#cofacts
2023-05-01
2023-05-02
mrorz
13:55:39
記錄一下有問題的回應:
> 這則訊息需要特別留意的地方是「罰單漲到4500了」。因為這個數字可能會讓人感到驚訝或擔心,但實際上在2023年4月,台灣的交通罰款最高只有2000元,且罰單金額通常會因違規情節而有所不同。因此,這個數字可能是誇大或錯誤的,閱聽人需要懷疑訊息的真實性,並進一步查證。此外,訊息中也沒有提供任何官方來源或證據支持,也需要引起閱聽人的注意。
我直接開大 temperature 重新生一個 AI reply 唷
> 這則訊息需要特別留意的地方是「罰單漲到4500了」。因為這個數字可能會讓人感到驚訝或擔心,但實際上在2023年4月,台灣的交通罰款最高只有2000元,且罰單金額通常會因違規情節而有所不同。因此,這個數字可能是誇大或錯誤的,閱聽人需要懷疑訊息的真實性,並進一步查證。此外,訊息中也沒有提供任何官方來源或證據支持,也需要引起閱聽人的注意。
我直接開大 temperature 重新生一個 AI reply 唷
mrorz
16:01:13
Replied to a thread: 2023-04-25 08:48:25
LaMDA 的 groundness 作法:
LaMDA 先生答案
LaMDA-Research 問問題
Toolset (TS) 去找資料 extract 資訊回來
https://arxiv.org/pdf/2201.08239.pdf
https://ai.googleblog.com/2022/01/lamda-towards-safe-grounded-and-high.html#:~:text=of%20the%20dialog.-,Factual%20Grounding,-While%20people%20are
LaMDA 先生答案
LaMDA-Research 問問題
Toolset (TS) 去找資料 extract 資訊回來
https://arxiv.org/pdf/2201.08239.pdf
https://ai.googleblog.com/2022/01/lamda-towards-safe-grounded-and-high.html#:~:text=of%20the%20dialog.-,Factual%20Grounding,-While%20people%20are

2023-05-03
mrorz
19:08:02

cai
22:09:35
IG 版,一樣是媽媽接到電話,帶去警察局備案https://cofacts.tw/article/X6TF4YcBpPlTXSoGI34h
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
2023-05-04
bil
13:35:19
想問問下週會議可不可以調整到週四晚上
ronnywang
14:06:06
https://developers.facebook.com/blog/post/2023/02/01/developer-platform-requiring-business-verification-for-advanced-access/
剛發現 FB 在 2/1 有改了 FB 登入的 advaneced access 權限的規定,改成一定要商家認證才能使用,針對舊的 App 也有說 7/1 之後也有強制認證,否則 8/1 就會失效, cofacts 也有 FB 登入可能要注意看看?
剛發現 FB 在 2/1 有改了 FB 登入的 advaneced access 權限的規定,改成一定要商家認證才能使用,針對舊的 App 也有說 7/1 之後也有強制認證,否則 8/1 就會失效, cofacts 也有 FB 登入可能要注意看看?
Meta for Developers
Facebook For Developers
- 😮2
mrorz
2023-05-04 20:07:51
ronnywang
2023-05-05 08:47:20
我是昨天想要做新的需要 FB 登入的服務才發現現在新服務已經是強制要商業認證,才查到這篇文章的..看起來他真的是要照文章說的 7/1 才會通知開發者
mrorz
2023-05-10 15:15:56
ronnywang
2023-05-10 15:17:23
變成還是可以做 Facebook login ,但是抓不到 email
ronnywang
14:06:06
https://developers.facebook.com/blog/post/2023/02/01/developer-platform-requiring-business-verification-for-advanced-access/
剛發現 FB 在 2/1 有改了 FB 登入的 advaneced access 權限的規定,改成一定要商家認證才能使用,針對舊的 App 也有說 7/1 之後也有強制認證,否則 8/1 就會失效, cofacts 也有 FB 登入可能要注意看看?
剛發現 FB 在 2/1 有改了 FB 登入的 advaneced access 權限的規定,改成一定要商家認證才能使用,針對舊的 App 也有說 7/1 之後也有強制認證,否則 8/1 就會失效, cofacts 也有 FB 登入可能要注意看看?
mrorz
2023-05-04 20:07:51
ronnywang
2023-05-05 08:47:20
我是昨天想要做新的需要 FB 登入的服務才發現現在新服務已經是強制要商業認證,才查到這篇文章的..看起來他真的是要照文章說的 7/1 才會通知開發者
mrorz
2023-05-10 15:15:56
ronnywang
2023-05-10 15:17:23
變成還是可以做 Facebook login ,但是抓不到 email
mrorz
20:07:51
mrorz
21:54:04
又是 doc retrieval 來避免 hallucination
https://vectara.com/avoiding-hallucinations-in-llm-powered-applications/
https://vectara.com/avoiding-hallucinations-in-llm-powered-applications/
2023-05-05
ronnywang
08:47:20
我是昨天想要做新的需要 FB 登入的服務才發現現在新服務已經是強制要商業認證,才查到這篇文章的..看起來他真的是要照文章說的 7/1 才會通知開發者
Sophia Soong
09:03:58
@hys.sophia has joined the channel
2023-05-08
Cartus
11:20:25
@b06208002 has joined the channel
mrorz
15:33:25
目前 Cofacts dataset 是靠使用者填寫 Google form 加上 Apps script 自動 share Google drive access to CSV files 來分享的,以確保每個下載者都有讀過 license。但我的 apps script 美 7 天會被 revoke access 要重新 authorize,過去幾年來每週都要重新 authorize 然後檢查有沒有漏掉的使用者,真的是滿煩的。
我最近才發現原來 huggingface 可以放 data set 而且可以設定 gated access,就是要留下 email 申稱自己有讀過 license 才能 access:
https://huggingface.co/docs/hub/datasets-gated
我希望這麼做可以
• 提升 Cofacts dataset visibility & usage
• 維持追蹤 Cofacts dataset 的 user
• 追蹤 Cofacts dataset use case (做得到嗎?)
好奇 <!here> 的 data scientists 覺得這樣如何?有什麼需要注意的地方嗎?
cc/ @gary96302000.eecs96
我最近才發現原來 huggingface 可以放 data set 而且可以設定 gated access,就是要留下 email 申稱自己有讀過 license 才能 access:
https://huggingface.co/docs/hub/datasets-gated
我希望這麼做可以
• 提升 Cofacts dataset visibility & usage
• 維持追蹤 Cofacts dataset 的 user
• 追蹤 Cofacts dataset use case (做得到嗎?)
好奇 <!here> 的 data scientists 覺得這樣如何?有什麼需要注意的地方嗎?
cc/ @gary96302000.eecs96
gary96302000.eecs96
2023-05-08 16:49:12
我自己是沒有在HF 上面用 datasets 過,不過這個使用場景的話在 HF 上應該是比較方便追蹤的沒錯
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
gary96302000.eecs96
2023-05-08 19:01:54
恩 應該是作者自己寫的 沒有強制性
mrorz
2023-05-16 11:48:18
在 HuggingFace 上面開好了 Organization
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
mrorz
2023-05-16 11:48:45
gary96302000.eecs96
2023-05-16 11:49:07
確實
gary96302000.eecs96
2023-05-16 11:49:26
有名的 dataset 都是因為有名的 model 或是比賽才紅的
gary96302000.eecs96
2023-05-16 11:49:42
ㄎ ㄎ
mrorz
2023-05-16 11:50:30
dataset 一夕爆紅 www
mrorz
2023-05-16 11:50:55
`im-messages-and-crowd-sourced-fact-checks` 這種名字不好嗎
mrorz
2023-05-16 11:51:04
是不是會翻車
因為很難 cite
因為很難 cite
gary96302000.eecs96
2023-05-16 11:51:12
恩
mrorz
2023-05-16 11:51:21
寫在 paper 裡的時候會佔一行
gary96302000.eecs96
2023-05-16 11:51:22
通常都是寫在paper 裡
gary96302000.eecs96
2023-05-16 11:51:26
嘿啊
gary96302000.eecs96
2023-05-16 11:51:31
都會用縮寫
mrorz
2023-05-16 11:51:41
但我 title 就叫 Cofacts data
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
gary96302000.eecs96
2023-05-16 11:51:45
什麼 MNIST CIFAR
mrorz
2023-05-16 11:51:55
很難懂耶這些縮寫
gary96302000.eecs96
2023-05-16 11:52:02
恩啊
gary96302000.eecs96
2023-05-16 11:52:08
縮寫通常都看不出來意義
mrorz
2023-05-16 11:53:16
gary96302000.eecs96
2023-05-16 11:54:12
我最近有在 follow 的一個 open source project:https://github.com/LAION-AI/Open-Assistant
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
gary96302000.eecs96
2023-05-16 11:54:23
oasst1
gary96302000.eecs96
2023-05-16 11:54:32
也是完全不知道是什麼
gary96302000.eecs96
2023-05-16 11:55:43
感覺 url 跟組織/專案名稱一樣的話不太好 通常好像不會這麼取
mrorz
2023-05-16 11:56:31
目前在 github 上長這樣 https://github.com/cofacts/opendata
gary96302000.eecs96
2023-05-16 11:57:04
我猜大原則就是 specific/clear
gary96302000.eecs96
2023-05-16 11:57:11
這樣更直接一些
mrorz
2023-05-16 11:58:03
那就 `cofacts/archive`
或 `cofacts/im-fact-check-archive`
或 `cofacts/im-fact-check-archive`
gary96302000.eecs96
2023-05-16 11:58:41
im 的意思是什麼啊 好奇問個
mrorz
2023-05-16 11:58:51
instant message?
mrorz
2023-05-16 11:59:00
看來不是個常用字
mrorz
2023-05-16 11:59:26
可能換個 msg-fact-check-archive
mrorz
2023-05-16 11:59:36
或就 archive
gary96302000.eecs96
2023-05-16 11:59:55
這個數量有多少筆
mrorz
2023-05-16 12:00:50
會成長,所以z;4gj4xu;4lc3vu;4u,3ej94ej94
gary96302000.eecs96
2023-05-16 12:00:52
歐歐
mrorz
2023-05-16 12:01:21
而且會有很多 CSV (訊息、回應、feedback 等等)
mrorz
2023-05-16 12:01:53
不然 msg-fact-check-100k 聽起來滿威
mrorz
2023-05-16 12:02:15
在 200k 的時候再改名就好(?
gary96302000.eecs96
2023-05-16 12:02:40
那如果是我的話 我會這樣取 `line-msg-fact-check-110k-tw`
gary96302000.eecs96
2023-05-16 12:02:47
-tw 可加可不佳
mrorz
2023-05-16 12:03:47
100k 感覺比較不用一直換名字 XD
因為訊息會一直長
因為訊息會一直長
gary96302000.eecs96
2023-05-16 12:03:55
嗯嗯
gary96302000.eecs96
2023-05-16 12:03:56
也行
mrorz
2023-05-16 12:03:59
但從 100k ~ 200k 應該要數年
mrorz
2023-05-16 12:04:07
dataset 可以換名字嗎之後
mrorz
2023-05-16 12:04:16
還是 200k 的時候直接上傳新的
gary96302000.eecs96
2023-05-16 12:04:33
上傳新的感覺更好
gary96302000.eecs96
2023-05-16 12:04:42
不知道到時候格式什麼的會不會改變
gary96302000.eecs96
2023-05-16 12:05:07
或是你100k上傳之後 會開始收到使用人給的回饋
mrorz
2023-05-16 12:05:08
原來如此
gary96302000.eecs96
2023-05-16 12:05:15
那你可能就會在 200k 做修改
mrorz
2023-05-16 12:05:22
但舊的版本會有人一直用嗎
mrorz
2023-05-16 12:05:30
就是舊的留存會有意義嗎
gary96302000.eecs96
2023-05-16 12:05:31
不見得 看好不好用
gary96302000.eecs96
2023-05-16 12:05:46
如果有人要 benchmark 那應該會有用
mrorz
2023-05-16 12:05:52
好喔
gary96302000.eecs96
2023-05-16 12:06:23
因為現在大家也漸漸意識到資料質量比數量重要的多
mrorz
2023-05-16 12:06:40
但 hugging face dataset 本身沒有 versioning 嗎
我看他背後是 git lfs
我看他背後是 git lfs
gary96302000.eecs96
2023-05-16 12:07:26
應該有versioning
gary96302000.eecs96
2023-05-16 12:08:02
嗯嗯
gary96302000.eecs96
2023-05-16 12:09:25
我指的比較像是 資料跟前一版 有著很大程度的不同 這種 例如說有先幫他們做了很多過濾 處理 分類資料
gary96302000.eecs96
2023-05-16 12:09:58
那就比較適合另外開一個
gary96302000.eecs96
2023-05-16 12:10:25
如果單純只是數量上的增加 那在原本的應該就行了
mrorz
2023-05-16 12:15:53
好奇加了 100k 大家會比較想用嗎
還是沒加也 ok
還是沒加也 ok
gary96302000.eecs96
2023-05-16 12:16:15
在意訓練資料數量的人就會想
gary96302000.eecs96
2023-05-16 12:17:56
大部分是都沒加就是了 但這通常都是有名的work或是org做的
mrorz
2023-05-16 12:18:32
我先加好了
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
mrorz
2023-05-16 12:19:18
話說 dataset 含有圖片跟影片的話不會超大嗎
gary96302000.eecs96
2023-05-16 12:19:41
會歐
gary96302000.eecs96
2023-05-16 12:21:07
不過影像的資料集
gary96302000.eecs96
2023-05-16 12:21:12
好像在上面很少就是了
gary96302000.eecs96
2023-05-16 13:14:44
嗯嗯 那個在search filter 也有的樣子
gary96302000.eecs96
2023-05-16 13:15:13
不過一般人通常不會直接這樣搜(?
mrorz
2023-05-16 13:39:22
但我有一堆 csv
mrorz
2023-05-16 13:39:36
他好像只顯示 analytics.csv 的內容(會自己解 zip 就是了)
mrorz
2023-05-16 13:40:14
這樣如果 python 這裡呼叫 `load_dataset`
是不是只會回傳 analytics.csv 呀囧
是不是只會回傳 analytics.csv 呀囧
gary96302000.eecs96
2023-05-16 15:33:58
科科
mrorz
15:33:25
目前 Cofacts dataset 是靠使用者填寫 Google form 加上 Apps script 自動 share Google drive access to CSV files 來分享的,以確保每個下載者都有讀過 license。但我的 apps script 美 7 天會被 revoke access 要重新 authorize,過去幾年來每週都要重新 authorize 然後檢查有沒有漏掉的使用者,真的是滿煩的。
我最近才發現原來 huggingface 可以放 data set 而且可以設定 gated access,就是要留下 email 申稱自己有讀過 license 才能 access:
https://huggingface.co/docs/hub/datasets-gated
我希望這麼做可以
• 提升 Cofacts dataset visibility & usage
• 維持追蹤 Cofacts dataset 的 user
• 追蹤 Cofacts dataset use case (做得到嗎?)
好奇 <!here> 的 data scientists 覺得這樣如何?有什麼需要注意的地方嗎?
cc/ @gary96302000.eecs96
我最近才發現原來 huggingface 可以放 data set 而且可以設定 gated access,就是要留下 email 申稱自己有讀過 license 才能 access:
https://huggingface.co/docs/hub/datasets-gated
我希望這麼做可以
• 提升 Cofacts dataset visibility & usage
• 維持追蹤 Cofacts dataset 的 user
• 追蹤 Cofacts dataset use case (做得到嗎?)
好奇 <!here> 的 data scientists 覺得這樣如何?有什麼需要注意的地方嗎?
cc/ @gary96302000.eecs96
huggingface.co
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
gary96302000.eecs96
2023-05-08 16:49:12
我自己是沒有在HF 上面用 datasets 過,不過這個使用場景的話在 HF 上應該是比較方便追蹤的沒錯
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
gary96302000.eecs96
2023-05-08 19:01:54
恩 應該是作者自己寫的 沒有強制性
mrorz
2023-05-16 11:48:18
在 HuggingFace 上面開好了 Organization
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
mrorz
2023-05-16 11:48:45
gary96302000.eecs96
2023-05-16 11:49:07
確實
gary96302000.eecs96
2023-05-16 11:49:26
有名的 dataset 都是因為有名的 model 或是比賽才紅的
gary96302000.eecs96
2023-05-16 11:49:42
ㄎ ㄎ
mrorz
2023-05-16 11:50:30
dataset 一夕爆紅 www
mrorz
2023-05-16 11:50:55
`im-messages-and-crowd-sourced-fact-checks` 這種名字不好嗎
mrorz
2023-05-16 11:51:04
是不是會翻車
因為很難 cite
因為很難 cite
gary96302000.eecs96
2023-05-16 11:51:12
恩
mrorz
2023-05-16 11:51:21
寫在 paper 裡的時候會佔一行
gary96302000.eecs96
2023-05-16 11:51:22
通常都是寫在paper 裡
gary96302000.eecs96
2023-05-16 11:51:26
嘿啊
gary96302000.eecs96
2023-05-16 11:51:31
都會用縮寫
mrorz
2023-05-16 11:51:41
但我 title 就叫 Cofacts data
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
gary96302000.eecs96
2023-05-16 11:51:45
什麼 MNIST CIFAR
mrorz
2023-05-16 11:51:55
很難懂耶這些縮寫
gary96302000.eecs96
2023-05-16 11:52:02
恩啊
gary96302000.eecs96
2023-05-16 11:52:08
縮寫通常都看不出來意義
mrorz
2023-05-16 11:53:16
gary96302000.eecs96
2023-05-16 11:54:12
我最近有在 follow 的一個 open source project:https://github.com/LAION-AI/Open-Assistant
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
gary96302000.eecs96
2023-05-16 11:54:23
oasst1
gary96302000.eecs96
2023-05-16 11:54:32
也是完全不知道是什麼
gary96302000.eecs96
2023-05-16 11:55:43
感覺 url 跟組織/專案名稱一樣的話不太好 通常好像不會這麼取
mrorz
2023-05-16 11:56:31
目前在 github 上長這樣 https://github.com/cofacts/opendata
gary96302000.eecs96
2023-05-16 11:57:04
我猜大原則就是 specific/clear
gary96302000.eecs96
2023-05-16 11:57:11
這樣更直接一些
mrorz
2023-05-16 11:58:03
那就 `cofacts/archive`
或 `cofacts/im-fact-check-archive`
或 `cofacts/im-fact-check-archive`
gary96302000.eecs96
2023-05-16 11:58:41
im 的意思是什麼啊 好奇問個
mrorz
2023-05-16 11:58:51
instant message?
mrorz
2023-05-16 11:59:00
看來不是個常用字
mrorz
2023-05-16 11:59:26
可能換個 msg-fact-check-archive
mrorz
2023-05-16 11:59:36
或就 archive
gary96302000.eecs96
2023-05-16 11:59:55
這個數量有多少筆
mrorz
2023-05-16 12:00:50
會成長,所以z;4gj4xu;4lc3vu;4u,3ej94ej94
gary96302000.eecs96
2023-05-16 12:00:52
歐歐
mrorz
2023-05-16 12:01:21
而且會有很多 CSV (訊息、回應、feedback 等等)
mrorz
2023-05-16 12:01:53
不然 msg-fact-check-100k 聽起來滿威
mrorz
2023-05-16 12:02:15
在 200k 的時候再改名就好(?
gary96302000.eecs96
2023-05-16 12:02:40
那如果是我的話 我會這樣取 `line-msg-fact-check-110k-tw`
gary96302000.eecs96
2023-05-16 12:02:47
-tw 可加可不佳
mrorz
2023-05-16 12:03:47
100k 感覺比較不用一直換名字 XD
因為訊息會一直長
因為訊息會一直長
gary96302000.eecs96
2023-05-16 12:03:55
嗯嗯
gary96302000.eecs96
2023-05-16 12:03:56
也行
mrorz
2023-05-16 12:03:59
但從 100k ~ 200k 應該要數年
mrorz
2023-05-16 12:04:07
dataset 可以換名字嗎之後
mrorz
2023-05-16 12:04:16
還是 200k 的時候直接上傳新的
gary96302000.eecs96
2023-05-16 12:04:33
上傳新的感覺更好
gary96302000.eecs96
2023-05-16 12:04:42
不知道到時候格式什麼的會不會改變
gary96302000.eecs96
2023-05-16 12:05:07
或是你100k上傳之後 會開始收到使用人給的回饋
mrorz
2023-05-16 12:05:08
原來如此
gary96302000.eecs96
2023-05-16 12:05:15
那你可能就會在 200k 做修改
mrorz
2023-05-16 12:05:22
但舊的版本會有人一直用嗎
mrorz
2023-05-16 12:05:30
就是舊的留存會有意義嗎
gary96302000.eecs96
2023-05-16 12:05:31
不見得 看好不好用
gary96302000.eecs96
2023-05-16 12:05:46
如果有人要 benchmark 那應該會有用
mrorz
2023-05-16 12:05:52
好喔
gary96302000.eecs96
2023-05-16 12:06:23
因為現在大家也漸漸意識到資料質量比數量重要的多
mrorz
2023-05-16 12:06:40
但 hugging face dataset 本身沒有 versioning 嗎
我看他背後是 git lfs
我看他背後是 git lfs
gary96302000.eecs96
2023-05-16 12:07:26
應該有versioning
gary96302000.eecs96
2023-05-16 12:08:02
嗯嗯
gary96302000.eecs96
2023-05-16 12:09:25
我指的比較像是 資料跟前一版 有著很大程度的不同 這種 例如說有先幫他們做了很多過濾 處理 分類資料
gary96302000.eecs96
2023-05-16 12:09:58
那就比較適合另外開一個
gary96302000.eecs96
2023-05-16 12:10:25
如果單純只是數量上的增加 那在原本的應該就行了
mrorz
2023-05-16 12:15:53
好奇加了 100k 大家會比較想用嗎
還是沒加也 ok
還是沒加也 ok
gary96302000.eecs96
2023-05-16 12:16:15
在意訓練資料數量的人就會想
gary96302000.eecs96
2023-05-16 12:17:56
大部分是都沒加就是了 但這通常都是有名的work或是org做的
mrorz
2023-05-16 12:18:32
我先加好了
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
mrorz
2023-05-16 12:19:18
話說 dataset 含有圖片跟影片的話不會超大嗎
gary96302000.eecs96
2023-05-16 12:19:41
會歐
gary96302000.eecs96
2023-05-16 12:21:07
不過影像的資料集
gary96302000.eecs96
2023-05-16 12:21:12
好像在上面很少就是了
gary96302000.eecs96
2023-05-16 13:14:44
嗯嗯 那個在search filter 也有的樣子
gary96302000.eecs96
2023-05-16 13:15:13
不過一般人通常不會直接這樣搜(?
mrorz
2023-05-16 13:39:22
但我有一堆 csv
mrorz
2023-05-16 13:39:36
他好像只顯示 analytics.csv 的內容(會自己解 zip 就是了)
mrorz
2023-05-16 13:40:14
這樣如果 python 這裡呼叫 `load_dataset`
是不是只會回傳 analytics.csv 呀囧
是不是只會回傳 analytics.csv 呀囧
gary96302000.eecs96
2023-05-16 15:33:58
科科
gary96302000.eecs96
16:49:12
我自己是沒有在HF 上面用 datasets 過,不過這個使用場景的話在 HF 上應該是比較方便追蹤的沒錯
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
追蹤 use case 我猜在 additional customization 那邊要他們加上 citation 或是附上他們 github repo 搞不好也行?(就可能 optional 不是 required 的欄位這樣)
注意的地方我目前有想到的就是說明用的語言,中文英文都要有之類的?
gary96302000.eecs96
19:01:54
恩 應該是作者自己寫的 沒有強制性
2023-05-09
chewei 哲瑋
22:50:22
7/1 台中大松命名 ~ 目前預計採用 真的假的 !
Ying
✨ *7 月大松命名徵集中* ✨
嗨大家,
下一場大松將會在 *7/1* 於 `集思台中新烏日會議中心` 舉辦,歡迎大家一起來為大松命名,命名募集時間至下週二 5/9 中午 12:00!
歡迎大家一起發想,請直接在共筆上提出你的點子 :raised_hands:
https://g0v.hackmd.io/@jothon/B1c_yyGNh
- Forwarded from #general
- 2023-05-05 09:55:19
ronnywang
2023-05-09 22:50:54
真的假的?!
Peter
2023-05-09 23:23:40
真的假的?!
蛤?真的假的?
mrorz
2023-05-10 14:28:22
真的假的
Carmen
2023-05-11 17:53:48
好耶!真的假的 🙌
chewei 哲瑋
22:50:22
7/1 台中大松命名 ~ 目前預計採用 真的假的 !
✨ *7 月大松命名徵集中* ✨
嗨大家,
下一場大松將會在 *7/1* 於 `集思台中新烏日會議中心` 舉辦,歡迎大家一起來為大松命名,命名募集時間至下週二 5/9 中午 12:00!
歡迎大家一起發想,請直接在共筆上提出你的點子 :raised_hands:
https://g0v.hackmd.io/@jothon/B1c_yyGNh
- Forwarded from #general
- 2023-05-05 09:55:19
ronnywang
2023-05-09 22:50:54
真的假的?!
Peter
2023-05-09 23:23:40
真的假的?!
蛤?真的假的?
mrorz
2023-05-10 14:28:22
真的假的
Carmen
2023-05-11 17:53:48
好耶!真的假的 🙌
ronnywang
22:50:54
真的假的?!
Peter
23:23:40
真的假的?!
2023-05-10
cai
00:05:11
蛤?真的假的?
mrorz
14:27:29
mrorz
14:27:29
~本日~ *週四(明天!)*開會議程
https://g0v.hackmd.io/@cofacts/meetings/%2FjoEUsABVRr2aMQqD-Z8ixQ
https://g0v.hackmd.io/@cofacts/meetings/%2FjoEUsABVRr2aMQqD-Z8ixQ
mrorz
14:27:50
好像是,可以細察
mrorz
14:28:22
真的假的
nonumpa
14:31:18
@bil 這禮拜是要改禮拜四晚上開會嗎?
bil
14:34:54
是喔
mrorz
14:54:20
抱歉,是明天議程
ronnywang
15:17:23
變成還是可以做 Facebook login ,但是抓不到 email
2023-05-11
Carmen
17:53:48
好耶!真的假的 🙌
2023-05-12
mrorz
03:01:03
Google I/O 上 Cofacts 可以用(嗎)的新玩具
Enterprise search: 可以搜尋自有 dataset、有 semantic search (自動 embedding + indexing + retireval)、並分析出處 https://www.youtube.com/watch?v=HD_xreaLKb4
• 若他的 embedding 跨語言,那或許可以直接做個 semantic search for all fact checking websites,丟中文謠言進去,在 embedding space 裡找出接近的英文 rumors & fact check
• 想想 2016 年的「真的假的 LINE bot」,但這次不再搜到內容農場
Enterprise search: 可以搜尋自有 dataset、有 semantic search (自動 embedding + indexing + retireval)、並分析出處 https://www.youtube.com/watch?v=HD_xreaLKb4
• 若他的 embedding 跨語言,那或許可以直接做個 semantic search for all fact checking websites,丟中文謠言進去,在 embedding space 裡找出接近的英文 rumors & fact check
• 想想 2016 年的「真的假的 LINE bot」,但這次不再搜到內容農場
mrorz
03:01:03
Google I/O 上 Cofacts 可以用(嗎)的新玩具
Enterprise search: 可以搜尋自有 dataset、有 semantic search (自動 embedding + indexing + retireval)、並分析出處 https://www.youtube.com/watch?v=HD_xreaLKb4
• 若他的 embedding 跨語言,那或許可以直接做個 semantic search for all fact checking websites,丟中文謠言進去,在 embedding space 裡找出接近的英文 rumors & fact check
• 想想 2016 年的「真的假的 LINE bot」,但這次不再搜到內容農場
Enterprise search: 可以搜尋自有 dataset、有 semantic search (自動 embedding + indexing + retireval)、並分析出處 https://www.youtube.com/watch?v=HD_xreaLKb4
• 若他的 embedding 跨語言,那或許可以直接做個 semantic search for all fact checking websites,丟中文謠言進去,在 embedding space 裡找出接近的英文 rumors & fact check
• 想想 2016 年的「真的假的 LINE bot」,但這次不再搜到內容農場
- ❤️4
mrorz
03:36:58
我發現 TFC 跟 MyGoPen 的查核報告有更新,所以就寫了回應。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
2023-05-14
mrorz
00:07:41
Google I/O keynote 提到 AI 與 misinformation
https://youtu.be/cNfINi5CNbY?t=4346
新功能:
• Google image search 未來幾個月會加入「第一次找到此訊息的地方與時間」、「其他用到此圖之處」
• 若已知某圖帶有 AI generated metadata,image search 也會標注這是 Ai generated
https://youtu.be/cNfINi5CNbY?t=4346
新功能:
• Google image search 未來幾個月會加入「第一次找到此訊息的地方與時間」、「其他用到此圖之處」
• 若已知某圖帶有 AI generated metadata,image search 也會標注這是 Ai generated
mrorz
00:07:41
Google I/O keynote 提到 AI 與 misinformation
https://youtu.be/cNfINi5CNbY?t=4346
新功能:
• Google image search 未來幾個月會加入「第一次找到此訊息的地方與時間」、「其他用到此圖之處」
• 若已知某圖帶有 AI generated metadata,image search 也會標注這是 Ai generated
https://youtu.be/cNfINi5CNbY?t=4346
新功能:
• Google image search 未來幾個月會加入「第一次找到此訊息的地方與時間」、「其他用到此圖之處」
• 若已知某圖帶有 AI generated metadata,image search 也會標注這是 Ai generated
- 1
- 👍1
2023-05-15
cai
14:25:08
https://cofacts.tw/article/by006xiuxpcw
原文只有一句公司名稱,chatgpt 把整個故事掰出來了www
原文只有一句公司名稱,chatgpt 把整個故事掰出來了www
mrorz
2023-05-15 17:41:19
hallucination 好煩囧
mrorz
2023-05-15 17:41:41
來看看不同 temperature
mrorz
2023-05-15 17:44:19
啊
mrorz
2023-05-15 17:44:33
這是 4 月初還沒調過的版本 wwww
mrorz
2023-05-15 17:48:03
我來重生一下 prompt
mrorz
2023-05-15 17:54:10
無法理解負面評價在哪
cai
14:25:08
https://cofacts.tw/article/by006xiuxpcw
原文只有一句公司名稱,chatgpt 把整個故事掰出來了www
原文只有一句公司名稱,chatgpt 把整個故事掰出來了www
- 🤖2
mrorz
2023-05-15 17:41:19
hallucination 好煩囧
mrorz
2023-05-15 17:41:41
來看看不同 temperature
mrorz
2023-05-15 17:44:19
啊
mrorz
2023-05-15 17:44:33
這是 4 月初還沒調過的版本 wwww
mrorz
2023-05-15 17:48:03
我來重生一下 prompt
mrorz
2023-05-15 17:54:10
無法理解負面評價在哪
mrorz
17:41:19
hallucination 好煩囧
mrorz
17:41:41
來看看不同 temperature
mrorz
17:44:19
啊
mrorz
17:44:33
這是 4 月初還沒調過的版本 wwww
mrorz
17:48:03
我來重生一下 prompt
mrorz
17:54:10
無法理解負面評價在哪
ichieh
18:21:43
在鄉下陪奶奶幾天,奶奶很喜歡看一個電視台在罵執政黨的節目。
看到他們用這個新聞在打 https://www.google.com/amp/s/www.chinatimes.com/amp/newspapers/20230515000288-260118
總覺得他們的各種論述都非常似是而非,簡化脈絡,但像這種可能也不是我了解的議題,好像很難跟阿嬤辯論哪裡是真的哪裡是假的。
(這節目本身是生技賣藥,但用唱歌、政論的方式增加受眾)
補上這個節目的 yt:https://youtube.com/@AntRed
看到他們用這個新聞在打 https://www.google.com/amp/s/www.chinatimes.com/amp/newspapers/20230515000288-260118
總覺得他們的各種論述都非常似是而非,簡化脈絡,但像這種可能也不是我了解的議題,好像很難跟阿嬤辯論哪裡是真的哪裡是假的。
(這節目本身是生技賣藥,但用唱歌、政論的方式增加受眾)
補上這個節目的 yt:https://youtube.com/@AntRed
mrorz
2023-05-15 19:18:56
Hmm 再生醫療法這一題還滿硬的,一般民眾應該很難有興趣,好奇奶奶看完之後的想法是什麼
ichieh
2023-05-15 19:20:34
他不只講這個,他接著再講行人地獄。奶奶不是當下會有反應,但是他是會在未來聊天的時候把他們給的立場變成他自己的知識去跟別人講。所以我才覺得可怕,感覺很好把想法傳遞給很多老人
mrorz
2023-05-15 19:21:03
執政黨與廠商利益 v.s. 專家意見確實是可受公評的事項,只要不要太快導向到針對現代醫療的陰謀論應該就可以
mrorz
2023-05-15 19:26:32
那奶奶會把這些影片分享給朋友嗎
還是就自己看看這樣
還是就自己看看這樣
ichieh
2023-05-15 19:27:27
奶奶不會用手機 所以至少不會快速傳遞出去,只有跟朋友講電話可能會講。
ichieh
2023-05-15 19:27:55
但就是這個公司應該超多老人受眾,想一想覺得蠻可怕的,他的歌曲超級刻薄。
ichieh
2023-05-15 19:28:43
有種擔心阿嬤被教壞的感覺XDDDD
https://youtu.be/DIrNA8mVIQA
https://youtu.be/DIrNA8mVIQA
mrorz
2023-05-15 19:30:25
ichieh
2023-05-15 19:30:42
很扯!! 他們生技公司感覺賺超多的
mrorz
2023-05-15 19:35:01
好奇 2008 - 2016 年時這個節目長怎樣
ichieh
18:21:43
在鄉下陪奶奶幾天,奶奶很喜歡看一個電視台在罵執政黨的節目。
看到他們用這個新聞在打 https://www.google.com/amp/s/www.chinatimes.com/amp/newspapers/20230515000288-260118
總覺得他們的各種論述都非常似是而非,簡化脈絡,但像這種可能也不是我了解的議題,好像很難跟阿嬤辯論哪裡是真的哪裡是假的。
(這節目本身是生技賣藥,但用唱歌、政論的方式增加受眾)
補上這個節目的 yt:https://youtube.com/@AntRed
看到他們用這個新聞在打 https://www.google.com/amp/s/www.chinatimes.com/amp/newspapers/20230515000288-260118
總覺得他們的各種論述都非常似是而非,簡化脈絡,但像這種可能也不是我了解的議題,好像很難跟阿嬤辯論哪裡是真的哪裡是假的。
(這節目本身是生技賣藥,但用唱歌、政論的方式增加受眾)
補上這個節目的 yt:https://youtube.com/@AntRed
mrorz
2023-05-15 19:18:56
Hmm 再生醫療法這一題還滿硬的,一般民眾應該很難有興趣,好奇奶奶看完之後的想法是什麼
ichieh
2023-05-15 19:20:34
他不只講這個,他接著再講行人地獄。奶奶不是當下會有反應,但是他是會在未來聊天的時候把他們給的立場變成他自己的知識去跟別人講。所以我才覺得可怕,感覺很好把想法傳遞給很多老人
mrorz
2023-05-15 19:21:03
執政黨與廠商利益 v.s. 專家意見確實是可受公評的事項,只要不要太快導向到針對現代醫療的陰謀論應該就可以
mrorz
2023-05-15 19:26:32
那奶奶會把這些影片分享給朋友嗎
還是就自己看看這樣
還是就自己看看這樣
ichieh
2023-05-15 19:27:27
奶奶不會用手機 所以至少不會快速傳遞出去,只有跟朋友講電話可能會講。
ichieh
2023-05-15 19:27:55
但就是這個公司應該超多老人受眾,想一想覺得蠻可怕的,他的歌曲超級刻薄。
ichieh
2023-05-15 19:28:43
有種擔心阿嬤被教壞的感覺XDDDD
https://youtu.be/DIrNA8mVIQA
https://youtu.be/DIrNA8mVIQA
mrorz
2023-05-15 19:30:25
ichieh
2023-05-15 19:30:42
很扯!! 他們生技公司感覺賺超多的
mrorz
2023-05-15 19:35:01
好奇 2008 - 2016 年時這個節目長怎樣
mrorz
19:18:56
Hmm 再生醫療法這一題還滿硬的,一般民眾應該很難有興趣,好奇奶奶看完之後的想法是什麼
ichieh
19:20:34
他不只講這個,他接著再講行人地獄。奶奶不是當下會有反應,但是他是會在未來聊天的時候把他們給的立場變成他自己的知識去跟別人講。所以我才覺得可怕,感覺很好把想法傳遞給很多老人
mrorz
19:21:03
執政黨與廠商利益 v.s. 專家意見確實是可受公評的事項,只要不要太快導向到針對現代醫療的陰謀論應該就可以
mrorz
19:26:32
那奶奶會把這些影片分享給朋友嗎
還是就自己看看這樣
還是就自己看看這樣
ichieh
19:27:27
奶奶不會用手機 所以至少不會快速傳遞出去,只有跟朋友講電話可能會講。
ichieh
19:27:55
但就是這個公司應該超多老人受眾,想一想覺得蠻可怕的,他的歌曲超級刻薄。
ichieh
19:28:43
有種擔心阿嬤被教壞的感覺XDDDD
https://youtu.be/DIrNA8mVIQA
https://youtu.be/DIrNA8mVIQA
mrorz
19:30:25
ichieh
19:30:42
很扯!! 他們生技公司感覺賺超多的
mrorz
19:35:01
好奇 2008 - 2016 年時這個節目長怎樣
2023-05-16
fly
08:04:51
好奇有沒有人會邊讀邊劃線與分享,這邊是fly閱讀留下的痕跡,或許對查証一些知識性問題有用 i.flyism.org
也歡迎一起搜集閱讀劃線,這個 LINE群有Bot做分散儲存。 r.flyism.org
也歡迎一起搜集閱讀劃線,這個 LINE群有Bot做分散儲存。 r.flyism.org
fly
08:04:51
好奇有沒有人會邊讀邊劃線與分享,這邊是fly閱讀留下的痕跡,或許對查証一些知識性問題有用 i.flyism.org
也歡迎一起搜集閱讀劃線,這個 LINE群有Bot做分散儲存。 r.flyism.org
也歡迎一起搜集閱讀劃線,這個 LINE群有Bot做分散儲存。 r.flyism.org
mrorz
11:48:18
Replied to a thread: 2023-05-08 15:33:25
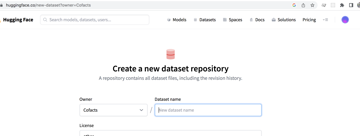
在 HuggingFace 上面開好了 Organization
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
現在要想 dataset 名稱
希望有個做查核的研究者可以搜尋得到的 dataset 名字
- ❤️1
- 👍1
mrorz
11:48:45
gary96302000.eecs96
11:49:07
確實
gary96302000.eecs96
11:49:26
有名的 dataset 都是因為有名的 model 或是比賽才紅的
gary96302000.eecs96
11:49:42
ㄎ ㄎ
mrorz
11:50:30
dataset 一夕爆紅 www
mrorz
11:50:55
`im-messages-and-crowd-sourced-fact-checks` 這種名字不好嗎
mrorz
11:51:04
是不是會翻車
因為很難 cite
因為很難 cite
gary96302000.eecs96
11:51:12
恩
mrorz
11:51:21
寫在 paper 裡的時候會佔一行
gary96302000.eecs96
11:51:22
通常都是寫在paper 裡
gary96302000.eecs96
11:51:26
嘿啊
gary96302000.eecs96
11:51:31
都會用縮寫
mrorz
11:51:41
但我 title 就叫 Cofacts data
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
只是 URL 長 im-messages-and-crowd-sourced-fact-checks
gary96302000.eecs96
11:51:45
什麼 MNIST CIFAR
mrorz
11:51:55
很難懂耶這些縮寫
gary96302000.eecs96
11:52:02
恩啊
gary96302000.eecs96
11:52:08
縮寫通常都看不出來意義
mrorz
11:53:16
gary96302000.eecs96
11:54:12
我最近有在 follow 的一個 open source project:https://github.com/LAION-AI/Open-Assistant
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
https://projects.laion.ai/Open-Assistant/docs/data/datasets
https://huggingface.co/datasets/OpenAssistant/oasst1
gary96302000.eecs96
11:54:23
oasst1
gary96302000.eecs96
11:54:32
也是完全不知道是什麼
gary96302000.eecs96
11:55:43
感覺 url 跟組織/專案名稱一樣的話不太好 通常好像不會這麼取
mrorz
11:56:31
目前在 github 上長這樣 https://github.com/cofacts/opendata
gary96302000.eecs96
11:57:04
我猜大原則就是 specific/clear
gary96302000.eecs96
11:57:11
這樣更直接一些
mrorz
11:58:03
那就 `cofacts/archive`
或 `cofacts/im-fact-check-archive`
或 `cofacts/im-fact-check-archive`
gary96302000.eecs96
11:58:41
im 的意思是什麼啊 好奇問個
mrorz
11:58:51
instant message?
mrorz
11:59:00
看來不是個常用字
mrorz
11:59:26
可能換個 msg-fact-check-archive
mrorz
11:59:36
或就 archive
gary96302000.eecs96
11:59:55
這個數量有多少筆
mrorz
12:00:50
會成長,所以z;4gj4xu;4lc3vu;4u,3ej94ej94
gary96302000.eecs96
12:00:52
歐歐
mrorz
12:01:21
而且會有很多 CSV (訊息、回應、feedback 等等)
mrorz
12:01:53
不然 msg-fact-check-100k 聽起來滿威
mrorz
12:02:15
在 200k 的時候再改名就好(?
gary96302000.eecs96
12:02:40
那如果是我的話 我會這樣取 `line-msg-fact-check-110k-tw`
gary96302000.eecs96
12:02:47
-tw 可加可不佳
mrorz
12:03:47
100k 感覺比較不用一直換名字 XD
因為訊息會一直長
因為訊息會一直長
gary96302000.eecs96
12:03:55
嗯嗯
gary96302000.eecs96
12:03:56
也行
mrorz
12:03:59
但從 100k ~ 200k 應該要數年
mrorz
12:04:07
dataset 可以換名字嗎之後
mrorz
12:04:16
還是 200k 的時候直接上傳新的
gary96302000.eecs96
12:04:33
上傳新的感覺更好
gary96302000.eecs96
12:04:42
不知道到時候格式什麼的會不會改變
gary96302000.eecs96
12:05:07
或是你100k上傳之後 會開始收到使用人給的回饋
mrorz
12:05:08
原來如此
gary96302000.eecs96
12:05:15
那你可能就會在 200k 做修改
mrorz
12:05:22
但舊的版本會有人一直用嗎
mrorz
12:05:30
就是舊的留存會有意義嗎
gary96302000.eecs96
12:05:31
不見得 看好不好用
gary96302000.eecs96
12:05:46
如果有人要 benchmark 那應該會有用
mrorz
12:05:52
好喔
gary96302000.eecs96
12:06:23
因為現在大家也漸漸意識到資料質量比數量重要的多
mrorz
12:06:40
但 hugging face dataset 本身沒有 versioning 嗎
我看他背後是 git lfs
我看他背後是 git lfs
gary96302000.eecs96
12:07:26
應該有versioning
gary96302000.eecs96
12:08:02
嗯嗯
gary96302000.eecs96
12:09:25
我指的比較像是 資料跟前一版 有著很大程度的不同 這種 例如說有先幫他們做了很多過濾 處理 分類資料
gary96302000.eecs96
12:09:58
那就比較適合另外開一個
gary96302000.eecs96
12:10:25
如果單純只是數量上的增加 那在原本的應該就行了
mrorz
12:15:53
好奇加了 100k 大家會比較想用嗎
還是沒加也 ok
還是沒加也 ok
gary96302000.eecs96
12:16:15
在意訓練資料數量的人就會想
gary96302000.eecs96
12:17:56
大部分是都沒加就是了 但這通常都是有名的work或是org做的
mrorz
12:18:32
我先加好了
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
可能之後會放個有圖片與影片的版本(這樣 dataset 會很大就是了)再更新名字
mrorz
12:19:18
話說 dataset 含有圖片跟影片的話不會超大嗎
gary96302000.eecs96
12:19:41
會歐
gary96302000.eecs96
12:21:07
不過影像的資料集
gary96302000.eecs96
12:21:12
好像在上面很少就是了
gary96302000.eecs96
13:14:44
嗯嗯 那個在search filter 也有的樣子
gary96302000.eecs96
13:15:13
不過一般人通常不會直接這樣搜(?
mrorz
13:39:22
但我有一堆 csv
mrorz
13:39:36
他好像只顯示 analytics.csv 的內容(會自己解 zip 就是了)
mrorz
13:40:14
這樣如果 python 這裡呼叫 `load_dataset`
是不是只會回傳 analytics.csv 呀囧
是不是只會回傳 analytics.csv 呀囧
gary96302000.eecs96
15:33:58
科科
2023-05-17
mrorz
13:41:47
HackMD
# Cofacts 會議記錄 ## 2023 - [20230517 會議記錄](/hn7Zy2X1QKuM8Kb5K6d4pA) - [20230511 會議記錄](/joEUsABVRr2a
cai
13:47:51
chatgpt 不能辨識民國跟西元,加減還算錯 😆
https://cofacts.tw/article/2ift587i48415
> 訊息中提到的日期是112年5月15日,但現在是2023年5月,這兩個日期相差了111年,因此需要懷疑訊息的真實性。
https://cofacts.tw/article/2ift587i48415
> 訊息中提到的日期是112年5月15日,但現在是2023年5月,這兩個日期相差了111年,因此需要懷疑訊息的真實性。
mrorz
2023-05-17 13:49:25
ChatGPT: 2023 - 112 = 111 似乎不是唯一解
gary96302000.eecs96
2023-05-17 14:08:23
數字一直都是不太行的地方 哈哈
mrorz
2023-05-20 01:26:33
cai
13:47:51
chatgpt 不能辨識民國跟西元 😆
https://cofacts.tw/article/2ift587i48415
> 訊息中提到的日期是112年5月15日,但現在是2023年5月,這兩個日期相差了111年,因此需要懷疑訊息的真實性。
https://cofacts.tw/article/2ift587i48415
> 訊息中提到的日期是112年5月15日,但現在是2023年5月,這兩個日期相差了111年,因此需要懷疑訊息的真實性。
mrorz
2023-05-17 13:49:25
ChatGPT: 2023 - 112 = 111 似乎不是唯一解
gary96302000.eecs96
2023-05-17 14:08:23
數字一直都是不太行的地方 哈哈
mrorz
2023-05-20 01:26:33
mrorz
13:47:59
XDDDDD
mrorz
13:47:59
XDDDDD
mrorz
13:49:25
ChatGPT: 2023 - 112 = 111 似乎不是唯一解
gary96302000.eecs96
14:08:23
數字一直都是不太行的地方 哈哈
2023-05-18
cai
13:52:25
#tw-ly-and-council 在研究Whisper 轉逐字稿,cofacts網站的謠言通常是五分鐘內的影片,好像也可以研究?
ronnywang
2023-05-18 14:07:42
我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
gary96302000.eecs96
2023-05-18 14:51:10
如果要的話也可以蹭 Google API 每月有 60 分鐘免費的額度
gary96302000.eecs96
2023-05-18 14:51:15
mrorz
2023-05-18 15:35:39
有的,圖像 OCR 與影音逐字稿在這裡有規劃過,也有進行過 cost estimation,還沒有人力執行 QQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
mrorz
2023-05-18 15:38:21
對 Cofacts 來說,因為要轉逐字稿的時機是有影音訊息送進來這件事(即時轉逐字稿拿去查文字),跟 #tw-ly-and-council 這種批次轉換不同,如果要自己 host Whisper 就要一直開著一台 GPU 機器,非常花錢,也要花精力管機器。因此 cost estimation 裡面是直接呼叫 OpenAI 的 Whisper API。
gary96302000.eecs96
2023-05-18 15:39:14
好奇問個 Whisper 跟 Google 的哪一個準啊
mrorz
2023-05-18 15:39:31
沒比過耶
gary96302000.eecs96
2023-05-18 15:39:37
歐歐
ronnywang
2023-05-18 15:39:53
感受上好像 whisper 比 google 準,但沒有準確試過
gary96302000.eecs96
2023-05-18 15:40:06
另外我怎麼印象中 台灣好像有類似的服務 AILabs 的
mrorz
2023-05-18 15:40:14
但我在 cost estimation 時,算到我們要轉換得分鐘數遠大於 google API 的 60min,所以應該會考慮 whisper 先
gary96302000.eecs96
2023-05-18 15:40:22
交大好像某個團隊也有做類似的東西 以前在新聞有看過
gary96302000.eecs96
2023-05-18 15:40:34
只是準確率都不知道怎樣
mrorz
2023-05-18 15:40:49
交大的好像有拿來轉有話好說
ronnywang
2023-05-18 15:41:18
也許 whisper 也可以群眾外包,讓願意貢獻算力的人只要跑那隻程式,就可以幫忙把影片算逐字稿回傳
mrorz
2023-05-18 15:41:52
Crowdsourced transcript 也在規劃中而且 @nonuma 正在做 XD
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
ronnywang
2023-05-18 15:41:57
目前cofacts一天大概會收集到幾分鐘的影片?
gary96302000.eecs96
2023-05-18 15:42:32
要免費到極致的話有一招我也會用 就是把資料放在一個 shared Google drive 訂一個更新的 naming rule 或什麼的
gary96302000.eecs96
2023-05-18 15:42:40
然後 colab 直接蹭起來
mrorz
2023-05-18 15:42:48
> 目前cofacts一天大概會收集到幾分鐘的影片?
資料庫沒存長度,所以我是用 5min 算
資料庫沒存長度,所以我是用 5min 算
gary96302000.eecs96
2023-05-18 15:42:59
轉好的存回去 shared drive
gary96302000.eecs96
2023-05-18 15:43:13
然後再抓回來這樣
gary96302000.eecs96
2023-05-18 15:43:29
假設這個服務不用即時性 那就可以考慮
ronnywang
2023-05-18 15:44:00
如果 cofacts 端已經有 API 可以取得還未處理的影音網址,我可能可以幫忙寫在 mac 上 local 幫忙處理上傳的程式
mrorz
2023-05-18 15:46:08
> 我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
gary96302000.eecs96
2023-05-18 15:46:29
whisper 不支援GPU 嗎?
mrorz
2023-05-18 15:46:48
支援,我只是想測他能不能跑在便宜的 CPU 機器上
gary96302000.eecs96
2023-05-18 15:46:56
歐歐
gary96302000.eecs96
2023-05-18 15:47:23
他模型架構是什麼
gary96302000.eecs96
2023-05-18 15:47:58
如果是 transformer based 的話 那 optimized 過,可以在 CPU 上面跑得嚇嚇叫
ronnywang
2023-05-18 15:48:58
我沒仔細研究,不過好像有看到文章說 whisper.cpp 在 mac 上只會用到 cpu ,還不支援 gpu ,但是有對 mac cpu 優化所以速度還滿快的
gary96302000.eecs96
2023-05-18 15:49:08
看起來好像是
mrorz
2023-05-18 15:49:32
所以是 whisper.cpp 有把原版 whisper 拿來 optimize 嗎
gary96302000.eecs96
2023-05-18 15:49:40
不知道噎
mrorz
2023-05-18 15:49:52
我在 colab 上測的時候是用 openai 提供的 pip package
gary96302000.eecs96
2023-05-18 15:49:55
語音的模型我沒研究過
ronnywang
2023-05-18 15:50:22
Note that it currently does not work on GPU yet (CPU only) but is optimized for Apple silicon.
gary96302000.eecs96
2023-05-18 15:50:22
但是語言模型的話 如果要 serve 都會做這部
mrorz
2023-05-18 15:50:52
原來是 apple silicon optimized
mrorz
2023-05-18 15:50:57
我的所有 mac 都是 intel XD
gary96302000.eecs96
2023-05-18 15:51:04
我的也是
gary96302000.eecs96
2023-05-18 15:51:06
顆顆
gary96302000.eecs96
2023-05-18 15:51:12
該買M系列了?
mrorz
2023-05-18 15:54:09
> 如果 cofacts 端已經有 API 可以取得還未處理的影音網址以及處理完上傳的 API,我可能可以幫忙
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
mrorz
2023-05-18 15:54:35
> 該買M系列了?
可能等我舊電腦用 6 年之後再說 (?
可能等我舊電腦用 6 年之後再說 (?
ronnywang
2023-05-18 15:56:41
哈哈,好,我本來想在 ivod 實作利用大家電腦群眾 whisper ,但後來發現我自己一台電腦就夠了,沒地方實作這個 XD
kiang
2023-05-18 17:31:30
其實 colab 提供的免費主機一般就比自己電腦跑快很多了
mrorz
2023-05-18 20:17:48
colab 還可以用手機查看執行進度
(只是手機上很醜 XD)
(只是手機上很醜 XD)
cai
13:52:25
#tw-ly-and-council 在研究Whisper 轉逐字稿,cofacts網站的謠言通常是五分鐘內的影片,好像也可以研究?
ronnywang
2023-05-18 14:07:42
我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
gary96302000.eecs96
2023-05-18 14:51:10
如果要的話也可以蹭 Google API 每月有 60 分鐘免費的額度
gary96302000.eecs96
2023-05-18 14:51:15
mrorz
2023-05-18 15:35:39
有的,圖像 OCR 與影音逐字稿在這裡有規劃過,也有進行過 cost estimation,還沒有人力執行 QQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
mrorz
2023-05-18 15:38:21
對 Cofacts 來說,因為要轉逐字稿的時機是有影音訊息送進來這件事(即時轉逐字稿拿去查文字),跟 #tw-ly-and-council 這種批次轉換不同,如果要自己 host Whisper 就要一直開著一台 GPU 機器,非常花錢,也要花精力管機器。因此 cost estimation 裡面是直接呼叫 OpenAI 的 Whisper API。
gary96302000.eecs96
2023-05-18 15:39:14
好奇問個 Whisper 跟 Google 的哪一個準啊
mrorz
2023-05-18 15:39:31
沒比過耶
gary96302000.eecs96
2023-05-18 15:39:37
歐歐
ronnywang
2023-05-18 15:39:53
感受上好像 whisper 比 google 準,但沒有準確試過
gary96302000.eecs96
2023-05-18 15:40:06
另外我怎麼印象中 台灣好像有類似的服務 AILabs 的
mrorz
2023-05-18 15:40:14
但我在 cost estimation 時,算到我們要轉換得分鐘數遠大於 google API 的 60min,所以應該會考慮 whisper 先
gary96302000.eecs96
2023-05-18 15:40:22
交大好像某個團隊也有做類似的東西 以前在新聞有看過
gary96302000.eecs96
2023-05-18 15:40:34
只是準確率都不知道怎樣
mrorz
2023-05-18 15:40:49
交大的好像有拿來轉有話好說
ronnywang
2023-05-18 15:41:18
也許 whisper 也可以群眾外包,讓願意貢獻算力的人只要跑那隻程式,就可以幫忙把影片算逐字稿回傳
mrorz
2023-05-18 15:41:52
Crowdsourced transcript 也在規劃中而且 @nonuma 正在做 XD
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
ronnywang
2023-05-18 15:41:57
目前cofacts一天大概會收集到幾分鐘的影片?
gary96302000.eecs96
2023-05-18 15:42:32
要免費到極致的話有一招我也會用 就是把資料放在一個 shared Google drive 訂一個更新的 naming rule 或什麼的
gary96302000.eecs96
2023-05-18 15:42:40
然後 colab 直接蹭起來
mrorz
2023-05-18 15:42:48
> 目前cofacts一天大概會收集到幾分鐘的影片?
資料庫沒存長度,所以我是用 5min 算
資料庫沒存長度,所以我是用 5min 算
gary96302000.eecs96
2023-05-18 15:42:59
轉好的存回去 shared drive
gary96302000.eecs96
2023-05-18 15:43:13
然後再抓回來這樣
gary96302000.eecs96
2023-05-18 15:43:29
假設這個服務不用即時性 那就可以考慮
ronnywang
2023-05-18 15:44:00
如果 cofacts 端已經有 API 可以取得還未處理的影音網址,我可能可以幫忙寫在 mac 上 local 幫忙處理上傳的程式
mrorz
2023-05-18 15:46:08
> 我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
gary96302000.eecs96
2023-05-18 15:46:29
whisper 不支援GPU 嗎?
mrorz
2023-05-18 15:46:48
支援,我只是想測他能不能跑在便宜的 CPU 機器上
gary96302000.eecs96
2023-05-18 15:46:56
歐歐
gary96302000.eecs96
2023-05-18 15:47:23
他模型架構是什麼
gary96302000.eecs96
2023-05-18 15:47:58
如果是 transformer based 的話 那 optimized 過,可以在 CPU 上面跑得嚇嚇叫
ronnywang
2023-05-18 15:48:58
我沒仔細研究,不過好像有看到文章說 whisper.cpp 在 mac 上只會用到 cpu ,還不支援 gpu ,但是有對 mac cpu 優化所以速度還滿快的
gary96302000.eecs96
2023-05-18 15:49:08
看起來好像是
mrorz
2023-05-18 15:49:32
所以是 whisper.cpp 有把原版 whisper 拿來 optimize 嗎
gary96302000.eecs96
2023-05-18 15:49:40
不知道噎
mrorz
2023-05-18 15:49:52
我在 colab 上測的時候是用 openai 提供的 pip package
gary96302000.eecs96
2023-05-18 15:49:55
語音的模型我沒研究過
ronnywang
2023-05-18 15:50:22
Note that it currently does not work on GPU yet (CPU only) but is optimized for Apple silicon.
gary96302000.eecs96
2023-05-18 15:50:22
但是語言模型的話 如果要 serve 都會做這部
mrorz
2023-05-18 15:50:52
原來是 apple silicon optimized
mrorz
2023-05-18 15:50:57
我的所有 mac 都是 intel XD
gary96302000.eecs96
2023-05-18 15:51:04
我的也是
gary96302000.eecs96
2023-05-18 15:51:06
顆顆
gary96302000.eecs96
2023-05-18 15:51:12
該買M系列了?
mrorz
2023-05-18 15:54:09
> 如果 cofacts 端已經有 API 可以取得還未處理的影音網址以及處理完上傳的 API,我可能可以幫忙
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
mrorz
2023-05-18 15:54:35
> 該買M系列了?
可能等我舊電腦用 6 年之後再說 (?
可能等我舊電腦用 6 年之後再說 (?
ronnywang
2023-05-18 15:56:41
哈哈,好,我本來想在 ivod 實作利用大家電腦群眾 whisper ,但後來發現我自己一台電腦就夠了,沒地方實作這個 XD
kiang
2023-05-18 17:31:30
其實 colab 提供的免費主機一般就比自己電腦跑快很多了
mrorz
2023-05-18 20:17:48
colab 還可以用手機查看執行進度
(只是手機上很醜 XD)
(只是手機上很醜 XD)
ronnywang
14:07:42
我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
gary96302000.eecs96
14:51:10
如果要的話也可以蹭 Google API 每月有 60 分鐘免費的額度
gary96302000.eecs96
14:51:15
mrorz
15:35:39
有的,圖像 OCR 與影音逐字稿在這裡有規劃過,也有進行過 cost estimation,還沒有人力執行 QQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ
mrorz
15:38:21
對 Cofacts 來說,因為要轉逐字稿的時機是有影音訊息送進來這件事(即時轉逐字稿拿去查文字),跟 #tw-ly-and-council 這種批次轉換不同,如果要自己 host Whisper 就要一直開著一台 GPU 機器,非常花錢,也要花精力管機器。因此 cost estimation 裡面是直接呼叫 OpenAI 的 Whisper API。
gary96302000.eecs96
15:39:14
好奇問個 Whisper 跟 Google 的哪一個準啊
mrorz
15:39:31
沒比過耶
gary96302000.eecs96
15:39:37
歐歐
ronnywang
15:39:53
感受上好像 whisper 比 google 準,但沒有準確試過
gary96302000.eecs96
15:40:06
另外我怎麼印象中 台灣好像有類似的服務 AILabs 的
mrorz
15:40:14
但我在 cost estimation 時,算到我們要轉換得分鐘數遠大於 google API 的 60min,所以應該會考慮 whisper 先
gary96302000.eecs96
15:40:22
交大好像某個團隊也有做類似的東西 以前在新聞有看過
gary96302000.eecs96
15:40:34
只是準確率都不知道怎樣
mrorz
15:40:49
交大的好像有拿來轉有話好說
ronnywang
15:41:18
也許 whisper 也可以群眾外包,讓願意貢獻算力的人只要跑那隻程式,就可以幫忙把影片算逐字稿回傳
mrorz
15:41:52
Crowdsourced transcript 也在規劃中而且 @nonuma 正在做 XD
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
https://g0v.hackmd.io/@cofacts/rd/%2FOhGIQzoxR5eF6audQuS_FQ
ronnywang
15:41:57
目前cofacts一天大概會收集到幾分鐘的影片?
gary96302000.eecs96
15:42:32
要免費到極致的話有一招我也會用 就是把資料放在一個 shared Google drive 訂一個更新的 naming rule 或什麼的
gary96302000.eecs96
15:42:40
然後 colab 直接蹭起來
mrorz
15:42:48
> 目前cofacts一天大概會收集到幾分鐘的影片?
資料庫沒存長度,所以我是用 5min 算
資料庫沒存長度,所以我是用 5min 算
gary96302000.eecs96
15:42:59
轉好的存回去 shared drive
gary96302000.eecs96
15:43:13
然後再抓回來這樣
gary96302000.eecs96
15:43:29
假設這個服務不用即時性 那就可以考慮
ronnywang
15:44:00
如果 cofacts 端已經有 API 可以取得還未處理的影音網址,我可能可以幫忙寫在 mac 上 local 幫忙處理上傳的程式
mrorz
15:46:08
> 我現在用 whisper.cpp + medium model ,透過我的 macbook air 2020 ,轉立法院 ivod 逐字稿的速度大概是 3:1 ,好像只有用 CPU 沒有用到 GPU
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
我之前在 colab 上試著開一台 CPU 機器來跑 whisper,每一個字都要跑好久耶
是 macbook 2020 CPU 的威力嗎
gary96302000.eecs96
15:46:29
whisper 不支援GPU 嗎?
mrorz
15:46:48
支援,我只是想測他能不能跑在便宜的 CPU 機器上
gary96302000.eecs96
15:46:56
歐歐
gary96302000.eecs96
15:47:23
他模型架構是什麼
gary96302000.eecs96
15:47:58
如果是 transformer based 的話 那 optimized 過,可以在 CPU 上面跑得嚇嚇叫
ronnywang
15:48:58
我沒仔細研究,不過好像有看到文章說 whisper.cpp 在 mac 上只會用到 cpu ,還不支援 gpu ,但是有對 mac cpu 優化所以速度還滿快的
gary96302000.eecs96
15:49:08
看起來好像是
mrorz
15:49:32
所以是 whisper.cpp 有把原版 whisper 拿來 optimize 嗎
gary96302000.eecs96
15:49:40
不知道噎
mrorz
15:49:52
我在 colab 上測的時候是用 openai 提供的 pip package
gary96302000.eecs96
15:49:55
語音的模型我沒研究過
ronnywang
15:50:22
Note that it currently does not work on GPU yet (CPU only) but is optimized for Apple silicon.
gary96302000.eecs96
15:50:22
但是語言模型的話 如果要 serve 都會做這部
mrorz
15:50:52
原來是 apple silicon optimized
mrorz
15:50:57
我的所有 mac 都是 intel XD
gary96302000.eecs96
15:51:04
我的也是
gary96302000.eecs96
15:51:06
顆顆
gary96302000.eecs96
15:51:12
該買M系列了?
mrorz
15:54:09
> 如果 cofacts 端已經有 API 可以取得還未處理的影音網址以及處理完上傳的 API,我可能可以幫忙
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
感謝感謝,但這裡還沒有這個 API
影音都在 gcs 上,但我有鎖 authentication 防盜連,所以用程式要拿有點麻煩,也還沒有做上傳的 API
對於現有的影音,我可能 colab(內建我的 authentication 所以可以拿得到 gcs)開 GPU 機器跑 openai 官方 whisper + google spreadsheet 處理
對於新的影音才會走 https://g0v.hackmd.io/@cofacts/rd/%2Fwkx286lmTDaFUpgRhnUawQ 裡面寫的
mrorz
15:54:35
> 該買M系列了?
可能等我舊電腦用 6 年之後再說 (?
可能等我舊電腦用 6 年之後再說 (?
ronnywang
15:56:41
哈哈,好,我本來想在 ivod 實作利用大家電腦群眾 whisper ,但後來發現我自己一台電腦就夠了,沒地方實作這個 XD
kiang
17:31:30
其實 colab 提供的免費主機一般就比自己電腦跑快很多了
mrorz
20:14:31
週三測的 LINE event to big query 把 bug 改掉 + 上 staging 了
https://github.com/cofacts/rumors-line-bot/pull/351/files
如果沒有踩到什麼問題,我想要早日上 production 之後再來跟 GA 對答案
https://github.com/cofacts/rumors-line-bot/pull/351/files
如果沒有踩到什麼問題,我想要早日上 production 之後再來跟 GA 對答案
mrorz
2023-05-19 04:22:05
上線之後發現
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
mrorz
2023-05-20 01:03:06
Fix that adds user ID
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
mrorz
20:14:31
週三測的 LINE event to big query 把 bug 改掉 + 上 staging 了
https://github.com/cofacts/rumors-line-bot/pull/351/files
如果沒有踩到什麼問題,我想要早日上 production 之後再來跟 GA 對答案
https://github.com/cofacts/rumors-line-bot/pull/351/files
如果沒有踩到什麼問題,我想要早日上 production 之後再來跟 GA 對答案
- 🙌1
mrorz
2023-05-19 04:22:05
上線之後發現
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
mrorz
2023-05-20 01:03:06
Fix that adds user ID
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
mrorz
20:17:48
colab 還可以用手機查看執行進度
(只是手機上很醜 XD)
(只是手機上很醜 XD)
2023-05-19
cai
01:26:19
https://cofacts.tw/article/0qTyI4gBpPlTXSoGtcEB
期待mygopen或TFC去買一排三罐的包裝來開箱 😆
期待mygopen或TFC去買一排三罐的包裝來開箱 😆
cai
01:26:19
https://cofacts.tw/article/0qTyI4gBpPlTXSoGtcEB
期待mygopen或TFC去買一排三罐的包裝來開箱 😆
期待mygopen或TFC去買一排三罐的包裝來開箱 😆
mrorz
04:07:05
影片裡面只開一罐是怎樣w
mrorz
04:22:05
Replied to a thread: 2023-05-18 20:14:31
上線之後發現
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
忘記紀錄 user ID 了,這樣分不出 user count / event count⋯⋯
mrorz
13:10:43
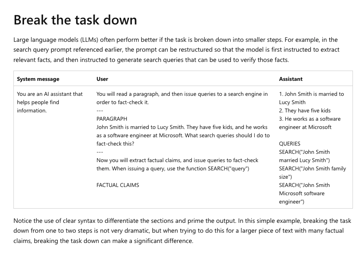
我發現微軟的 Prompt engineering techniques 教學裡的範例就是 fact check 耶 XD
https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/advanced-pr[…]pt-engineering?pivots=programming-language-chat-completions
對應到過去開會時聊過的 Scenario #4 claim extraction 與 Scenario #1 extended goal (search keyword generation)
後面段落把 search query 貼回給 LLM 的部分,就接近 Scenario #6 的 auto gpt 了
https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/advanced-pr[…]pt-engineering?pivots=programming-language-chat-completions
對應到過去開會時聊過的 Scenario #4 claim extraction 與 Scenario #1 extended goal (search keyword generation)
後面段落把 search query 貼回給 LLM 的部分,就接近 Scenario #6 的 auto gpt 了
learn.microsoft.com
Learn about the options for how to use prompt engineering with GPT-3, ChatGPT, and GPT-4 models
 1
1
mrorz
2023-05-19 13:14:50
btw 這份 guide 裡面有提到一個(我之前沒在吳恩達課程裡讀過的)新概念 recency bias, 並依此建議在 prompt 末段重複指令
之前 Cofacts 實作 hoax analysis 的時候,也確實是把實際指令放在網傳訊息之後
之前 Cofacts 實作 hoax analysis 的時候,也確實是把實際指令放在網傳訊息之後
mrorz
13:14:50
btw 這份 guide 裡面有提到一個(我之前沒在吳恩達課程裡讀過的)新概念 recency bias, 並依此建議在 prompt 末段重複指令
之前 Cofacts 實作 hoax analysis 的時候,也確實是把實際指令放在網傳訊息之後
之前 Cofacts 實作 hoax analysis 的時候,也確實是把實際指令放在網傳訊息之後
mrorz
14:16:59
原來 google 有 web entity detection 可以做以圖搜圖,丟 URL 就可以
https://cloud.google.com/vision/docs/detecting-web#detect_web_entities_with_a_remote_image
另外也有判斷 explicit content 的 API,也一樣丟 URL
https://cloud.google.com/vision/docs/detecting-safe-search#explicit_content_detection_on_a_remote_image
Pricing:
Web Detection = USD 3.5 per 1000 images;
Explicit content Detection = USD 1.5 per 1000 images (同 OCR)
都不太貴
而且這兩個只要做最後送進資料庫的圖就好,跟 OCR 每張不重複圖被傳進來問都要做完全不同
https://cloud.google.com/vision/docs/detecting-web#detect_web_entities_with_a_remote_image
另外也有判斷 explicit content 的 API,也一樣丟 URL
https://cloud.google.com/vision/docs/detecting-safe-search#explicit_content_detection_on_a_remote_image
Pricing:
Web Detection = USD 3.5 per 1000 images;
Explicit content Detection = USD 1.5 per 1000 images (同 OCR)
都不太貴
而且這兩個只要做最後送進資料庫的圖就好,跟 OCR 每張不重複圖被傳進來問都要做完全不同
 1
1
mrorz
14:16:59
原來 google 有 web entity detection 可以做以圖搜圖,丟 URL 就可以
https://cloud.google.com/vision/docs/detecting-web#detect_web_entities_with_a_remote_image
另外也有判斷 explicit content 的 API,也一樣丟 URL
https://cloud.google.com/vision/docs/detecting-safe-search#explicit_content_detection_on_a_remote_image
Pricing:
Web Detection = USD 3.5 per 1000 images;
Explicit content Detection = USD 1.5 per 1000 images (同 OCR)
都不太貴
https://cloud.google.com/vision/docs/detecting-web#detect_web_entities_with_a_remote_image
另外也有判斷 explicit content 的 API,也一樣丟 URL
https://cloud.google.com/vision/docs/detecting-safe-search#explicit_content_detection_on_a_remote_image
Pricing:
Web Detection = USD 3.5 per 1000 images;
Explicit content Detection = USD 1.5 per 1000 images (同 OCR)
都不太貴
mrorz
15:28:19
Elasticsearch document QA
https://www.elastic.co/blog/chatgpt-elasticsearch-openai-meets-private-data
https://www.elastic.co/blog/chatgpt-elasticsearch-openai-meets-private-data
mrorz
15:28:19
Elasticsearch document QA
https://www.elastic.co/blog/chatgpt-elasticsearch-openai-meets-private-data
https://www.elastic.co/blog/chatgpt-elasticsearch-openai-meets-private-data
2023-05-20
mrorz
01:03:06
Replied to a thread: 2023-05-18 20:14:31
Fix that adds user ID
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
• DB schema https://github.com/cofacts/rumors-db/pull/63
• LINE bot https://github.com/cofacts/rumors-line-bot/pull/352
2023-05-21
mrorz
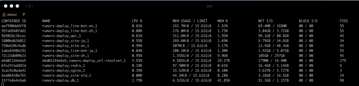
13:09:53
server 好像變很慢
mrorz
13:09:53
server 好像變很慢
mrorz
13:13:23
load 飆到 66
我印象中之前是 2 之類的⋯⋯
我印象中之前是 2 之類的⋯⋯
cai
13:46:11
用chrome開多個分頁還是會一直轉圈圈
mrorz
2023-05-21 13:47:27
網站效能好像一直很糟 QQ
mrorz
2023-05-21 13:50:39
但至少現在還打得開,跟今天出事之前差不多
我不會寫userscript,不然好想寫停止影片自動播放跟改成數字分頁的腳本 🥲
mrorz
2023-05-21 13:54:47
自動播放主要是 iOS 那裡有問題,比較好的方法應該是生成 preview image
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
現在網站速度慢主要是卡在點進去單篇文章的轉圈圈
mrorz
2023-05-21 14:13:40
方便提供螢幕錄影嗎
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
cai
13:46:11
用chrome開多個分頁還是會一直轉圈圈
mrorz
2023-05-21 13:47:27
網站效能好像一直很糟 QQ
mrorz
2023-05-21 13:50:39
但至少現在還打得開,跟今天出事之前差不多
我不會寫userscript,不然好想寫停止影片自動播放跟改成數字分頁的腳本 🥲
mrorz
2023-05-21 13:54:47
自動播放主要是 iOS 那裡有問題,比較好的方法應該是生成 preview image
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
現在網站速度慢主要是卡在點進去單篇文章的轉圈圈
mrorz
2023-05-21 14:13:40
方便提供螢幕錄影嗎
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
mrorz
13:47:27
網站效能好像一直很糟 QQ
mrorz
13:49:57
關於 LLM aid fact-checking Scenario #6 ,之前開會時提到的 AutoGPT 的時候有注意到他每一步有 thought、critique 等東西,背後可能是參考這些研究
• 【生成式AI】ChatGPT 可以自我反省! https://www.youtube.com/watch?v=m7dUFlX-yQI 提及的 paper:
◦ DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents https://arxiv.org/abs/2303.17071
◦ ReAct = Reason + Act https://arxiv.org/abs/2210.03629
◦ Reflexion https://arxiv.org/abs/2303.11366
• 讓 AI 做計劃然後自己運行自己 https://www.youtube.com/watch?v=eQNADlR0jSs
◦ Recursive Reprompting and Revision (Re3): https://arxiv.org/abs/2210.06774
• 【生成式AI】ChatGPT 可以自我反省! https://www.youtube.com/watch?v=m7dUFlX-yQI 提及的 paper:
◦ DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents https://arxiv.org/abs/2303.17071
◦ ReAct = Reason + Act https://arxiv.org/abs/2210.03629
◦ Reflexion https://arxiv.org/abs/2303.11366
• 讓 AI 做計劃然後自己運行自己 https://www.youtube.com/watch?v=eQNADlR0jSs
◦ Recursive Reprompting and Revision (Re3): https://arxiv.org/abs/2210.06774
mrorz
2023-05-30 15:32:13
https://github.com/aiwaves-cn/RecurrentGPT
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
mrorz
13:49:57
關於 LLM aid fact-checking Scenario #6 ,之前開會時提到的 AutoGPT 的時候有注意到他每一步有 thought、critique 等東西,背後可能是參考這些研究
• 【生成式AI】ChatGPT 可以自我反省! https://www.youtube.com/watch?v=m7dUFlX-yQI 提及的 paper:
◦ DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents https://arxiv.org/abs/2303.17071
◦ ReAct = Reason + Act https://arxiv.org/abs/2210.03629
◦ Reflexion https://arxiv.org/abs/2303.11366
• 讓 AI 做計劃然後自己運行自己 https://www.youtube.com/watch?v=eQNADlR0jSs
◦ Recursive Reprompting and Revision (Re3): https://arxiv.org/abs/2210.06774
• 【生成式AI】ChatGPT 可以自我反省! https://www.youtube.com/watch?v=m7dUFlX-yQI 提及的 paper:
◦ DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents https://arxiv.org/abs/2303.17071
◦ ReAct = Reason + Act https://arxiv.org/abs/2210.03629
◦ Reflexion https://arxiv.org/abs/2303.11366
• 讓 AI 做計劃然後自己運行自己 https://www.youtube.com/watch?v=eQNADlR0jSs
◦ Recursive Reprompting and Revision (Re3): https://arxiv.org/abs/2210.06774
mrorz
2023-05-30 15:32:13
https://github.com/aiwaves-cn/RecurrentGPT
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
mrorz
13:50:39
但至少現在還打得開,跟今天出事之前差不多
cai
13:51:32
我不會寫userscript,不然好想寫停止影片自動播放跟改成數字分頁的腳本 🥲
mrorz
13:54:47
自動播放主要是 iOS 那裡有問題,比較好的方法應該是生成 preview image
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
https://g0v.hackmd.io/QPTHTIGEQpGgyYrDxNOMCQ?view#%E5%BD%B1%E7%89%87%E8%87%AA%E5%8B%95%E6%92%AD%E6%94%BE-follow-up
數字分頁的部分因為這裡用 cursor based 所以比較難 QQ 但要做成 prev / next 是可以的
cai
14:07:38
現在網站速度慢主要是卡在點進去單篇文章的轉圈圈
mrorz
14:13:40
方便提供螢幕錄影嗎
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
錄影裡面只要網站的頁面就好
想要看習慣的使用方式(開新視窗 or 直接點進去)
以及實際會載入的時間長短
2023-05-24
mrorz
09:33:05
發現 ChatGPT 用我爬到的資訊直接命中正解,讚
https://cofacts.tw/article/jvyb9jl0p6jz
https://cofacts.tw/article/jvyb9jl0p6jz
mrorz
13:19:01
mrorz
13:19:01
mrorz
19:49:54
這一波 COVID 訊息真多,傳得比 COVID 本身還快
https://cofacts.tw/article/11v1l7c8llzz2
https://cofacts.tw/article/3q6v8qa4nh0ln
https://cofacts.tw/article/2bmiu4989jke5
https://cofacts.tw/article/3hewf583c9jzj
https://cofacts.tw/article/11v1l7c8llzz2
https://cofacts.tw/article/3q6v8qa4nh0ln
https://cofacts.tw/article/2bmiu4989jke5
https://cofacts.tw/article/3hewf583c9jzj
- 😅1
mrorz
2023-05-24 19:50:25
我家還有一堆解封前的快篩 XD
mrorz
19:49:54
這一波 COVID 訊息真多,傳得比 COVID 本身還快
https://cofacts.tw/article/11v1l7c8llzz2
https://cofacts.tw/article/3q6v8qa4nh0ln
https://cofacts.tw/article/2bmiu4989jke5
https://cofacts.tw/article/3hewf583c9jzj
https://cofacts.tw/article/11v1l7c8llzz2
https://cofacts.tw/article/3q6v8qa4nh0ln
https://cofacts.tw/article/2bmiu4989jke5
https://cofacts.tw/article/3hewf583c9jzj
mrorz
2023-05-24 19:50:25
我家還有一堆解封前的快篩 XD
mrorz
19:50:25
我家還有一堆解封前的快篩 XD
2023-05-30
mrorz
15:32:13
https://github.com/aiwaves-cn/RecurrentGPT
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
查核過程可能會需要 summarize 很多外部資料,並且生出查核回應
可以參考 RecurrentGPT 如何用 LLM 實作 LSTM
2023-05-31
mrorz
15:34:26
- 1
 1
1
mrorz
15:34:26
mrorz
20:45:19
過去頒布的 CoC for 小聚:https://www.facebook.com/legacy/notes/2046634208901731/