會點開 https://cofacts.g0v.tw/articles?filter=solved 這個文章列表,但不足的地方是,他的排序是按照「文章被問的時間」而不是回應被加的時間,導致我不知道要看到哪一文章才算是「看完所有的新回應」;另外,我也要點開進去才能看到回應,很不方便。
因此,我覺得結合下面這些功能,對我來說就很有「需複查列表」的感覺:
• 現有的「已回覆文章列表」
• 預設用「最新回覆時間」排序(現有的 sort dropdown 新增排序選項)
• 同時在列表呈現訊息與最新回覆內文(新外觀)
以上是我的研究結果以及分享我的使用 scenario。我覺得定義「需要複查的訊息」的討論應該可以塵埃落定了,現在比較急迫的可能是如何在 UI 上達成「同時在列表呈現訊息與最新回覆內文」。
- Forwarded from #cofacts
- 2020-02-13 12:12:49
mrorz
14:19:07
不過
mrorz
14:19:38
@lucien 可能會想要做成獨立的頁面 (詳細希望)
但即使是獨立頁面,資料也會從 `ListArticles` API 撈就是了
但即使是獨立頁面,資料也會從 `ListArticles` API 撈就是了
yanglin
14:19:46
喔喔
所以是要列出「有『有需要複查的回應』的文章』?
所以是要列出「有『有需要複查的回應』的文章』?
mrorz
14:20:03
對
yanglin
14:20:21
okok
我之前搞錯了
3Q
我之前搞錯了
3Q
lucien
14:30:18
關於頁面我這邊想討論一下
lucien
2020-02-17 15:08:40
Nav 選項想改成
可疑訊息 / Dubious Messages => articleList
最新回覆 / Latest Replies => Need Review article with replies
熱門訊息 / Trend => 暫時 replyRequestCount > n ,之後改 cronjob
我的關注 / Follow ( after login ) => followed articleList
—
討論區 / Forum
關於 / About
可疑訊息 / Dubious Messages => articleList
最新回覆 / Latest Replies => Need Review article with replies
熱門訊息 / Trend => 暫時 replyRequestCount > n ,之後改 cronjob
我的關注 / Follow ( after login ) => followed articleList
—
討論區 / Forum
關於 / About
lucien
2020-02-17 15:09:37
想問:
1. 我現在不確定純粹的 replies list 有什麼意義
2. 中英文命名合適嗎
1. 我現在不確定純粹的 replies list 有什麼意義
2. 中英文命名合適嗎
mrorz
2020-02-17 16:50:16
Reply list --> 用關鍵字找「回應」時可以用
因為在 article list 只能對文章內文搜尋關鍵字~
因為在 article list 只能對文章內文搜尋關鍵字~
lucien
2020-02-17 16:51:30
那如果 search input 有進階的選擇,能搜尋內文跟回應呢
mrorz
2020-02-17 16:51:58
關於中英文命名,我覺得「發現 / Discover」與「眾查 / Review」似乎跟使用習慣不太符合。我覺得字可以不用這麼短 @@
https://fact-checker.line.me/ 用的是「最新話題」、「已查核」
https://tfc-taiwan.org.tw/ 用的是「申訴專區」「事實查核報告」
https://fact-checker.line.me/ 用的是「最新話題」、「已查核」
https://tfc-taiwan.org.tw/ 用的是「申訴專區」「事實查核報告」
mrorz
2020-02-17 16:52:45
Cofactst 的話應該是
「網友回報 / Reported messages」「最新回覆 / Latest replies」之類的吧
「網友回報 / Reported messages」「最新回覆 / Latest replies」之類的吧
mrorz
2020-02-17 16:53:55
> Reply list --> 用關鍵字找「回應」時可以用
> 因為在 article list 只能對文章內文搜尋關鍵字~
雖然說有用處,但我承認他確實是比較進階的用法,可以不用放在 nav,而是收在第二層或比較隱密的地方
> 因為在 article list 只能對文章內文搜尋關鍵字~
雖然說有用處,但我承認他確實是比較進階的用法,可以不用放在 nav,而是收在第二層或比較隱密的地方
lucien
2020-02-17 16:54:20
回報訊息 / 回報謠言
謠言這字雖然很有主觀性,但我覺得給新手遊客比較好理解
謠言這字雖然很有主觀性,但我覺得給新手遊客比較好理解
mrorz
2020-02-17 16:54:37
「可疑訊息」呢
lucien
2020-02-17 16:55:26
可疑訊息 / Suspicious messages ?
lucien
2020-02-17 16:55:41
我們之前首頁是 hoax
mrorz
2020-02-17 16:56:05
mrorz
2020-02-17 16:58:58
長度的部分老實講
都要做 i18n 惹,字數長短不一這點應該不可避
都要做 i18n 惹,字數長短不一這點應該不可避
mrorz
2020-02-17 16:59:39
> 關注 / Follow ( after login ) => followed articleList
這是「我回應過的訊息」嗎?
這是「我回應過的訊息」嗎?
lucien
2020-02-17 17:00:00
可疑訊息,我覺得對新手比較好理解
lucien
2020-02-17 17:00:32
Follow 是之後的我也想知道
lucien
2020-02-17 17:00:33
也可以加上我回應過的
mrorz
2020-02-17 17:00:53
如果編輯可以送出 replyrequest 的話
那也可以放在那裡頭
那也可以放在那裡頭
mrorz
2020-02-17 17:01:08
呼應很久以前想過的 filter
https://github.com/cofacts/rumors-api/issues/35
https://github.com/cofacts/rumors-api/issues/35
lucien
2020-02-17 17:02:31
yep
lucien
2020-02-17 17:02:32
我想加一欄熱門,但是目前技術資源好像不夠開發
lucien
2020-02-17 17:02:33
得做一個 cronjob 是跑一個 queue
mrorz
2020-02-17 17:17:39
對,「熱門」等於要把 google analytics 每日數據,透過 Google analytics reporting API 倒回我們自己的資料庫處理
lucien
2020-02-17 17:18:32
熱門先放 backlog 吧
mrorz
2020-02-17 17:19:03
可以先用 `replyRequestCount` 訂熱門度
mrorz
2020-02-17 17:19:17
雖然有人回過就會停惹
lucien
2020-02-17 17:20:55
有人回過就會停惹 => 什麼意思
lucien
2020-02-17 17:21:06
是不會增長但是數字還在呀
mrorz
2020-02-17 17:21:17
嗯,就是不增長但數字還在
mrorz
2020-02-17 17:22:38
若支援編輯在網站上送 reply request 就會有機會增長,但應該不會太多 (issue https://github.com/cofacts/rumors-site/issues/13 )
lucien
2020-02-17 17:50:32
@stbb1025
stbb1025
2020-02-17 17:51:41
🤘🤘🤘
lucien
14:30:58
@yanglin5689446 你有我們 figma 的帳號嗎?我昨天在弄有一些初步想法了,之後會出一份更完整的 spec 給你
yanglin
14:31:34
還沒有窩
lucien
14:32:11
lucien
15:08:40
Replied to a thread: 2020-02-17 14:30:18
Nav 選項想改成
可疑訊息 / Dubious Messages => articleList
最新回覆 / Latest Replies => Need Review article with replies
熱門訊息 / Trend => 暫時 replyRequestCount > n ,之後改 cronjob
我的關注 / Follow ( after login ) => followed articleList
—
討論區 / Forum
關於 / About
可疑訊息 / Dubious Messages => articleList
最新回覆 / Latest Replies => Need Review article with replies
熱門訊息 / Trend => 暫時 replyRequestCount > n ,之後改 cronjob
我的關注 / Follow ( after login ) => followed articleList
—
討論區 / Forum
關於 / About
lucien
15:09:37
想問:
1. 我現在不確定純粹的 replies list 有什麼意義
2. 中英文命名合適嗎
1. 我現在不確定純粹的 replies list 有什麼意義
2. 中英文命名合適嗎
mrorz
16:50:16
Reply list --> 用關鍵字找「回應」時可以用
因為在 article list 只能對文章內文搜尋關鍵字~
因為在 article list 只能對文章內文搜尋關鍵字~
lucien
16:51:30
那如果 search input 有進階的選擇,能搜尋內文跟回應呢
mrorz
16:51:58
關於中英文命名,我覺得「發現 / Discover」與「眾查 / Review」似乎跟使用習慣不太符合。我覺得字可以不用這麼短 @@
https://fact-checker.line.me/ 用的是「最新話題」、「已查核」
https://tfc-taiwan.org.tw/ 用的是「申訴專區」「事實查核報告」
https://fact-checker.line.me/ 用的是「最新話題」、「已查核」
https://tfc-taiwan.org.tw/ 用的是「申訴專區」「事實查核報告」
mrorz
16:52:45
Cofactst 的話應該是
「網友回報 / Reported messages」「最新回覆 / Latest replies」之類的吧
「網友回報 / Reported messages」「最新回覆 / Latest replies」之類的吧
mrorz
16:53:55
> Reply list --> 用關鍵字找「回應」時可以用
> 因為在 article list 只能對文章內文搜尋關鍵字~
雖然說有用處,但我承認他確實是比較進階的用法,可以不用放在 nav,而是收在第二層或比較隱密的地方
> 因為在 article list 只能對文章內文搜尋關鍵字~
雖然說有用處,但我承認他確實是比較進階的用法,可以不用放在 nav,而是收在第二層或比較隱密的地方
lucien
16:54:20
回報訊息 / 回報謠言
謠言這字雖然很有主觀性,但我覺得給新手遊客比較好理解
謠言這字雖然很有主觀性,但我覺得給新手遊客比較好理解
mrorz
16:54:37
「可疑訊息」呢
lucien
16:55:26
可疑訊息 / Suspicious messages ?
lucien
16:55:41
我們之前首頁是 hoax
mrorz
16:56:05
mrorz
16:58:58
長度的部分老實講
都要做 i18n 惹,字數長短不一這點應該不可避
都要做 i18n 惹,字數長短不一這點應該不可避
mrorz
16:59:39
> 關注 / Follow ( after login ) => followed articleList
這是「我回應過的訊息」嗎?
這是「我回應過的訊息」嗎?
lucien
17:00:32
Follow 是之後的我也想知道
lucien
17:00:33
也可以加上我回應過的
mrorz
17:00:53
如果編輯可以送出 replyrequest 的話
那也可以放在那裡頭
那也可以放在那裡頭
mrorz
17:01:08
呼應很久以前想過的 filter
https://github.com/cofacts/rumors-api/issues/35
https://github.com/cofacts/rumors-api/issues/35
讓使用者可以使用下面的 filter: 我標記成「等等回應」的文章( #34 ) 沒人標記成「等等回應」的所有文章( #34 ) 文章 tag ( #32 ) 我回應過的 article 我送出過 replyRequest 的 article (我想知道)( Related: cofacts/rumors-site#13 ) 所有人都認為現有 reply 沒用的 article / 照無用度...
lucien
17:02:31
yep
lucien
17:02:32
我想加一欄熱門,但是目前技術資源好像不夠開發
lucien
17:02:33
得做一個 cronjob 是跑一個 queue
mrorz
17:17:39
對,「熱門」等於要把 google analytics 每日數據,透過 Google analytics reporting API 倒回我們自己的資料庫處理
lucien
17:18:32
熱門先放 backlog 吧
mrorz
17:19:03
可以先用 `replyRequestCount` 訂熱門度
mrorz
17:19:17
雖然有人回過就會停惹
lucien
17:20:55
有人回過就會停惹 => 什麼意思
lucien
17:21:06
是不會增長但是數字還在呀
mrorz
17:21:17
嗯,就是不增長但數字還在
mrorz
17:22:38
若支援編輯在網站上送 reply request 就會有機會增長,但應該不會太多 (issue https://github.com/cofacts/rumors-site/issues/13 )
需要登入。 讓網站使用者也能送出 replyRequest。 按鈕位置: 點按過後: copy: <p>請告訴其他編輯:<strong>您為何覺得這是一則謠言</strong>?</p> <textarea placeholder=&quot;例:我用 OO 關鍵字查詢 Facebook,發現⋯⋯ / 我在 XX 官網上找到不一樣的說法如...
lucien
17:50:32
@stbb1025
stbb1025
17:51:41
🤘🤘🤘
quietcool.wu
19:19:27
@quietcool.wu has joined the channel
2020-02-18
RandleHSIAO
09:26:35
@496e0094 has joined the channel
mrorz
13:57:32
新報表:Github Activities
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/WSQFB
感謝 @normanlin.net 本週的兩個 PR 👏 👏
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/WSQFB
感謝 @normanlin.net 本週的兩個 PR 👏 👏
Google Data Studio
Google Data Studio turns your data into informative dashboards and reports that are easy to read, easy to share, and fully customizable.
- 🙂2
- 1
mrorz
2020-02-18 14:25:46
Btw 這次的表用的是
https://github.com/googledatastudio/community-connectors/tree/master/github
Google apps script 真的猛,免費 callback server
https://github.com/googledatastudio/community-connectors/tree/master/github
Google apps script 真的猛,免費 callback server
感謝@Norman!!!!!
mrorz
14:25:46
Btw 這次的表用的是
https://github.com/googledatastudio/community-connectors/tree/master/github
Google apps script 真的猛,免費 callback server
https://github.com/googledatastudio/community-connectors/tree/master/github
Google apps script 真的猛,免費 callback server
This repository contains open source content for Google Data Studio. - googledatastudio/community-connectors
- 💯1
bil
16:02:08
感謝感謝🙏
bil
17:39:53
Cofacts NEXT期間,會以實際的回饋獎勵感謝貢獻者。如果是回應篇數達到400篇以上的朋友們,將會符合查核獎勵的評選資格,在NEXT專案計畫結束前,會由之前公開招募時遴選的Moderator編審選出優良的文章給予獎勵。
此外查核超過200篇的LINE貼圖贈送也持續進行中。
多多累積陰德值,希望讓大家知道,你過去默默的貢獻,都可能有一天在未來帶給你實質的回饋。這一次的計畫以「400篇查核經驗」作為門檻,希望能與專案的貢獻者有更密切的合作。
如果之後Cofacts還有其他類似的獎勵機會,也會優先聯絡社群貢獻者,希望大家多多貢獻。(不只是Cofacts社群)你們的努力不會白費=D
獎勵機會也歸因於曾經的g0v公民科技獎助金與jothon的陪伴與創造活動場域。鼓勵捐款給jothon,讓更多有趣又美好的專案誕生與長大。
此外查核超過200篇的LINE貼圖贈送也持續進行中。
多多累積陰德值,希望讓大家知道,你過去默默的貢獻,都可能有一天在未來帶給你實質的回饋。這一次的計畫以「400篇查核經驗」作為門檻,希望能與專案的貢獻者有更密切的合作。
如果之後Cofacts還有其他類似的獎勵機會,也會優先聯絡社群貢獻者,希望大家多多貢獻。(不只是Cofacts社群)你們的努力不會白費=D
獎勵機會也歸因於曾經的g0v公民科技獎助金與jothon的陪伴與創造活動場域。鼓勵捐款給jothon,讓更多有趣又美好的專案誕生與長大。
- 🐳6
- 👏5
 2
2
allenlinli
2020-02-18 23:18:25
外行路人經過問一下… 不知道「讚賞幣」若是用在 Cofact 的回應文章會不會有幫助?
我剛查到 LikeCoin 是可以客製化放在網頁的
https://stationery.raypuppy.com/2019/01/08/2755/
不好意思冒昧路過建議了…
我剛查到 LikeCoin 是可以客製化放在網頁的
https://stationery.raypuppy.com/2019/01/08/2755/
不好意思冒昧路過建議了…
其實有跟拍拍手聊聊天過唷XDDDD
Norman
2020-02-19 01:17:57
NEXT 是什麼的期間呀?
到11月唷!
lucien
2020-02-19 02:53:08
likecoin 去年已經有密切跟對方討論過了呢,實際整合會比一般部落格複雜許多,因為我們是闢謠回應被讚賞,被贊渠道有可能是從 chatbot 匿名來,因此會需要深度整合。
allenlinli
23:18:25
外行路人經過問一下… 不知道「讚賞幣」若是用在 Cofact 的回應文章會不會有幫助?
我剛查到 LikeCoin 是可以客製化放在網頁的
https://stationery.raypuppy.com/2019/01/08/2755/
不好意思冒昧路過建議了…
我剛查到 LikeCoin 是可以客製化放在網頁的
https://stationery.raypuppy.com/2019/01/08/2755/
不好意思冒昧路過建議了…
2020-02-19
Norman
01:17:57
NEXT 是什麼的期間呀?
bil
01:33:14
到11月唷!
lucien
02:53:08
likecoin 去年已經有密切跟對方討論過了呢,實際整合會比一般部落格複雜許多,因為我們是闢謠回應被讚賞,被贊渠道有可能是從 chatbot 匿名來,因此會需要深度整合。
- 🙌1
winnychen
10:43:33
@sc85803 has joined the channel
yanglin
11:41:05
@mrorz 下午會在 workis 嗎?
mrorz
2020-02-19 11:41:19
今天跟週五都會在唷
我們今天都在喔來來
yanglin
2020-02-19 15:32:56
我還是禮拜五再去好了😅
早上遠端面試完心累睡回籠覺到剛剛 😂😂
早上遠端面試完心累睡回籠覺到剛剛 😂😂
好唷平安平安
bil
11:46:30
我們今天都在喔來來
mrorz
13:11:44
yanglin
15:32:56
我還是禮拜五再去好了😅
早上遠端面試完心累睡回籠覺到剛剛 😂😂
早上遠端面試完心累睡回籠覺到剛剛 😂😂
yanglin
16:09:22
@mrorz 我想問一下
用最新的回應的 createdAt 還是 updatedAt 好?
會不會有人編輯了他的回覆內容之類的
用最新的回應的 createdAt 還是 updatedAt 好?
會不會有人編輯了他的回覆內容之類的
mrorz
16:13:19
目前會動到 updatedAt 的好像是刪除與復原?可能要看一下 api code
我覺得 `createAt` 的好處是不會一直出現在列表上。如果用 updatedAt,可能會發生:
1. A 發了個回應
2. B 開始看待複查列表,讀完了 10 篇回應,與 A 的回應。心裡記著「我上次看到這篇」。
3. C 寫了一篇新的回應。
4. A 修改了自己的回應,此時若為 updatedAt 排序,它會在第一個。
5. B 又回來看待複查列表,在第一個看到 A 的回應,就以為其他都看過了。
我覺得 `createAt` 的好處是不會一直出現在列表上。如果用 updatedAt,可能會發生:
1. A 發了個回應
2. B 開始看待複查列表,讀完了 10 篇回應,與 A 的回應。心裡記著「我上次看到這篇」。
3. C 寫了一篇新的回應。
4. A 修改了自己的回應,此時若為 updatedAt 排序,它會在第一個。
5. B 又回來看待複查列表,在第一個看到 A 的回應,就以為其他都看過了。
- 👌1
bil
16:34:10
好唷平安平安
yanglin
17:29:43
問一下
我現在 clone rumors-site 跑 `npm run dev` 之後
改動程式碼好像沒有 rebuild
重新整理頁面也沒有
需要做什麼額外設置嗎?
我現在 clone rumors-site 跑 `npm run dev` 之後
改動程式碼好像沒有 rebuild
重新整理頁面也沒有
需要做什麼額外設置嗎?
mrorz
2020-02-19 17:51:39
應該不用的呀 @@
mrorz
2020-02-19 17:52:42
不過他應該不是改每個東西都會 rebuild,例如說 static file
但 react component 那些他應該要會
但 react component 那些他應該要會
yanglin
2020-02-19 19:06:09
好
我發現是我耍蠢了 ==
我改了 replies 的 SortInput
然後一直在想 articles 的 SortInput 為什麼沒改 ==
我發現是我耍蠢了 ==
我改了 replies 的 SortInput
然後一直在想 articles 的 SortInput 為什麼沒改 ==
mrorz
2020-02-19 20:10:45
XDD
起 server 的 console 應該會看到有在 rebuild
起 server 的 console 應該會看到有在 rebuild
mrorz
17:51:39
應該不用的呀 @@
mrorz
17:52:42
不過他應該不是改每個東西都會 rebuild,例如說 static file
但 react component 那些他應該要會
但 react component 那些他應該要會
ael
18:19:13
@bil @mrorz 想問你們之前使用 @tkirby 的 Landing page 的 template 在哪邊可以找到啊
感謝!!
ronnywang
2020-02-19 18:25:06
如果不記得連結的話,可以回頭到大松 hackfoldr 找,左邊會有
mrorz
18:20:10
landing page template for g0v grants awardee projects - g0v/grants-landing-template
ael
18:21:19
感謝!!
ronnywang
18:25:06
如果不記得連結的話,可以回頭到大松 hackfoldr 找,左邊會有
yanglin
19:06:09
好
我發現是我耍蠢了 ==
我改了 replies 的 SortInput
然後一直在想 articles 的 SortInput 為什麼沒改 ==
我發現是我耍蠢了 ==
我改了 replies 的 SortInput
然後一直在想 articles 的 SortInput 為什麼沒改 ==
mrorz
20:10:45
XDD
起 server 的 console 應該會看到有在 rebuild
起 server 的 console 應該會看到有在 rebuild
mrorz
20:22:04
https://github.com/cofacts/rumors-site/pulls 3 個網站相關 PR 求 review 🙏
Category UI 要等 @ggm 的 API 實作完成之後才能 merge 唷
Category UI 要等 @ggm 的 API 實作完成之後才能 merge 唷
Rumors list / creation UI, with server-side rendering - cofacts/rumors-site
bil
20:36:18
一喝到酒我就變得ㄎㄧㄤㄎㄧㄤㄎㄧㄤ
ky
21:50:39
比鄰在社創嗎
bil
21:50:41
感謝Howard 與好想工作室支持與大力協助提供場地。
Cofacts 要辦編輯小聚台南場囉!!!!!我愛台南❤️
Cofacts 4月編輯小聚,暫定04/18 下午2點到5點@好想工作室
Cofacts 要辦編輯小聚台南場囉!!!!!我愛台南❤️
Cofacts 4月編輯小聚,暫定04/18 下午2點到5點@好想工作室
- 👍6
 5
5
mrorz
22:15:49
@bil chatbot logo: https://drive.google.com/drive/folders/1nnOFuxW70m7OgGfAI3fVcB8ri2ugODki
lucien
2020-02-20 03:14:20
放了其他配色
2020-02-20
lucien
03:14:20
放了其他配色
ronnywang
17:19:55
@mrorz 對了,我好像一直都在 cofacts 的 rollbar 名單中,不過我一直都沒有權限處理任何 cofacts 的事,我好像可以不需要在名單裡面 XD
mrorz
2020-02-20 17:33:40
改好囉
mrorz
2020-02-20 17:34:55
是說現在 rollbar 放在我的帳號底下 (/mrorz) 也有點怪怪的,我想要開一個 Cofacts account 然後把 `rumors-*` 的 error 們 migrate 過去。
Migrate 完之後 issue 與 occurence 看起來都會在,但是舊的 URL 會失效,需要手動把 occurence / issue URL 裡的 `/mrorz` 換成 `/Cofacts`。另外,owner 名單也會需要重建、email notification 與 github 連動等等也是。
有個好處是,新蓋 account 會有新的 trial period,error 數可以暫時超過 5K XDDD
或許下週三有空的時候來搬家?
Migrate 完之後 issue 與 occurence 看起來都會在,但是舊的 URL 會失效,需要手動把 occurence / issue URL 裡的 `/mrorz` 換成 `/Cofacts`。另外,owner 名單也會需要重建、email notification 與 github 連動等等也是。
有個好處是,新蓋 account 會有新的 trial period,error 數可以暫時超過 5K XDDD
或許下週三有空的時候來搬家?
mrorz
17:33:40
改好囉
mrorz
17:34:55
Replied to a thread: 2020-02-20 17:19:55
是說現在 rollbar 放在我的帳號底下 (/mrorz) 也有點怪怪的,我想要開一個 Cofacts account 然後把 `rumors-*` 的 error 們 migrate 過去。
Migrate 完之後 issue 與 occurence 看起來都會在,但是舊的 URL 會失效,需要手動把 occurence / issue URL 裡的 `/mrorz` 換成 `/Cofacts`。另外,owner 名單也會需要重建、email notification 與 github 連動等等也是。
有個好處是,新蓋 account 會有新的 trial period,error 數可以暫時超過 5K XDDD
或許下週三有空的時候來搬家?
Migrate 完之後 issue 與 occurence 看起來都會在,但是舊的 URL 會失效,需要手動把 occurence / issue URL 裡的 `/mrorz` 換成 `/Cofacts`。另外,owner 名單也會需要重建、email notification 與 github 連動等等也是。
有個好處是,新蓋 account 會有新的 trial period,error 數可以暫時超過 5K XDDD
或許下週三有空的時候來搬家?
- 1
- 🚀1
- 😆1
Robin Chien
17:39:50
@goodnana1224 has joined the channel
2020-02-21
YT
01:21:19
@nick19980922 has joined the channel
Wei ji
10:39:47
@40432220 has joined the channel
chihao
15:40:35
\ @robinlee416 /
Robin
18:01:29
還有買一送一的麵包呵呵
2020-02-22
cai
00:14:40
@iacmai has left the channel
2020-02-23
mrorz
13:57:35
這個 PR 預計可以解決目前每天 100 次左右的 Rollbar error,請大家看看
https://github.com/cofacts/rumors-site/pull/221
https://github.com/cofacts/rumors-site/pull/221
Fixes #208 . React 16 depends on Set and Map, which is not provided on old browswers like IE<11 or Chrome < 37. Despite their super low market share, some old phones are still using them, and...
mrorz
16:55:14
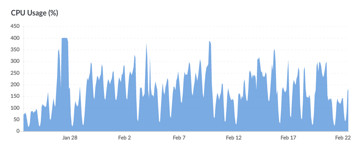
另一方面是,我挖 docker log 發現昨天晚上其實 elasticsearch 有被 OOM kill 掉,在一連串 GC 之後
mrorz
16:55:15
```{"log":"[2020-02-22T14:53:41,309][WARN ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85507] overhead, spent [2.5s] collecting in the last [2.6s]\n","stream":"stdout","time":"2020-02-22T14:53:41.310003583Z"}
{"log":"[2020-02-22T14:53:42,695][WARN ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85508] overhead, spent [1.3s] collecting in the last [1.4s]\n","stream":"stdout","time":"2020-02-22T14:53:42.695417946Z"}
{"log":"java.lang.OutOfMemoryError: Java heap space\n","stream":"stdout","time":"2020-02-22T14:53:46.477803883Z"}
{"log":"Dumping heap to data/java_pid1.hprof ...\n","stream":"stdout","time":"2020-02-22T14:53:46.480846044Z"}
{"log":"Unable to create data/java_pid1.hprof: File exists\n","stream":"stdout","time":"2020-02-22T14:53:46.480865697Z"}
{"log":"[2020-02-22T14:53:50,350][WARN ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85509] overhead, spent [5.4s] collecting in the last [1.1s]\n","stream":"stdout","time":"2020-02-22T14:53:50.350950534Z"}
{"log":"[2020-02-22T14:53:50,991][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [] fatal error in thread [elasticsearch[VxKgRte][search][T#5]], exiting\n","stream":"stdout","time":"2020-02-22T14:53:50.992911655Z"}
{"log":"java.lang.OutOfMemoryError: Java heap space\n","stream":"stdout","time":"2020-02-22T14:53:50.99295262Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler$1.newInstance(PageCacheRecycler.java:99) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992957994Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler$1.newInstance(PageCacheRecycler.java:96) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992970299Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.DequeRecycler.obtain(DequeRecycler.java:53) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992974944Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.AbstractRecycler.obtain(AbstractRecycler.java:33) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992978944Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.DequeRecycler.obtain(DequeRecycler.java:28) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992982695Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.FilterRecycler.obtain(FilterRecycler.java:39) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992986486Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.Recyclers$3.obtain(Recyclers.java:119) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992990167Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.FilterRecycler.obtain(FilterRecycler.java:39) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.99300142Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler.bytePage(PageCacheRecycler.java:147) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993006335Z"}
{"log":"\u0009at org.elasticsearch.common.util.AbstractBigArray.newBytePage(AbstractBigArray.java:117) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993010203Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigByteArray.resize(BigByteArray.java:143) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993013787Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.resizeInPlace(BigArrays.java:449) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993040728Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.resize(BigArrays.java:496) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993044984Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.grow(BigArrays.java:513) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993048553Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.BytesStreamOutput.ensureCapacity(BytesStreamOutput.java:157) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993052327Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.ReleasableBytesStreamOutput.ensureCapacity(ReleasableBytesStreamOutput.java:69) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993057221Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.BytesStreamOutput.writeBytes(BytesStreamOutput.java:89) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993069304Z"}
{"log":"\u0009at org.elasticsearch.common.io.Streams$FlushOnCloseOutputStream.writeBytes(Streams.java:266) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993073713Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.StreamOutput.write(StreamOutput.java:457) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993077443Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.copyStream(JsonXContentGenerator.java:477) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993081069Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.writeRawField(JsonXContentGenerator.java:327) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993084734Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.writeRawField(JsonXContentGenerator.java:308) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993088488Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.XContentBuilder.rawField(XContentBuilder.java:889) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993100021Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.XContentHelper.writeRawField(XContentHelper.java:305) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993105355Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHit.toInnerXContent(SearchHit.java:451) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993109094Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHit.toXContent(SearchHit.java:398) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993112742Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHits.toXContent(SearchHits.java:117) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993116384Z"}
{"log":"\u0009at org.elasticsearch.action.search.SearchResponseSections.toXContent(SearchResponseSections.java:106) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993119984Z"}
{"log":"\u0009at org.elasticsearch.action.search.SearchResponse.innerToXContent(SearchResponse.java:241) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993123649Z"}
{"log":"\u0009at org.elasticsearch.action.search.MultiSearchResponse.toXContent(MultiSearchResponse.java:176) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993135553Z"}
{"log":"\u0009at org.elasticsearch.rest.action.RestToXContentListener.buildResponse(RestToXContentListener.java:47) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.99314013Z"}
{"log":"\u0009at org.elasticsearch.rest.action.RestToXContentListener.buildResponse(RestToXContentListener.java:42) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993148005Z"}
{"log":"[2020-02-22T14:53:51,760][INFO ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85510] overhead, spent [2.8s] collecting in the last [7.9s]\n","stream":"stdout","time":"2020-02-22T14:53:51.76068663Z"}
{"log":"OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.\n","stream":"stderr","time":"2020-02-22T14:53:55.717366414Z"}
{"log":"[2020-02-22T14:54:01,354][INFO ][o.e.n.Node ] [] initializing ...\n","stream":"stdout","time":"2020-02-22T14:54:01.356812163Z"}
{"log":"[2020-02-22T14:54:01,629][INFO ][o.e.e.NodeEnvironment ] [VxKgRte] using [1] data paths, mounts [[/usr/share/elasticsearch/data (/dev/root)]], net usable_space [99gb], net total_space [157.5gb], types [ext4]\n","stream":"stdout","time":"2020-02-22T14:54:01.630403354Z"}```
{"log":"[2020-02-22T14:53:42,695][WARN ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85508] overhead, spent [1.3s] collecting in the last [1.4s]\n","stream":"stdout","time":"2020-02-22T14:53:42.695417946Z"}
{"log":"java.lang.OutOfMemoryError: Java heap space\n","stream":"stdout","time":"2020-02-22T14:53:46.477803883Z"}
{"log":"Dumping heap to data/java_pid1.hprof ...\n","stream":"stdout","time":"2020-02-22T14:53:46.480846044Z"}
{"log":"Unable to create data/java_pid1.hprof: File exists\n","stream":"stdout","time":"2020-02-22T14:53:46.480865697Z"}
{"log":"[2020-02-22T14:53:50,350][WARN ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85509] overhead, spent [5.4s] collecting in the last [1.1s]\n","stream":"stdout","time":"2020-02-22T14:53:50.350950534Z"}
{"log":"[2020-02-22T14:53:50,991][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [] fatal error in thread [elasticsearch[VxKgRte][search][T#5]], exiting\n","stream":"stdout","time":"2020-02-22T14:53:50.992911655Z"}
{"log":"java.lang.OutOfMemoryError: Java heap space\n","stream":"stdout","time":"2020-02-22T14:53:50.99295262Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler$1.newInstance(PageCacheRecycler.java:99) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992957994Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler$1.newInstance(PageCacheRecycler.java:96) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992970299Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.DequeRecycler.obtain(DequeRecycler.java:53) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992974944Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.AbstractRecycler.obtain(AbstractRecycler.java:33) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992978944Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.DequeRecycler.obtain(DequeRecycler.java:28) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992982695Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.FilterRecycler.obtain(FilterRecycler.java:39) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992986486Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.Recyclers$3.obtain(Recyclers.java:119) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.992990167Z"}
{"log":"\u0009at org.elasticsearch.common.recycler.FilterRecycler.obtain(FilterRecycler.java:39) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.99300142Z"}
{"log":"\u0009at org.elasticsearch.common.util.PageCacheRecycler.bytePage(PageCacheRecycler.java:147) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993006335Z"}
{"log":"\u0009at org.elasticsearch.common.util.AbstractBigArray.newBytePage(AbstractBigArray.java:117) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993010203Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigByteArray.resize(BigByteArray.java:143) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993013787Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.resizeInPlace(BigArrays.java:449) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993040728Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.resize(BigArrays.java:496) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993044984Z"}
{"log":"\u0009at org.elasticsearch.common.util.BigArrays.grow(BigArrays.java:513) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993048553Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.BytesStreamOutput.ensureCapacity(BytesStreamOutput.java:157) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993052327Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.ReleasableBytesStreamOutput.ensureCapacity(ReleasableBytesStreamOutput.java:69) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993057221Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.BytesStreamOutput.writeBytes(BytesStreamOutput.java:89) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993069304Z"}
{"log":"\u0009at org.elasticsearch.common.io.Streams$FlushOnCloseOutputStream.writeBytes(Streams.java:266) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993073713Z"}
{"log":"\u0009at org.elasticsearch.common.io.stream.StreamOutput.write(StreamOutput.java:457) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993077443Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.copyStream(JsonXContentGenerator.java:477) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993081069Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.writeRawField(JsonXContentGenerator.java:327) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993084734Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.json.JsonXContentGenerator.writeRawField(JsonXContentGenerator.java:308) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993088488Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.XContentBuilder.rawField(XContentBuilder.java:889) ~[elasticsearch-x-content-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993100021Z"}
{"log":"\u0009at org.elasticsearch.common.xcontent.XContentHelper.writeRawField(XContentHelper.java:305) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993105355Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHit.toInnerXContent(SearchHit.java:451) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993109094Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHit.toXContent(SearchHit.java:398) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993112742Z"}
{"log":"\u0009at org.elasticsearch.search.SearchHits.toXContent(SearchHits.java:117) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993116384Z"}
{"log":"\u0009at org.elasticsearch.action.search.SearchResponseSections.toXContent(SearchResponseSections.java:106) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993119984Z"}
{"log":"\u0009at org.elasticsearch.action.search.SearchResponse.innerToXContent(SearchResponse.java:241) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993123649Z"}
{"log":"\u0009at org.elasticsearch.action.search.MultiSearchResponse.toXContent(MultiSearchResponse.java:176) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993135553Z"}
{"log":"\u0009at org.elasticsearch.rest.action.RestToXContentListener.buildResponse(RestToXContentListener.java:47) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.99314013Z"}
{"log":"\u0009at org.elasticsearch.rest.action.RestToXContentListener.buildResponse(RestToXContentListener.java:42) ~[elasticsearch-6.3.2.jar:6.3.2]\n","stream":"stdout","time":"2020-02-22T14:53:50.993148005Z"}
{"log":"[2020-02-22T14:53:51,760][INFO ][o.e.m.j.JvmGcMonitorService] [VxKgRte] [gc][85510] overhead, spent [2.8s] collecting in the last [7.9s]\n","stream":"stdout","time":"2020-02-22T14:53:51.76068663Z"}
{"log":"OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.\n","stream":"stderr","time":"2020-02-22T14:53:55.717366414Z"}
{"log":"[2020-02-22T14:54:01,354][INFO ][o.e.n.Node ] [] initializing ...\n","stream":"stdout","time":"2020-02-22T14:54:01.356812163Z"}
{"log":"[2020-02-22T14:54:01,629][INFO ][o.e.e.NodeEnvironment ] [VxKgRte] using [1] data paths, mounts [[/usr/share/elasticsearch/data (/dev/root)]], net usable_space [99gb], net total_space [157.5gb], types [ext4]\n","stream":"stdout","time":"2020-02-22T14:54:01.630403354Z"}```
mrorz
16:55:15
mrorz
16:55:20
所以我想把 elasticsearch 記憶體稍微調高一點
目前是 `ES_JAVA_OPTS=-Xms1500m -Xmx1500m` 我想調成 `3000m`
目前是 `ES_JAVA_OPTS=-Xms1500m -Xmx1500m` 我想調成 `3000m`
mrorz
16:57:30
但網路上也有文章說不該亂調:
https://makina-corpus.com/blog/metier/2014/elasticsearch-when-giving-it-more-memory-causes-more-outofmemory-errors
http://www.codingthearchitecture.com/2008/01/14/jvm_lies_the_outofmemory_myth.html
https://makina-corpus.com/blog/metier/2014/elasticsearch-when-giving-it-more-memory-causes-more-outofmemory-errors
http://www.codingthearchitecture.com/2008/01/14/jvm_lies_the_outofmemory_myth.html
makina-corpus.com
As odd as it might seem, sometimes the way to fix OutOfMemory errors is actually to reduce the JVM heap size.
mrorz
16:59:36
官方文件則是希望只給一半 https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html#_give_less_than_half_your_memory_to_lucene
不過現在 RAM 是 8G 的話,我給 JVM 3GB 應該合理齁
不過現在 RAM 是 8G 的話,我給 JVM 3GB 應該合理齁
mrorz
17:04:01
給到 4G 好了?
- 👍1
mrorz
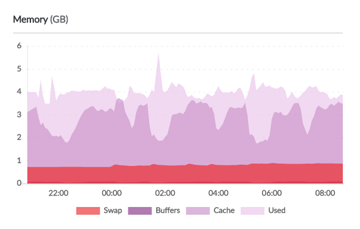
2020-02-24 13:52:35
Elasticsearch JVM RAM 給到 4GB 了,這樣整個伺服器 RAM 用量是 6GB,看起來來 ok。
不知道為什麼 swap 用量也變大了就是。
不知道為什麼 swap 用量也變大了就是。
breaking0215
19:00:40
@breaking0215 has joined the channel
au0408
20:25:45
@au0408 has joined the channel
mrorz
20:32:37
另外,關於另一個每天會被觸發快 50 次的 error,找到原因了:應該是使用者在沒有登入的狀況下,對 reply 或 reply request upvote 或 downvote。
https://github.com/cofacts/rumors-site/issues/209
我覺得現階段就直接跳一個 `alert` 說請先登入就好,之後怎麼做就再看設計師如何設計?
https://github.com/cofacts/rumors-site/issues/209
我覺得現階段就直接跳一個 `alert` 說請先登入就好,之後怎麼做就再看設計師如何設計?
View details in Rollbar: <https://rollbar.com/mrorz/rumors-site/items/62/> t: userId is not set via query string. File &quot;https://cofacts.g0v.tw/_next/static/chunks/commons.3d6e3726d3a6a9caf962.js...
mrorz
20:37:04
是說在「尚未回覆」的 tab 底下可以按照「最近回應排序」好像有點奇怪 XD
mrorz
2020-02-23 20:37:45
但這應該是小事,@lucien 似乎比較想要另外做一頁,所以我覺得可以下一階段再修
yanglin
2020-02-23 20:55:38
不過那部分邏輯要修就要把 route state 傳進去判斷
好像也有點小髒
好像也有點小髒
mrorz
2020-02-23 21:59:58
嗯,所以可以先等設計,再看看邏輯如何修改~
mrorz
20:37:45
Replied to a thread: 2020-02-23 20:37:04
但這應該是小事,@lucien 似乎比較想要另外做一頁,所以我覺得可以下一階段再修
- 👌1
yanglin
20:55:38
不過那部分邏輯要修就要把 route state 傳進去判斷
好像也有點小髒
好像也有點小髒
2020-02-24
p278732001
09:14:27
@p278732001 has joined the channel
mrorz
13:47:36
最近 elasticsearch 的 docker container 有一些 warning 如下:
https://gist.github.com/MrOrz/d60b1fb33a89f240afa4147538c2688e
看起來下 `/articles/doc/_count` request 時, `doc['replyRequestCount'].value > params.operand` 這個條件偶爾會觸發 runtime error,每小時會觸發個幾次的樣子。
https://gist.github.com/MrOrz/d60b1fb33a89f240afa4147538c2688e
看起來下 `/articles/doc/_count` request 時, `doc['replyRequestCount'].value > params.operand` 這個條件偶爾會觸發 runtime error,每小時會觸發個幾次的樣子。
mrorz
13:48:12
希望 range operator 改下去之後可以讓這個 warning 消失( https://github.com/cofacts/rumors-api/issues/148 )
From 20200212 meeting note, it would be great if we can provide date range search on createdAt for articles and replies, lastRequestedAt or having article reply createdAt for articles. To achieve t...
mrorz
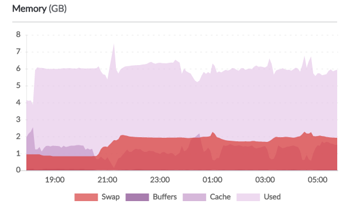
13:52:35
Elasticsearch JVM RAM 給到 4GB 了,這樣整個伺服器 RAM 用量是 6GB,看起來來 ok。
不知道為什麼 swap 用量也變大了就是。
不知道為什麼 swap 用量也變大了就是。
Mag
14:32:42
@iceblinkme has joined the channel
2020-02-25
yiting0537
08:36:24
@yiting0537 has joined the channel
yanglin
11:25:05
@mrorz 今天或明天在 workis 嗎?
我這週四就會先回台中
所以希望有這週需要討論的東西的話能在這兩天盡量先解決掉 XD
我這週四就會先回台中
所以希望有這週需要討論的東西的話能在這兩天盡量先解決掉 XD
mrorz
2020-02-25 11:41:55
啊但我週四才會在 QQ
mrorz
2020-02-25 11:45:06
現在 most recently replied 已經上 production
https://cofacts.g0v.tw/articles?orderBy=lastRepliedAt&filter=solved
不過顯示上還不會有 latest reply,這個部分請跟 @lucien 討論現階段可以先怎麼做唷
https://cofacts.g0v.tw/articles?orderBy=lastRepliedAt&filter=solved
不過顯示上還不會有 latest reply,這個部分請跟 @lucien 討論現階段可以先怎麼做唷
yanglin
2020-02-25 11:45:57
好的
mrorz
2020-02-25 12:15:48
另外就是
我覺得我可以整理 Website user 的 usage analytics
包含 Screen resolution, device & referral, browser, OS, landing page 等等
想說這樣應該對設計與開發網站有幫助
我覺得我可以整理 Website user 的 usage analytics
包含 Screen resolution, device & referral, browser, OS, landing page 等等
想說這樣應該對設計與開發網站有幫助
mrorz
11:45:06
現在 most recently replied 已經上 production
https://cofacts.g0v.tw/articles?orderBy=lastRepliedAt&filter=solved
不過顯示上還不會有 latest reply,這個部分請跟 @lucien 討論現階段可以先怎麼做唷
https://cofacts.g0v.tw/articles?orderBy=lastRepliedAt&filter=solved
不過顯示上還不會有 latest reply,這個部分請跟 @lucien 討論現階段可以先怎麼做唷
yanglin
11:45:57
好的
mrorz
12:15:48
另外就是
我覺得我可以整理 Website user 的 usage analytics
包含 Screen resolution, device & referral, browser, OS, landing page 等等
想說這樣應該對設計與開發網站有幫助
我覺得我可以整理 Website user 的 usage analytics
包含 Screen resolution, device & referral, browser, OS, landing page 等等
想說這樣應該對設計與開發網站有幫助
mrorz
12:16:50
Google Data Studio turns your data into informative dashboards and reports that are easy to read, easy to share, and fully customizable.
mrorz
14:15:35
@lucien @stbb1025 我在 Cofacts analytics 新增了瀏覽器相關數據
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/1M
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/1M
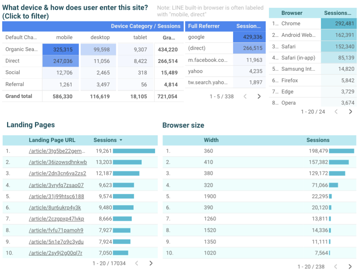
- 👍1
mrorz
2020-02-25 14:21:23
左上角兩張深藍色的表,可以點按,圖表的其他數字會更新。
例如說,如果想看 mobile, organic search (代表在手機 google 搜尋到 Cofacts 進來) 的數據
可以點 mobile, organic search 那格,等個幾十秒讓他 load,最後會得到這張圖
解讀就是
1. 手機上透過 organic search 點進來的人,大多都是 google 進來,landing page 也大多是特定文章頁面,大概是 google 訊息關鍵字然後找到 Cofacts 的。
2. 手機搜尋使用者的瀏覽器寬度方面,大多為 360px ~ 380px 寬,但也有 320px 的。
3. Organic search 使用者 Android vs iOS 約 1:1,前者大多用 Google chrome
例如說,如果想看 mobile, organic search (代表在手機 google 搜尋到 Cofacts 進來) 的數據
可以點 mobile, organic search 那格,等個幾十秒讓他 load,最後會得到這張圖
解讀就是
1. 手機上透過 organic search 點進來的人,大多都是 google 進來,landing page 也大多是特定文章頁面,大概是 google 訊息關鍵字然後找到 Cofacts 的。
2. 手機搜尋使用者的瀏覽器寬度方面,大多為 360px ~ 380px 寬,但也有 320px 的。
3. Organic search 使用者 Android vs iOS 約 1:1,前者大多用 Google chrome
mrorz
2020-02-25 14:28:10
另外,
右上角 browser 右鍵可以 drill up 到 OS、點按特定 browser 右鍵,
可以 drill down 到 browser version
Browser size 右鍵可以 drill down 到 height
另外也可以選擇顯示 pageview 或 user
右上角 browser 右鍵可以 drill up 到 OS、點按特定 browser 右鍵,
可以 drill down 到 browser version
Browser size 右鍵可以 drill down 到 height
另外也可以選擇顯示 pageview 或 user
mrorz
2020-02-25 14:29:01
我覺得這個表最重大的意義是
我們應該要採取 mobile first design⋯⋯ XD
至於已經登入的編輯都用什麼,這個部分要另外埋 code QQ
我們應該要採取 mobile first design⋯⋯ XD
至於已經登入的編輯都用什麼,這個部分要另外埋 code QQ
stbb1025
2020-02-25 14:39:03
收到~
mrorz
14:21:23
左上角兩張深藍色的表,可以點按,圖表的其他數字會更新。
例如說,如果想看 mobile, organic search (代表在手機 google 搜尋到 Cofacts 進來) 的數據
可以點 mobile, organic search 那格,等個幾十秒讓他 load,最後會得到這張圖
解讀就是
1. 手機上透過 organic search 點進來的人,大多都是 google 進來,landing page 也大多是特定文章頁面,大概是 google 訊息關鍵字然後找到 Cofacts 的。
2. 手機搜尋使用者的瀏覽器寬度方面,大多為 360px ~ 380px 寬,但也有 320px 的。
3. Organic search 使用者 Android vs iOS 約 1:1,前者大多用 Google chrome
例如說,如果想看 mobile, organic search (代表在手機 google 搜尋到 Cofacts 進來) 的數據
可以點 mobile, organic search 那格,等個幾十秒讓他 load,最後會得到這張圖
解讀就是
1. 手機上透過 organic search 點進來的人,大多都是 google 進來,landing page 也大多是特定文章頁面,大概是 google 訊息關鍵字然後找到 Cofacts 的。
2. 手機搜尋使用者的瀏覽器寬度方面,大多為 360px ~ 380px 寬,但也有 320px 的。
3. Organic search 使用者 Android vs iOS 約 1:1,前者大多用 Google chrome
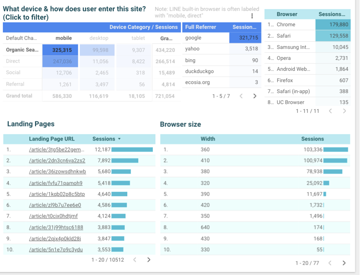
mrorz
14:28:10
另外,
右上角 browser 右鍵可以 drill up 到 OS、點按特定 browser 右鍵,
可以 drill down 到 browser version
Browser size 右鍵可以 drill down 到 height
另外也可以選擇顯示 pageview 或 user
右上角 browser 右鍵可以 drill up 到 OS、點按特定 browser 右鍵,
可以 drill down 到 browser version
Browser size 右鍵可以 drill down 到 height
另外也可以選擇顯示 pageview 或 user
mrorz
14:29:01
Replied to a thread: 2020-02-25 14:15:35
我覺得這個表最重大的意義是
我們應該要採取 mobile first design⋯⋯ XD
至於已經登入的編輯都用什麼,這個部分要另外埋 code QQ
我們應該要採取 mobile first design⋯⋯ XD
至於已經登入的編輯都用什麼,這個部分要另外埋 code QQ
- 👍2
stbb1025
14:39:03
收到~
2020-02-26
mrorz
13:47:59
Howar31
15:53:09
@howar31 has joined the channel
lucien
17:56:22
@yanglin5689446 最新查核頁有一些filter / sort 定義補完了
@stbb1025 wireframe 除了filter / sort 還沒完全上去,其他資訊已確定
https://g0v.hackmd.io/ahtI6xsFRQyxktrIlc1VcQ
@stbb1025 wireframe 除了filter / sort 還沒完全上去,其他資訊已確定
https://g0v.hackmd.io/ahtI6xsFRQyxktrIlc1VcQ
yanglin
17:56:46
好的 3Q
lucien
20:04:57
TechNotes
In this post, I discuss in-depth information on how to manage elasticsearch in production
lucien
20:09:24
HackMD
Cofacts Next Spec ===== 全站導航 --- - [列表](/iJm9_nZaTA2GyInn7ycxoA) 各頁細節 --- - [WIP][可疑訊息](/ahtI
2020-02-28
Howish
12:36:51
@howardshih617038 has joined the channel