#cofacts
2023-03-01

cai
14:02:59
https://cofacts.tw/article/byl0kszte5zq
這篇有希望成為大亂鬥,因為搜尋`商城名稱+詐騙`這篇在第一頁
未公布內容的福袋 + 每次轉賣賺差價 + 用戶之間直接轉帳交易 + 要拉人進來
詐騙溫床?
https://www.dcard.tw/f/mood/p/241153775 dcard這篇是直接問派出所
https://www.ey.gov.tw/Page/DFB720D019CCCB0A/018c8620-8468-416a-bbc4-51570833173a 販售福袋有規定要公布內容
這篇有希望成為大亂鬥,因為搜尋`商城名稱+詐騙`這篇在第一頁
未公布內容的福袋 + 每次轉賣賺差價 + 用戶之間直接轉帳交易 + 要拉人進來
詐騙溫床?
https://www.dcard.tw/f/mood/p/241153775 dcard這篇是直接問派出所
https://www.ey.gov.tw/Page/DFB720D019CCCB0A/018c8620-8468-416a-bbc4-51570833173a 販售福袋有規定要公布內容
mrorz
2023-03-01 15:17:26
這個好神秘⋯⋯
mrorz
2023-03-01 15:21:26
所以這平台裡的福袋就是一種不走的 NFT 嗎
cai
14:02:59
https://cofacts.tw/article/byl0kszte5zq
這篇有希望成為大亂鬥,因為搜尋`商城名稱+詐騙`這篇在第一頁
未公布內容的福袋 + 每次轉賣賺差價 + 用戶之間直接轉帳交易 + 要拉人進來
詐騙溫床?
https://www.dcard.tw/f/mood/p/241153775 dcard這篇是直接問派出所
https://www.ey.gov.tw/Page/DFB720D019CCCB0A/018c8620-8468-416a-bbc4-51570833173a 販售福袋有規定要公布內容
這篇有希望成為大亂鬥,因為搜尋`商城名稱+詐騙`這篇在第一頁
未公布內容的福袋 + 每次轉賣賺差價 + 用戶之間直接轉帳交易 + 要拉人進來
詐騙溫床?
https://www.dcard.tw/f/mood/p/241153775 dcard這篇是直接問派出所
https://www.ey.gov.tw/Page/DFB720D019CCCB0A/018c8620-8468-416a-bbc4-51570833173a 販售福袋有規定要公布內容
Dcard
更新後續:平日在外縣市上班,在某天上班的時候爸爸突然line我說,把帳戶結清,沒有玩了,原因是不希望影響本業、跟小孩翻臉,所以我還沒回家在他面前打165,這件事情就結束了,我鬆了一口氣,在家的時候,我 - 詐騙,家庭
ey.gov.tw
零售業販售福袋定型化契約應記載及不得記載事項 定義:本事項所稱「福袋」,指企業經營者將一件以上商品或商品之兌換券加以包裹販售,而消費者無法於購買前與購買當時確定其內容物者。 壹、零售業販售福袋定型化契約應記載事項: 一、企業經營者資訊 企業經營者名稱、負責人、地址及消費者服務專線電話資訊 二、販售福袋辦法 販售福袋辦法應包含福袋販售之期間、數量、程序、購買限制。 三、全部福袋內容資訊 內容資訊應包括下列事項: (一)基本商品:商品之名稱、品牌、規格及數量。 (二)機率商品:除前款以外之商品,各該商品之名稱、品牌、規格、數量及購得之機率。 前項第二款之機率商品,須經具公信力之第三方見證人見證,並應公告該第三方見證人之資訊。 四、退換說明 福袋內瑕疵商品之退換貨方式。 五、應繳稅額 消費者應繳稅金之商品項目、商品價值及稅率。 六、公告方式 第二點之販售福袋辦法及第三點第一項第二款之機率商品內容資訊,應於福袋販售現場明顯處及企業經營者網站公告。 其他應記載事項應於福袋販售現場明顯處或企業經營者網站公告。 貳、零售業販售福袋定型化契約不得記載事項 一、不得記載企業經營者得片面變更契約內容。 二、不得記載商品瑕疵擔保責任之排除或限制規定。 三、不得記載廣告僅供參考。 四、不得記載排除或限制消費者保護法第四十七條或民事訴訟法第四百三十六條之九小額訴訟管轄法院之適用。 五、不得記載預先免除或限制契約終止或解除時,企業經營者應負之回復原狀及損害賠償責任。 六、不得記載違反其他法律強制禁止規定或為顯失公平或欺罔之事項。
mrorz
2023-03-01 15:17:26
這個好神秘⋯⋯
mrorz
2023-03-01 15:21:26
所以這平台裡的福袋就是一種不走的 NFT 嗎
mrorz
15:17:26
這個好神秘⋯⋯
mrorz
15:21:26
所以這平台裡的福袋就是一種不走的 NFT 嗎
mrorz
15:26:51
HackMD
# Cofacts 會議記錄 ## 2023 - [20230301 會議記錄](/zVyuEX5RS5uONLnucsxiYA) - [20230223 會議記錄](/r39Cc0RWT0GB
mrorz
17:12:24
ronnywang
2023-03-02 09:13:49
你是先知嗎 XD 知道昨天 Linode 要漲價嗎 XD
mrorz
2023-03-02 09:14:39
完全不知道 XDD
yhsiang
2023-03-02 12:27:31
@mrorz 真的假的!
mrorz
17:12:24
發現 hetzner 這家 VPS
平平 16GB ram 的機器,價格只要 30 歐元 / 月(美國)
我們現在在用的 linode 是 80 美元 / 月(可架在日本)
https://www.hetzner.com/cloud
平平 16GB ram 的機器,價格只要 30 歐元 / 月(美國)
我們現在在用的 linode 是 80 美元 / 月(可架在日本)
https://www.hetzner.com/cloud
ronnywang
2023-03-02 09:13:49
你是先知嗎 XD 知道昨天 Linode 要漲價嗎 XD
mrorz
2023-03-02 09:14:39
完全不知道 XDD
yhsiang
2023-03-02 12:27:31
@mrorz 真的假的!
2023-03-02
ronnywang
09:13:49
你是先知嗎 XD 知道昨天 Linode 要漲價嗎 XD
mrorz
09:14:39
完全不知道 XDD
yhsiang
12:27:31
@mrorz 真的假的!
cai
19:23:28
分類標籤如果是`不希望手動標記`或`改用其他`的分類,能直接在選項隱藏嗎?還是有人會亂標。
AI 標記應該沒那麼快,不到24小時就自動分類了?
https://cofacts.tw/article/arzzmql7uhcs
AI 標記應該沒那麼快,不到24小時就自動分類了?
https://cofacts.tw/article/arzzmql7uhcs
 1
1
mrorz
2023-03-03 10:52:37
AI 是每天跑沒錯
cai
19:23:28
分類標籤如果是`不希望手動標記`或`改用其他`的分類,能直接在選項隱藏嗎?還是有人會亂標。
AI 標記應該沒那麼快,不到24小時就自動分類了?
https://cofacts.tw/article/arzzmql7uhcs
AI 標記應該沒那麼快,不到24小時就自動分類了?
https://cofacts.tw/article/arzzmql7uhcs
mrorz
2023-03-03 10:52:37
AI 是每天跑沒錯
2023-03-03
mrorz
10:52:37
AI 是每天跑沒錯
2023-03-08
cai
23:27:39
https://cofacts.tw/article/__-BH4AMgB6gHqPegJ6h3qGfoN-gH4AfkB-AH4tXgP8
這張是107年4月警方拿來澄清的萬安演習時間 https://news.ltn.com.tw/news/life/breakingnews/2394289
但是107年5月國防部公布的不是這個時間 https://www.ettoday.net/news/20180518/1172361.htm
這個要怎麼寫啊XD
這張是107年4月警方拿來澄清的萬安演習時間 https://news.ltn.com.tw/news/life/breakingnews/2394289
但是107年5月國防部公布的不是這個時間 https://www.ettoday.net/news/20180518/1172361.htm
這個要怎麼寫啊XD
mrorz
2023-03-09 01:09:07
真有趣
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
cai
23:27:39
https://cofacts.tw/article/__-BH4AMgB6gHqPegJ6h3qGfoN-gH4AfkB-AH4tXgP8
這張是107年4月警方拿來澄清的萬安演習時間 https://news.ltn.com.tw/news/life/breakingnews/2394289
但是107年5月國防部公布的不是這個時間 https://www.ettoday.net/news/20180518/1172361.htm
這個要怎麼寫啊XD
這張是107年4月警方拿來澄清的萬安演習時間 https://news.ltn.com.tw/news/life/breakingnews/2394289
但是107年5月國防部公布的不是這個時間 https://www.ettoday.net/news/20180518/1172361.htm
這個要怎麼寫啊XD
自由時報電子報
不要再傳了!「4月13日下午1點30分千萬不要出門!」網路通訊軟體最近瘋傳「中部地區萬安演習將於4月13日登場」訊息,讓中部警方趕緊出示正確版本的時間,不過連日來仍有不少民眾半信半疑,相互詢問「今天下午到底可不可以出門?」警方則再次呼籲,今年中部萬安演習正確日期是在5月29日,今天下午絕對不會有警報響起,希望網民不要再轉貼錯誤版本訊息。最近在網路通訊軟體流傳中部萬安演習將於今天下午1點30分至2點盛大登場,演習縣市包括苗栗、台中、彰化、南投、雲林等5個縣市,警報實施時將人車管制,違者處15萬元罰鍰並移送法辦,文末還強調「演習視同作戰,請勿視為兒戲」,甚至還寫「如遇敵機來襲,請盡速進入地下室躲避」,讓中部地區民眾都以為真的將在當天展開演習,但在向轄區警方詢問後,卻發現4月13日的演習日期是錯誤訊息,造成民眾一頭霧水。
ETtoday新聞雲
107年「萬安41號」演習將於6月4日至7日,區分北、中、南、東部、澎湖、金門、馬祖等7個地區實施,採有預告、分區方式,於下午1時30分至2時實施30分鐘防情傳遞、警報發放、人車疏散避難、交通及其他之必要管制、災害救援及部分城市重點等驗證;特別的是,今年萬安演習與國軍年度「漢光演習」共同辦理,盼使防空演練結合戰場景況,提高國人憂患意識。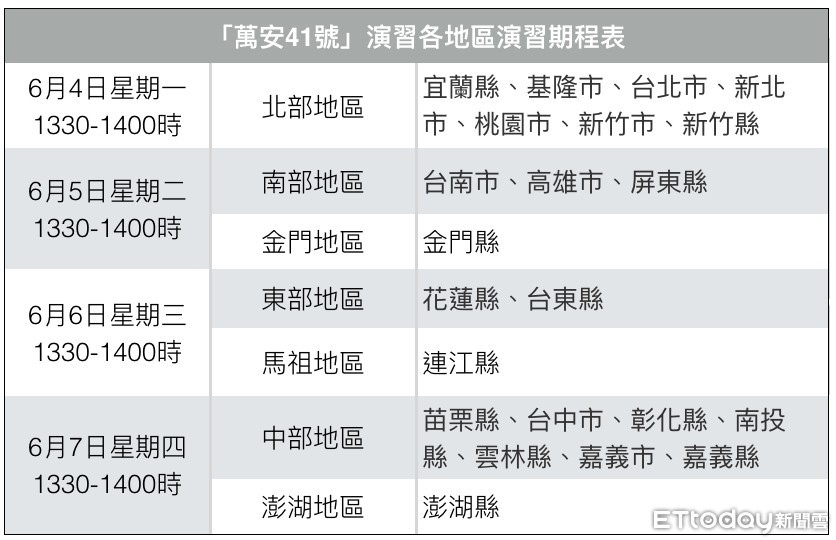
mrorz
2023-03-09 01:09:07
真有趣
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
2023-03-09
mrorz
01:09:07
真有趣
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
就說這是 2018 年 4 月警方公佈的,2018 年萬安演習時間表,是已經過時的資訊。
甚至,2018 年的萬安演習再後來也有再做調整,因此後來 2018 年實際的萬安演習日程,也與網傳圖片不同
mrorz
01:18:50
今天開會的時候聊到,ChatGPT 可以怎麼用在 Cofacts,第一種想到的情境就是,針對沒有人回過的訊息,先給一些分析,提醒使用者應該要注意哪些訊息富有情緒、哪些內容又應該查證。
https://g0v.hackmd.io/Xb7HCrZhTPq_97FtC-2RGA#Idea-of-using-ChatGPT-on-Cofacts
Open AI 其實有針對如何讓 GPT 做複雜的事情出一份文件,整理相關的 prompt engineering 文獻。其中,「請 model 先做解釋」與把解釋再拿去當 prompt 的 chain of thought 技巧,讓我想到以前做學習單的時候,會透過一系列問題來請學生作答的感覺。
想要請教大家,有沒有看過什麼媒體識讀相關的學習單,指導學生分解然後再給出答案呢?或許把網傳謠言 + 學習單問題拿來問 ChatGPT,說不定會有不錯的結果 XD
https://g0v.hackmd.io/Xb7HCrZhTPq_97FtC-2RGA#Idea-of-using-ChatGPT-on-Cofacts
Open AI 其實有針對如何讓 GPT 做複雜的事情出一份文件,整理相關的 prompt engineering 文獻。其中,「請 model 先做解釋」與把解釋再拿去當 prompt 的 chain of thought 技巧,讓我想到以前做學習單的時候,會透過一系列問題來請學生作答的感覺。
想要請教大家,有沒有看過什麼媒體識讀相關的學習單,指導學生分解然後再給出答案呢?或許把網傳謠言 + 學習單問題拿來問 ChatGPT,說不定會有不錯的結果 XD
mrorz
2023-03-09 14:33:05
Cofacts prompt engineering 結果紀錄會放在這裡
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
mrorz
2023-03-10 14:02:38
ChatGPT 相關的東西實作起來其實也是要改滿多地方的
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
mrorz
01:18:50
今天開會的時候聊到,ChatGPT 可以怎麼用在 Cofacts,第一種想到的情境就是,針對沒有人回過的訊息,先給一些分析,提醒使用者應該要注意哪些訊息富有情緒、哪些內容又應該查證。
https://g0v.hackmd.io/Xb7HCrZhTPq_97FtC-2RGA#Idea-of-using-ChatGPT-on-Cofacts
Open AI 其實有針對如何讓 GPT 做複雜的事情出一份文件,整理相關的 prompt engineering 文獻。其中,「請 model 先做解釋」與把解釋再拿去當 prompt 的 chain of thought 技巧,讓我想到以前做學習單的時候,會透過一系列問題來請學生作答的感覺。
想要請教大家,有沒有看過什麼媒體識讀相關的學習單,指導學生分解然後再給出答案呢?或許把網傳謠言 + 學習單問題拿來問 ChatGPT,說不定會有不錯的結果 XD
https://g0v.hackmd.io/Xb7HCrZhTPq_97FtC-2RGA#Idea-of-using-ChatGPT-on-Cofacts
Open AI 其實有針對如何讓 GPT 做複雜的事情出一份文件,整理相關的 prompt engineering 文獻。其中,「請 model 先做解釋」與把解釋再拿去當 prompt 的 chain of thought 技巧,讓我想到以前做學習單的時候,會透過一系列問題來請學生作答的感覺。
想要請教大家,有沒有看過什麼媒體識讀相關的學習單,指導學生分解然後再給出答案呢?或許把網傳謠言 + 學習單問題拿來問 ChatGPT,說不定會有不錯的結果 XD
mrorz
2023-03-09 14:33:05
Cofacts prompt engineering 結果紀錄會放在這裡
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
mrorz
2023-03-10 14:02:38
ChatGPT 相關的東西實作起來其實也是要改滿多地方的
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
mrorz
14:33:05
Replied to a thread: 2023-03-09 01:18:50
Cofacts prompt engineering 結果紀錄會放在這裡
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
https://docs.google.com/spreadsheets/d/e/2PACX-1vQSOFMGdiiHSXzh7j3ZpKnMRtSNDhKip1xrtxxW3wiF2CbISz3tipNw6Uw2uKTsH5oL4Rv8qtVSqQNq/pubhtml#
我請 ChatGPT 每個測試輸出三次,放在 output / response 欄位,來看該 prompt 產出的穩定性。 畢竟 GPT 每次都不同,只能多弄個幾次,比較好判斷回應裡的某些特性,是運氣好有出現,還是穩定出現。
2023-03-10
cai
01:16:23
https://cofacts.tw/article/kPwQsoYBC7Q3lHuU3kOd
這篇講法有點像捏造的,可是你又不可能去問警方說有沒有這個案件
手法是匯錯錢冒名貸款此篇的變形 https://tfc-taiwan.org.tw/articles/6308 只是他攔截成功
https://cofacts.tw/article/v_w1vIYBC7Q3lHuUYEwh 這篇也是類似的,標題寫他被騙了,最後又說是轉述的
這篇講法有點像捏造的,可是你又不可能去問警方說有沒有這個案件
手法是匯錯錢冒名貸款此篇的變形 https://tfc-taiwan.org.tw/articles/6308 只是他攔截成功
https://cofacts.tw/article/v_w1vIYBC7Q3lHuUYEwh 這篇也是類似的,標題寫他被騙了,最後又說是轉述的
台灣事實查核中心
【報告將隨時更新 2023/2/7版】 一、警政署表示,近期並未收到傳言敘述的犯罪通報案件。 二、銀行公會與律師均指出,傳言描述的犯罪手法有諸多不合理之處。 三、銀行公會指出,處理誤匯款的標準流程,是由雙方銀行居中聯繫,不可能有匯款人取得另一方個資。民眾在不知情的狀況下被盜用身份申請貸款,受侵害的是銀行的財產權,被盜用身份者無須繳納貸款費用。 傳言描述的犯罪手法有諸多不合理之處,是捏造的假治安提醒,因此,為「錯誤」訊息。 【查核聲明】資訊若有更新,本報告亦會同步更新。
mrorz
2023-03-10 08:53:44
這是變形沒錯
原本銀行已經闢謠,影片卻改口變成地下錢莊
原本銀行已經闢謠,影片卻改口變成地下錢莊
mrorz
2023-03-10 08:58:43
欸不對,TFC 那篇就是寫地下錢莊
這兩個影片裡面的狀況就是 TFC 裡說的那樣
這兩個影片裡面的狀況就是 TFC 裡說的那樣
mrorz
2023-03-10 09:17:03
目前 Cofacts 上的回應好像比較偏向解釋,用假資訊放貸者不可能是銀行。但兩個影片都聲稱是錢莊。MyGoPen 當時問警政署,警政署表示
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
mrorz
2023-03-10 09:20:30
抖音上這兩個新影片的特性是
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
IG 版,一樣是媽媽接到電話,帶去警察局備案https://cofacts.tw/article/X6TF4YcBpPlTXSoGI34h
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
mrorz
2023-05-12 03:36:58
我發現 TFC 跟 MyGoPen 的查核報告有更新,所以就寫了回應。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
cai
01:16:23
https://cofacts.tw/article/kPwQsoYBC7Q3lHuU3kOd
這篇講法有點像捏造的,可是你又不可能去問警方說有沒有這個案件
手法是此篇的變形 https://tfc-taiwan.org.tw/articles/6308 只是他攔截成功
https://cofacts.tw/article/v_w1vIYBC7Q3lHuUYEwh 這篇也是類似的,標題寫他被騙了,最後又說是轉述的
這篇講法有點像捏造的,可是你又不可能去問警方說有沒有這個案件
手法是此篇的變形 https://tfc-taiwan.org.tw/articles/6308 只是他攔截成功
https://cofacts.tw/article/v_w1vIYBC7Q3lHuUYEwh 這篇也是類似的,標題寫他被騙了,最後又說是轉述的
mrorz
2023-03-10 08:53:44
這是變形沒錯
原本銀行已經闢謠,影片卻改口變成地下錢莊
原本銀行已經闢謠,影片卻改口變成地下錢莊
mrorz
2023-03-10 08:58:43
欸不對,TFC 那篇就是寫地下錢莊
這兩個影片裡面的狀況就是 TFC 裡說的那樣
這兩個影片裡面的狀況就是 TFC 裡說的那樣
mrorz
2023-03-10 09:17:03
目前 Cofacts 上的回應好像比較偏向解釋,用假資訊放貸者不可能是銀行。但兩個影片都聲稱是錢莊。MyGoPen 當時問警政署,警政署表示
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
mrorz
2023-03-10 09:20:30
抖音上這兩個新影片的特性是
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
IG 版,一樣是媽媽接到電話,帶去警察局備案https://cofacts.tw/article/X6TF4YcBpPlTXSoGI34h
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
https://www.instagram.com/p/CpsATFlhoWD/ IG留言直接有人說不要抄襲文本 😆
mrorz
2023-05-12 03:36:58
我發現 TFC 跟 MyGoPen 的查核報告有更新,所以就寫了回應。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
我參考 TFC 下面的 comment,增加了真正詐騙案例。相比之下,謠言影片裡面的詐騙集團也太辛苦,除了被害人連錢莊也要騙;而謠言裡的錢莊也太愚蠢這麼輕鬆就放貸出去,不怕倒帳ㄇ。
mrorz
08:53:44
這是變形沒錯
原本銀行已經闢謠,影片卻改口變成地下錢莊
原本銀行已經闢謠,影片卻改口變成地下錢莊
mrorz
08:58:43
欸不對,TFC 那篇就是寫地下錢莊
這兩個影片裡面的狀況就是 TFC 裡說的那樣
這兩個影片裡面的狀況就是 TFC 裡說的那樣
mrorz
09:17:03
Replied to a thread: 2023-03-10 01:16:23
目前 Cofacts 上的回應好像比較偏向解釋,用假資訊放貸者不可能是銀行。但兩個影片都聲稱是錢莊。MyGoPen 當時問警政署,警政署表示
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
1. 當時沒案例。
2. 但民間借貸機構是否會這樣放款,並不確定。
https://www.mygopen.com/2021/09/bank-fraud.html
其實 2021 年中國發生的那個事件,我也覺得有東西沒有講清楚 。即使該篇中國受害者把錢匯回,那也應該是直接匯回原帳戶,也就是網貸帳戶,也就像是還錢那樣。
MyGoPen
網傳「有人會突然匯一筆錢到你的銀行戶頭,然後你會接到一通電話,對方會說他不小心錯把錢轉入你的帳戶」的訊息。經查證,警方表示,一般來說是不太可能拿別人個資去幫別人貸款的,都會要求本人要到場;而民眾如果匯錯款項,也是由銀行跟郵局代為聯繫對方,所以如果在收到不明款項後接到自稱是匯款人的電話,很高機率是詐騙
mrorz
09:20:30
抖音上這兩個新影片的特性是
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
1. 最後都是在為自己的帳號宣傳
2. 揭露的資訊都沒有超過 2021 年的網傳訊息。若真有這件事情發生,他們手上應有很多值得分享的資訊,例如會給他的帳號,對方要求匯回的帳號,出示報案三聯單等等,不太可能兩個人表現此案的方法,都像是在照著 2021 年版的照本宣科。
3. 聲稱有報警,但印象中 165 反詐騙近期沒有發表與此手法相關的資訊。
mrorz
14:01:35
最近看 AI 相關的東西時,也思考了一下 embedding 與相關的東西如何可以改善我們在 multimedia 上的搜尋效果
記錄在舊文件的新段落
• Vector / embedding based similarity
• Metadata (包含 OCR text) extraction implementation
記錄在舊文件的新段落
• Vector / embedding based similarity
• Metadata (包含 OCR text) extraction implementation
mrorz
14:01:35
最近看 AI 相關的東西時,也思考了一下 embedding 與相關的東西如何可以改善我們在 multimedia 上的搜尋效果
記錄在舊文件的新段落,下週三聊一下
• Vector / embedding based similarity
• Metadata (包含 OCR text) extraction implementation
記錄在舊文件的新段落,下週三聊一下
• Vector / embedding based similarity
• Metadata (包含 OCR text) extraction implementation
# Cofacts reasearch & design docs :::info - Design docs: Implementation documents with requiremen
mrorz
14:02:38
Replied to a thread: 2023-03-09 01:18:50
ChatGPT 相關的東西實作起來其實也是要改滿多地方的
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
先開個 design doc 放段落,下週三前補起來跟大家 review 一下
https://g0v.hackmd.io/WwinEyGBRYmi_iKu8cSprQ
gary96302000.eecs96
16:12:52
Hi @mrorz ,關於如果要用 embedding 做 search 的話,我這邊有些經驗也可以分享:
• 如果考慮比較不花錢的方案,可以用 SBert 這個 package:https://www.sbert.net/
• model 有多國語言的,中文的效果可能要測試看看,但是在英文效果蠻不錯的
• 在 production 時,還要考慮到 inference 的效率,單純 SBERT 用 CPU 是跑的了的(但還是不夠快,大概數十到數百 ms per query on CPU machine)
• 還可以進一步加快 inference 的速度,搭配 onnx, triton server 可以壓到 個位數 ms per query on CPU machine
大概是這樣~
• 如果考慮比較不花錢的方案,可以用 SBert 這個 package:https://www.sbert.net/
• model 有多國語言的,中文的效果可能要測試看看,但是在英文效果蠻不錯的
• 在 production 時,還要考慮到 inference 的效率,單純 SBERT 用 CPU 是跑的了的(但還是不夠快,大概數十到數百 ms per query on CPU machine)
• 還可以進一步加快 inference 的速度,搭配 onnx, triton server 可以壓到 個位數 ms per query on CPU machine
大概是這樣~
 1
1 1
1
mrorz
2023-03-10 17:06:31
對耶我只考慮到 vector search 沒考慮到產生 vector 的 inference time
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
mrorz
2023-03-10 17:07:59
Elasticsearch 8.6 也可以 TF-IDF 跟 KNN similarity 混合算 score
gary96302000.eecs96
2023-03-10 17:08:54
可以試試看 往往都有預想之上的成效 SBERT 的效果是很不錯的 在很多比賽都會用 當然如果不考慮$$ OpenAI 給的 embedding 當然是更好就是了 🐛
mrorz
2023-03-10 17:09:00
(不過我們要從現在的 ES 6.8 往上升,可能要花點功伕 XD)
mrorz
2023-03-10 17:09:25
OpenAI 給的 embedding 好像有點太長,超過 ES 6.8 支援的 1024 維 XD
gary96302000.eecs96
2023-03-10 17:09:29
好奇問一下 現在 Cofacts DB 裡面文章的量級大概是怎樣
gary96302000.eecs96
2023-03-10 17:10:05
有超過 1M 的數量嗎
mrorz
2023-03-10 17:10:34
沒有超過 1M,但是是很髒的 97K (茶
mrorz
2023-03-10 17:11:10
髒到國內有些人拿來做論文
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
mrorz
2023-03-10 17:11:36
希望我們的 opendata 沒阻礙到對方畢業
gary96302000.eecs96
2023-03-10 17:14:52
mrorz
2023-03-10 17:16:13
Elasticsearch 內建的是 HNSW
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
gary96302000.eecs96
2023-03-10 17:23:05
應該也行 這兩種我就不知道哪個更快 但是如果是想要保有 ES 的 flow 那應該就找 ES 的比較方便些
mrorz
2023-03-10 17:25:30
想問 https://www.sbert.net/docs/pretrained_models.html#image-text-models 這個是 multimodal 的嗎
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
gary96302000.eecs96
2023-03-10 17:26:06
yap
gary96302000.eecs96
2023-03-10 17:26:24
不過這個要跑估計硬體需求很高
gary96302000.eecs96
2023-03-10 17:26:56
clip 系列的 model 就是 image & text 的 multimodal
mrorz
2023-03-10 17:30:34
SBERT 的 embedding 有幾維、有沒有 normalize 之類的有寫在文件裡嗎,還是通常這些基本的東西大家就 colab 跑一發後 print 出來看 XD”
(我問的問題好低階 🤦 )
(我問的問題好低階 🤦 )
mrorz
2023-03-10 17:31:29
也有點好奇 SBERT 看起來是 optimized for sentenses,Cofacts 有些是一整篇文章這種丟進去算,不知道會發生什麼事情
gary96302000.eecs96
2023-03-10 17:31:33
gary96302000.eecs96
2023-03-10 17:32:25
點一下那個 model 他會展開
mrorz
2023-03-10 17:32:35
原來藏在 (i) 裡面!!
mrorz
2023-03-10 17:32:39
感謝感謝 m(_ _)m
gary96302000.eecs96
2023-03-10 17:34:00
文章的話,有幾種做法:
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
mrorz
2023-03-10 17:34:28
原來 embedding 是可以自己加起來平均的嗎 XDD
gary96302000.eecs96
2023-03-10 17:34:33
恩啊
mrorz
2023-03-10 17:34:36
好像也是有道理
mrorz
2023-03-10 17:34:54
畢竟都能算 cosine similarity xk7
gary96302000.eecs96
2023-03-10 17:35:01
意外的有點效果 直覺有時候會覺得掉了一些資訊
mrorz
2023-03-10 17:36:09
沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎
gary96302000.eecs96
2023-03-10 17:41:05
應該是他在 train 的時候用的 loss function 有沒有 normalize 我記得
gary96302000.eecs96
2023-03-10 17:41:20
cosine 跟 dot 的差異
gary96302000.eecs96
2023-03-10 17:41:58
剛剛問維度的那個問題
gary96302000.eecs96
2023-03-10 17:41:59
gary96302000.eecs96
2023-03-10 17:42:04
以這個為例來說
gary96302000.eecs96
2023-03-10 17:42:43
應該是這個 hidden_size 是多少 就是他的維度
gary96302000.eecs96
2023-03-10 17:43:52
大概就是去 model card 裡面找到 config.json,會寫 model 架構的一些資訊
gary96302000.eecs96
2023-03-10 17:46:34
```沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎```
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
mrorz
2023-03-10 17:55:16
嗯嗯,那我拿到沒 normalize 的 embedding 可以自己 normalize 到長度為 1 之後存起來嗎
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
gary96302000.eecs96
2023-03-10 17:58:57
可以的歐 但是這其中有個細節,會影響到你算出來的分數:
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
mrorz
2023-03-10 17:59:24
想說個別文章除自己的
gary96302000.eecs96
2023-03-10 18:03:41
因為每個文章他的 emb length 會不太一樣,個別除自己的就不見得在分數上可以原音重現,舉例來說 a, b, c 三個 emb,他們個別的長度假設是 2, 4, 7,原本的分數是直接乘起來,但如果個別 normalize 會是 a/2, b/4, c/7 倆倆乘積,這樣 pair 算出來的 score ranking 會和原本的不太一樣才對,但是如果都 /7 那就沒有差別
mrorz
2023-03-10 18:05:44
喔喔喔喔 懂了
感謝感謝 m(_ _)m
感謝感謝 m(_ _)m
gary96302000.eecs96
2023-03-10 18:07:31
不會 最近 ChatGPT 風口浪尖 原本就碰了不少 vector space search 的東西 剛好看到這邊有提到 哈哈
mrorz
2023-03-10 18:22:00
是說 @gary96302000.eecs96 有接觸到當時 rumors-ai 的 deployment 嗎
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
gary96302000.eecs96
2023-03-10 18:27:06
deploy 應該是有碰一部分 不過當時跟現在模型已經進步很多了 有考慮要重新弄一個模型嗎 比原本 BERT 好又可以看看要不要用 CPU 能跑的架構就好 直接拿掉 GPU 那塊
gary96302000.eecs96
2023-03-10 18:30:27
我還記得我之前是把 google 的 code 拿來魔改才能跑在我們的資料框架 現在抱抱臉那邊都搞得很好用了 配 SBERT 應該也不錯
mrorz
2023-03-10 18:34:09
聽起來很棒!
方便指個路給一竅不通的前端工程師嗎 QQ
方便指個路給一竅不通的前端工程師嗎 QQ
gary96302000.eecs96
2023-03-10 18:40:34
思路跟步驟大概是這樣:
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
gary96302000.eecs96
2023-03-10 18:42:51
第四步不見得要,因為 article categorizer 不是 real-time demand
mrorz
2023-03-10 18:50:23
1~3 聽起來可以在 google colab 上做,應該可以試試看
4, 5 等前三步做得出來再說 XD
感謝感謝
4, 5 等前三步做得出來再說 XD
感謝感謝
mrorz
2023-03-10 20:06:04
我看 https://www.sbert.net/index.html 的 Usage 看到滿多文字轉 embedding 之後用在 clustering 跟 retrieval
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
gary96302000.eecs96
2023-03-10 20:20:36
那應該要再接一層出來 做分類
mrorz
2023-03-10 21:24:35
如果我有 `k` 個分類
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
gary96302000.eecs96
2023-03-10 21:49:33
嗯嗯 如果只要標一個答案 用 softmax 就只會有一個最大且全部加起來是1
mrorz
2023-03-11 10:19:21
不過其實我是想要每個 topic label 各自都 0-1 XD
gary96302000.eecs96
16:12:52
Hi @mrorz ,關於如果要用 embedding 做 search 的話,我這邊有些經驗也可以分享:
• 如果考慮比較不花錢的方案,可以用 SBert 這個 package:https://www.sbert.net/
• model 有多國語言的,中文的效果可能要測試看看,但是在英文效果蠻不錯的
• 在 production 時,還要考慮到 inference 的效率,單純 SBERT 用 CPU 是跑的了的(但還是不夠快,大概數十到數百 ms per query on CPU machine)
• 還可以進一步加快 inference 的速度,搭配 onnx, triton server 可以壓到 個位數 ms per query on CPU machine
大概是這樣~
• 如果考慮比較不花錢的方案,可以用 SBert 這個 package:https://www.sbert.net/
• model 有多國語言的,中文的效果可能要測試看看,但是在英文效果蠻不錯的
• 在 production 時,還要考慮到 inference 的效率,單純 SBERT 用 CPU 是跑的了的(但還是不夠快,大概數十到數百 ms per query on CPU machine)
• 還可以進一步加快 inference 的速度,搭配 onnx, triton server 可以壓到 個位數 ms per query on CPU machine
大概是這樣~
mrorz
2023-03-10 17:06:31
對耶我只考慮到 vector search 沒考慮到產生 vector 的 inference time
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
mrorz
2023-03-10 17:07:59
Elasticsearch 8.6 也可以 TF-IDF 跟 KNN similarity 混合算 score
gary96302000.eecs96
2023-03-10 17:08:54
可以試試看 往往都有預想之上的成效 SBERT 的效果是很不錯的 在很多比賽都會用 當然如果不考慮$$ OpenAI 給的 embedding 當然是更好就是了 🐛
mrorz
2023-03-10 17:09:00
(不過我們要從現在的 ES 6.8 往上升,可能要花點功伕 XD)
mrorz
2023-03-10 17:09:25
OpenAI 給的 embedding 好像有點太長,超過 ES 6.8 支援的 1024 維 XD
gary96302000.eecs96
2023-03-10 17:09:29
好奇問一下 現在 Cofacts DB 裡面文章的量級大概是怎樣
gary96302000.eecs96
2023-03-10 17:10:05
有超過 1M 的數量嗎
mrorz
2023-03-10 17:10:34
沒有超過 1M,但是是很髒的 97K (茶
mrorz
2023-03-10 17:11:10
髒到國內有些人拿來做論文
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
mrorz
2023-03-10 17:11:36
希望我們的 opendata 沒阻礙到對方畢業
gary96302000.eecs96
2023-03-10 17:14:52
mrorz
2023-03-10 17:16:13
Elasticsearch 內建的是 HNSW
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
gary96302000.eecs96
2023-03-10 17:23:05
應該也行 這兩種我就不知道哪個更快 但是如果是想要保有 ES 的 flow 那應該就找 ES 的比較方便些
mrorz
2023-03-10 17:25:30
想問 https://www.sbert.net/docs/pretrained_models.html#image-text-models 這個是 multimodal 的嗎
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
gary96302000.eecs96
2023-03-10 17:26:06
yap
gary96302000.eecs96
2023-03-10 17:26:24
不過這個要跑估計硬體需求很高
gary96302000.eecs96
2023-03-10 17:26:56
clip 系列的 model 就是 image & text 的 multimodal
mrorz
2023-03-10 17:30:34
SBERT 的 embedding 有幾維、有沒有 normalize 之類的有寫在文件裡嗎,還是通常這些基本的東西大家就 colab 跑一發後 print 出來看 XD”
(我問的問題好低階 🤦 )
(我問的問題好低階 🤦 )
mrorz
2023-03-10 17:31:29
也有點好奇 SBERT 看起來是 optimized for sentenses,Cofacts 有些是一整篇文章這種丟進去算,不知道會發生什麼事情
gary96302000.eecs96
2023-03-10 17:31:33
gary96302000.eecs96
2023-03-10 17:32:25
點一下那個 model 他會展開
mrorz
2023-03-10 17:32:35
原來藏在 (i) 裡面!!
mrorz
2023-03-10 17:32:39
感謝感謝 m(_ _)m
gary96302000.eecs96
2023-03-10 17:34:00
文章的話,有幾種做法:
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
mrorz
2023-03-10 17:34:28
原來 embedding 是可以自己加起來平均的嗎 XDD
gary96302000.eecs96
2023-03-10 17:34:33
恩啊
mrorz
2023-03-10 17:34:36
好像也是有道理
mrorz
2023-03-10 17:34:54
畢竟都能算 cosine similarity xk7
gary96302000.eecs96
2023-03-10 17:35:01
意外的有點效果 直覺有時候會覺得掉了一些資訊
mrorz
2023-03-10 17:36:09
沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎
gary96302000.eecs96
2023-03-10 17:41:05
應該是他在 train 的時候用的 loss function 有沒有 normalize 我記得
gary96302000.eecs96
2023-03-10 17:41:20
cosine 跟 dot 的差異
gary96302000.eecs96
2023-03-10 17:41:58
剛剛問維度的那個問題
gary96302000.eecs96
2023-03-10 17:41:59
gary96302000.eecs96
2023-03-10 17:42:04
以這個為例來說
gary96302000.eecs96
2023-03-10 17:42:43
應該是這個 hidden_size 是多少 就是他的維度
gary96302000.eecs96
2023-03-10 17:43:52
大概就是去 model card 裡面找到 config.json,會寫 model 架構的一些資訊
gary96302000.eecs96
2023-03-10 17:46:34
```沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎```
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
mrorz
2023-03-10 17:55:16
嗯嗯,那我拿到沒 normalize 的 embedding 可以自己 normalize 到長度為 1 之後存起來嗎
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
gary96302000.eecs96
2023-03-10 17:58:57
可以的歐 但是這其中有個細節,會影響到你算出來的分數:
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
mrorz
2023-03-10 17:59:24
想說個別文章除自己的
gary96302000.eecs96
2023-03-10 18:03:41
因為每個文章他的 emb length 會不太一樣,個別除自己的就不見得在分數上可以原音重現,舉例來說 a, b, c 三個 emb,他們個別的長度假設是 2, 4, 7,原本的分數是直接乘起來,但如果個別 normalize 會是 a/2, b/4, c/7 倆倆乘積,這樣 pair 算出來的 score ranking 會和原本的不太一樣才對,但是如果都 /7 那就沒有差別
mrorz
2023-03-10 18:05:44
喔喔喔喔 懂了
感謝感謝 m(_ _)m
感謝感謝 m(_ _)m
gary96302000.eecs96
2023-03-10 18:07:31
不會 最近 ChatGPT 風口浪尖 原本就碰了不少 vector space search 的東西 剛好看到這邊有提到 哈哈
mrorz
2023-03-10 18:22:00
是說 @gary96302000.eecs96 有接觸到當時 rumors-ai 的 deployment 嗎
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
gary96302000.eecs96
2023-03-10 18:27:06
deploy 應該是有碰一部分 不過當時跟現在模型已經進步很多了 有考慮要重新弄一個模型嗎 比原本 BERT 好又可以看看要不要用 CPU 能跑的架構就好 直接拿掉 GPU 那塊
gary96302000.eecs96
2023-03-10 18:30:27
我還記得我之前是把 google 的 code 拿來魔改才能跑在我們的資料框架 現在抱抱臉那邊都搞得很好用了 配 SBERT 應該也不錯
mrorz
2023-03-10 18:34:09
聽起來很棒!
方便指個路給一竅不通的前端工程師嗎 QQ
方便指個路給一竅不通的前端工程師嗎 QQ
gary96302000.eecs96
2023-03-10 18:40:34
思路跟步驟大概是這樣:
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
gary96302000.eecs96
2023-03-10 18:42:51
第四步不見得要,因為 article categorizer 不是 real-time demand
mrorz
2023-03-10 18:50:23
1~3 聽起來可以在 google colab 上做,應該可以試試看
4, 5 等前三步做得出來再說 XD
感謝感謝
4, 5 等前三步做得出來再說 XD
感謝感謝
mrorz
2023-03-10 20:06:04
我看 https://www.sbert.net/index.html 的 Usage 看到滿多文字轉 embedding 之後用在 clustering 跟 retrieval
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
gary96302000.eecs96
2023-03-10 20:20:36
那應該要再接一層出來 做分類
mrorz
2023-03-10 21:24:35
如果我有 `k` 個分類
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
gary96302000.eecs96
2023-03-10 21:49:33
嗯嗯 如果只要標一個答案 用 softmax 就只會有一個最大且全部加起來是1
mrorz
2023-03-11 10:19:21
不過其實我是想要每個 topic label 各自都 0-1 XD
mrorz
17:06:31
對耶我只考慮到 vector search 沒考慮到產生 vector 的 inference time
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
感謝 insight
其實我有點懷疑在 Cofacts 的情境下,用 embedding 的 cosine similarity 做出來的 similarity list,跟用傳統 IR 的 TF-IDF score (Elasticsearch relevance) 相比,有多少優勢
mrorz
17:07:59
Elasticsearch 8.6 也可以 TF-IDF 跟 KNN similarity 混合算 score
gary96302000.eecs96
17:08:54
可以試試看 往往都有預想之上的成效 SBERT 的效果是很不錯的 在很多比賽都會用 當然如果不考慮$$ OpenAI 給的 embedding 當然是更好就是了 🐛
mrorz
17:09:00
(不過我們要從現在的 ES 6.8 往上升,可能要花點功伕 XD)
mrorz
17:09:25
OpenAI 給的 embedding 好像有點太長,超過 ES 6.8 支援的 1024 維 XD
gary96302000.eecs96
17:09:29
好奇問一下 現在 Cofacts DB 裡面文章的量級大概是怎樣
gary96302000.eecs96
17:10:05
有超過 1M 的數量嗎
mrorz
17:10:34
沒有超過 1M,但是是很髒的 97K (茶
mrorz
17:11:10
髒到國內有些人拿來做論文
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
發現在 dataset 裡做得不錯的,放到 cofacts 上都變很爛那種
mrorz
17:11:36
希望我們的 opendata 沒阻礙到對方畢業
mrorz
17:16:13
Elasticsearch 內建的是 HNSW
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
(其實我有點沒概念這有多快,但印象中都是 approximate kNN 的 indexing & search)
gary96302000.eecs96
17:23:05
應該也行 這兩種我就不知道哪個更快 但是如果是想要保有 ES 的 flow 那應該就找 ES 的比較方便些
mrorz
17:25:30
想問 https://www.sbert.net/docs/pretrained_models.html#image-text-models 這個是 multimodal 的嗎
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
就是圖片跟中文文字丟給他做 embeddings
圖片的 embedding 跟文字的 embedding 彼此之間也能拿來算距離這樣
gary96302000.eecs96
17:26:06
yap
gary96302000.eecs96
17:26:24
不過這個要跑估計硬體需求很高
gary96302000.eecs96
17:26:56
clip 系列的 model 就是 image & text 的 multimodal
mrorz
17:30:34
SBERT 的 embedding 有幾維、有沒有 normalize 之類的有寫在文件裡嗎,還是通常這些基本的東西大家就 colab 跑一發後 print 出來看 XD”
(我問的問題好低階 🤦 )
(我問的問題好低階 🤦 )
mrorz
17:31:29
也有點好奇 SBERT 看起來是 optimized for sentenses,Cofacts 有些是一整篇文章這種丟進去算,不知道會發生什麼事情
gary96302000.eecs96
17:31:33
gary96302000.eecs96
17:32:25
點一下那個 model 他會展開
mrorz
17:32:35
原來藏在 (i) 裡面!!
mrorz
17:32:39
感謝感謝 m(_ _)m
gary96302000.eecs96
17:34:00
文章的話,有幾種做法:
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
1. 不管就直接丟,過長的他會 truncate 掉沒有資訊
2. 自己先做好 sentence segmentation 後,每個句子丟給他然後加起來平均當作這篇文章的 embedding
mrorz
17:34:28
原來 embedding 是可以自己加起來平均的嗎 XDD
gary96302000.eecs96
17:34:33
恩啊
mrorz
17:34:36
好像也是有道理
mrorz
17:34:54
畢竟都能算 cosine similarity xk7
gary96302000.eecs96
17:35:01
意外的有點效果 直覺有時候會覺得掉了一些資訊
mrorz
17:36:09
沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎
gary96302000.eecs96
17:41:05
應該是他在 train 的時候用的 loss function 有沒有 normalize 我記得
gary96302000.eecs96
17:41:20
cosine 跟 dot 的差異
gary96302000.eecs96
17:41:58
剛剛問維度的那個問題
gary96302000.eecs96
17:41:59
gary96302000.eecs96
17:42:04
以這個為例來說
gary96302000.eecs96
17:42:43
應該是這個 hidden_size 是多少 就是他的維度
gary96302000.eecs96
17:43:52
大概就是去 model card 裡面找到 config.json,會寫 model 架構的一些資訊
gary96302000.eecs96
17:46:34
```沒 normalize 的那些 embedding 是代表說,有些資訊會在他的長度上面,所以不能隨便亂 normalize 這樣嗎```
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
然後這個還有個梗就是算分數的時候,內積沒有 normalize 的 embedding 他的值域會是 R,有 normalize 的才會在 0~1 之間,所以有的為了要有可比性,都會用 cosine 比較多
mrorz
17:55:16
嗯嗯,那我拿到沒 normalize 的 embedding 可以自己 normalize 到長度為 1 之後存起來嗎
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
如果我只會拿它來算 cosine similarity 的話,是不是就可以一律 normalize to 1,這樣就能用內積來取代 cosine similairty
gary96302000.eecs96
17:58:57
可以的歐 但是這其中有個細節,會影響到你算出來的分數:
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
• 你計算要同除的數,是要所有人一起除,還是 by 個別文章除自己的
• 理論上全部除同樣一個感覺比較合理,但是這個 cost 稍微高一些,而且文章一變多又要算一次
mrorz
17:59:24
想說個別文章除自己的
gary96302000.eecs96
18:03:41
因為每個文章他的 emb length 會不太一樣,個別除自己的就不見得在分數上可以原音重現,舉例來說 a, b, c 三個 emb,他們個別的長度假設是 2, 4, 7,原本的分數是直接乘起來,但如果個別 normalize 會是 a/2, b/4, c/7 倆倆乘積,這樣 pair 算出來的 score ranking 會和原本的不太一樣才對,但是如果都 /7 那就沒有差別
mrorz
18:05:44
喔喔喔喔 懂了
感謝感謝 m(_ _)m
感謝感謝 m(_ _)m
gary96302000.eecs96
18:07:31
不會 最近 ChatGPT 風口浪尖 原本就碰了不少 vector space search 的東西 剛好看到這邊有提到 哈哈
mrorz
18:22:00
是說 @gary96302000.eecs96 有接觸到當時 rumors-ai 的 deployment 嗎
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
我們準備了一包新的 ground truth 放在
https://github.com/cofacts/ground-truth
label 有些更新(把數字改成 category ID,所以 infer 完之後不用再過 mapping table 把數字轉回 category ID)
但 @ggm 好像還沒有把它拿來 train 並且放到 production 環境 QQ
gary96302000.eecs96
18:27:06
deploy 應該是有碰一部分 不過當時跟現在模型已經進步很多了 有考慮要重新弄一個模型嗎 比原本 BERT 好又可以看看要不要用 CPU 能跑的架構就好 直接拿掉 GPU 那塊
gary96302000.eecs96
18:30:27
我還記得我之前是把 google 的 code 拿來魔改才能跑在我們的資料框架 現在抱抱臉那邊都搞得很好用了 配 SBERT 應該也不錯
mrorz
18:34:09
聽起來很棒!
方便指個路給一竅不通的前端工程師嗎 QQ
方便指個路給一竅不通的前端工程師嗎 QQ
gary96302000.eecs96
18:40:34
思路跟步驟大概是這樣:
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
1. 根據現在定義的 article vs id 的架構,準備好訓練資料
2. fine tune BERT-like models:https://www.sbert.net/docs/training/overview.html
3. 存下訓練好的模型
4. 把模型用 onnx 後放進 triton server,這樣就可以用 CPU 快速 inference
5. given 一個 new article,打 API 到這個 triton server 做 inference 出他是哪個 id
大概是這樣
gary96302000.eecs96
18:42:51
第四步不見得要,因為 article categorizer 不是 real-time demand
mrorz
18:50:23
1~3 聽起來可以在 google colab 上做,應該可以試試看
4, 5 等前三步做得出來再說 XD
感謝感謝
4, 5 等前三步做得出來再說 XD
感謝感謝
mrorz
20:06:04
我看 https://www.sbert.net/index.html 的 Usage 看到滿多文字轉 embedding 之後用在 clustering 跟 retrieval
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
但沒有看到如何 tune 成 N 個可以複選的 label 的 classifier 耶 QQ
gary96302000.eecs96
20:20:36
那應該要再接一層出來 做分類
mrorz
21:24:35
如果我有 `k` 個分類
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
Network 就是 BERT --> pooling --> dense --> `k` 維 這樣嗎
每一維對應到一個分類的機率 0~1
gary96302000.eecs96
21:49:33
嗯嗯 如果只要標一個答案 用 softmax 就只會有一個最大且全部加起來是1
2023-03-11
mrorz
10:19:21
不過其實我是想要每個 topic label 各自都 0-1 XD
Dingo
10:51:21
@imdingo has joined the channel
2023-03-13
cai
23:59:57
https://cofacts.tw/article/oPzEzoYBC7Q3lHuUSV2b
這篇我剛有找到原始的影片
https://www.facebook.com/TheFoodRangerShow/videos/this-is-how-century-eggs-are-made-i-cant-stop-watching/3370344996558092/
他寫century eggs
可是我整部看完看起來比較像是鹹蛋?
這篇我剛有找到原始的影片
https://www.facebook.com/TheFoodRangerShow/videos/this-is-how-century-eggs-are-made-i-cant-stop-watching/3370344996558092/
他寫century eggs
可是我整部看完看起來比較像是鹹蛋?
facebook.com
13M views, 40K likes, 1.2K loves, 3.4K comments, 18K shares, Facebook Watch Videos from The Food Ranger Show: This is how century eggs are made, I can't stop watching
cai
23:59:57
https://cofacts.tw/article/oPzEzoYBC7Q3lHuUSV2b
這篇我剛有找到原始的影片
https://www.facebook.com/TheFoodRangerShow/videos/this-is-how-century-eggs-are-made-i-cant-stop-watching/3370344996558092/
他寫century eggs
可是我整部看完看起來比較像是鹹蛋?
這篇我剛有找到原始的影片
https://www.facebook.com/TheFoodRangerShow/videos/this-is-how-century-eggs-are-made-i-cant-stop-watching/3370344996558092/
他寫century eggs
可是我整部看完看起來比較像是鹹蛋?
2023-03-14
cai
00:40:40
查影片的好耗時間.......
mrorz
00:54:09
耗時間 +1
我比較想要找到 surrounding text 但找不到囧
我比較想要找到 surrounding text 但找不到囧
mrorz
12:30:28
ping
mrorz
12:30:28
ping
mrorz
14:00:54
GA4 Chatbot LIFF migration PR:
https://github.com/cofacts/rumors-line-bot/pull/344
還剩下 chatbot webhook 改 bigquery 以及 api 的收資料的 script
https://github.com/cofacts/rumors-line-bot/pull/344
還剩下 chatbot webhook 改 bigquery 以及 api 的收資料的 script
2023-03-15
mrorz
13:15:21
今日議程
cai
17:56:38
沒開閱讀權限
mrorz
18:38:32
感謝提醒,剛開完
2023-03-16
2023-03-17
cai
12:35:56
又被發6000的洗版了
cai
19:27:46
接下來會有一輪電的嗎 🤔
mrorz
19:30:23
核二停機後嗎
應該會ㄛ
應該會ㄛ
mrorz
19:34:54
哦哦哦是能源價格的部分
2023-03-20
cai
01:03:07
cai
01:03:09
mrorz
11:06:21
讚讚
我覺得直接貼原始貼文 + 公視很棒耶
我覺得直接貼原始貼文 + 公視很棒耶
cai
12:54:53
我先丟補充好了
公視那影片是宜蘭(湖泊型),新竹這個應該是影片提到的溪流型,我查了幾篇新聞報導也都是宜蘭,沒新竹的資料
公視那影片是宜蘭(湖泊型),新竹這個應該是影片提到的溪流型,我查了幾篇新聞報導也都是宜蘭,沒新竹的資料
2023-03-21
2023-03-22
bil
11:37:26
shufabu6000.com 不知道為什麼被連到cofacts
https://www.storm.mg/lifestyle/4685630
過去數發部的詐騙簡訊是shuweibu6000.com
圖卡中的http://shufabu6000.com/moda.gov.tw/也被連到cofacts
這實在是很可疑啊
https://www.storm.mg/lifestyle/4685630
過去數發部的詐騙簡訊是shuweibu6000.com
圖卡中的http://shufabu6000.com/moda.gov.tw/也被連到cofacts
這實在是很可疑啊
ronnywang
11:38:49
我猜可能是 @au 自己花錢買的並指到 cofacts 的 XD
mrorz
11:44:49
嗯這是彩蛋ㄛ
mrorz
11:44:58
驚喜
mrorz
11:45:56
畢竟示例裡的網址
如果被奇怪的人買走
應該會有可怕的事情發生
(想像一下立法委員拿著報紙上的政令宣導,然後說點進去之後會連到更奇怪的網站,這樣的畫面)
如果被奇怪的人買走
應該會有可怕的事情發生
(想像一下立法委員拿著報紙上的政令宣導,然後說點進去之後會連到更奇怪的網站,這樣的畫面)
cai
17:56:42
針對6000網站資安疑慮的,共同點是中央銀行退休
https://cofacts.tw/article/2fhr2drj9ajgr
https://cofacts.tw/article/tnv27x8mej45
https://cofacts.tw/article/2fhr2drj9ajgr
https://cofacts.tw/article/tnv27x8mej45
2023-03-23
cai
13:51:19
https://ec.ltn.com.tw/article/breakingnews/4248778
自由這篇有提到
> 第2,關於1次性系統,據了解,該登記系統並非1次性,而是從去年「振興五倍券」及「孩童家庭防疫補貼」的資訊系統為基礎,擴充而來,未來若有類似政策也不排除會繼續使用。
自由這篇有提到
> 第2,關於1次性系統,據了解,該登記系統並非1次性,而是從去年「振興五倍券」及「孩童家庭防疫補貼」的資訊系統為基礎,擴充而來,未來若有類似政策也不排除會繼續使用。
mrorz
14:24:15
另外 2023 年 2 月數發部會議中案一的投影片有跟普發現金平台資安相關的進度追蹤
https://moda.gov.tw/press/background-information/3961
在資安弱點偵測方面,有提及財金公司交付源碼進行檢測、做弱掃跟滲透測試、修復後再複測,這是在執行期間是否會被攻破的部分
https://moda.gov.tw/press/background-information/3961
在資安弱點偵測方面,有提及財金公司交付源碼進行檢測、做弱掃跟滲透測試、修復後再複測,這是在執行期間是否會被攻破的部分
2023-03-24
mrorz
10:55:14
大家也是滿厲害的
就算他能拿得到資料,詐騙集團會故意讓受騙人匯款進這些帳戶嗎
他車手是要怎麼拿 wwww
就算他能拿得到資料,詐騙集團會故意讓受騙人匯款進這些帳戶嗎
他車手是要怎麼拿 wwww
mrorz
10:56:08
唯一能做的事情就是害人帳戶被凍結,但詐騙集團無論如何都拿不到錢 wwwwwww
2023-03-25
2023-03-26
mrorz
00:05:59
週三會議的時候,我們談到 Cofacts 在 docker hub 上是 free team plan,之後會被收費,要提出 open source 申請的事情。
後來 Docker 反悔了 ._.
https://www.docker.com/blog/no-longer-sunsetting-the-free-team-plan/
後來 Docker 反悔了 ._.
https://www.docker.com/blog/no-longer-sunsetting-the-free-team-plan/
2023-03-27
mrorz
11:22:08
Staging 的 LINE bot 沒回過的文字訊息現在有 chatgpt response 了,可以傳還沒人回的文字訊息到 staging LINE bot 來玩玩看~
目前實作到 design doc 所規劃的部分 phase 0 與部分 phase 1 chatbot
TODO / known issue
• error handling 還沒處理
◦ 如果有兩人同時送訊息進來,稍晚的那位會拿到 `status=LOADING` 的 `AIReply`,目前會有錯。理論上這個 edge case 下,chatbot 應該裝作沒這回事就好 (?)
◦ 如果 `status=ERROR` 應該要允許重送,目前不會
• unit test 還沒寫完
◦ 還沒人回的圖片好像也會觸發 gpt response,要追 code 確認一下⋯⋯
目前實作到 design doc 所規劃的部分 phase 0 與部分 phase 1 chatbot
TODO / known issue
• error handling 還沒處理
◦ 如果有兩人同時送訊息進來,稍晚的那位會拿到 `status=LOADING` 的 `AIReply`,目前會有錯。理論上這個 edge case 下,chatbot 應該裝作沒這回事就好 (?)
◦ 如果 `status=ERROR` 應該要允許重送,目前不會
• unit test 還沒寫完
◦ 還沒人回的圖片好像也會觸發 gpt response,要追 code 確認一下⋯⋯
mrorz
19:29:27
咦,為什麼傳圖片的時候會動 XDDD
mrorz
19:29:54
傳圖片的時候我們應該沒東西可以傳給 ChatGPT 呀⋯⋯
mrorz
19:30:32
中國用語這點真的太難,畢竟 ChatGPT 拿的語料裡面簡中一定遠大於繁中
mrorz
19:31:13
頂多 system 強調「台灣的繁體中文」好了
mrorz
19:34:25
啊,應該是 submission consent 與 select article 的 webhook handler,文字與多媒體的都是共用的
mrorz
19:34:36
感謝 @iacmai 測試,晚上回家改
2023-03-28
mrorz
14:13:48
已經修復囉,現在只有傳文字才會觸發 ChatGPT
2023-03-29
mrorz
10:38:51
url-resolver 沒起來……
cai
13:09:18
mrorz
14:47:14
可能指出綠色浪潮是民間團體
訴求是改變目前政府對大麻的禁令
因此與「綠色執政」無關
之類
訴求是改變目前政府對大麻的禁令
因此與「綠色執政」無關
之類
mrorz
14:49:38
想說如果團體在 8 年前就開始活動的話,會更容易指出與執政黨無關
不過看來是 2019 年開始的
https://www.twreporter.org/a/the-marijuana-legalization-advocacy-in-taiwan
不過看來是 2019 年開始的
https://www.twreporter.org/a/the-marijuana-legalization-advocacy-in-taiwan
mrorz
14:54:08
簡單來說就是
民進黨政府也反大麻
說不定這樣反對民進黨的人們,反而會來看大麻兩眼
支持大麻就是反對民進黨w
民進黨政府也反大麻
說不定這樣反對民進黨的人們,反而會來看大麻兩眼
支持大麻就是反對民進黨w