#cofacts
2020-07-01
github
01:59:13
• Google analytics setup for LIFF • sends pageview on page change • sends user timing on LIFF load • record redirect count as redirect event
github
02:14:49
*Pull Request Test Coverage Report for <https://coveralls.io/builds/31779780|Build 978>* • *0* of *0* changed or added relevant lines in *0* files are covered. • No unchanged relevant lines lost coverage. • Overall coverage remained the same at *98.379%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
lucien
03:30:57
對的,意義上是快速複製的功能
github
05:25:58
user id is used to identify whether the current user added the category as well (so that they can remove those categories added by themselves)(in line 298), `disableVote` may be a bit confusing. it's good to extract the author check logic to upper component though
github
05:31:03
as for the mutation part it's certainly difficult to put them in appropriate place, `useMutation` is a hook and it uses closure to get required params, this means that we should put the params and `useMutation` in the same function, and at the same time consist the calling order so that it won't break hook rules
mrorz
10:26:44
本日會議紀錄
最近的會議主要會在追蹤收尾進度,以及盡量 release 已經做好且測過的東西唷
另外還有 Review 要做的新東西
https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2FU-KmeEYJTVmtCFB-bqWfGg
最近的會議主要會在追蹤收尾進度,以及盡量 release 已經做好且測過的東西唷
另外還有 Review 要做的新東西
https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2FU-KmeEYJTVmtCFB-bqWfGg
mrorz
2020-07-01 15:52:20
今晚大概要處理的事情有
- 追蹤結案進度
- 過趨勢圖表的 spec
- LINE bot release test
- Website release 複測 (上週 blocker 應該已經解了)
- LIFF API 變更討論
- 追蹤結案進度
- 過趨勢圖表的 spec
- LINE bot release test
- Website release 複測 (上週 blocker 應該已經解了)
- LIFF API 變更討論
github
13:39:37
1. `replyReference` does not look like a variable that is really needed. If we need this variable, please use `const` and replace `reply.text + '\n'` with `replyReference` instead. 2. Please remove unused comment. 3. Seems that we did not copy the reply reference to `ReferenceInput` yet?
yanglin
2020-07-01 13:57:11
啊 半夜迷糊把做到一半的 push 上去了 ==
github
13:39:37
The unit test looks clearer now :) Thanks! I think we are good to go after we implement reference copying on "Add this reply to my reply" button.
yanglin
2020-07-01 13:57:11
啊 半夜迷糊把做到一半的 push 上去了 ==
yanglin
13:57:11
啊 半夜迷糊把做到一半的 push 上去了 ==
github
14:05:21
LGTM! I am seeing this warning when running `npm run dev`, not sure if it will cause errors: ``` Warning: fragment with name ArticleWithCategories already exists. graphql-tag enforces all fragment names across your application to be unique; read more about this in the docs: <http://dev.apollodata.com/core/fragments.html#unique-names> ``` Let's see it on staging.
github
14:26:03
*Before* <https://user-images.githubusercontent.com/108608/86210185-babaf000-bba6-11ea-9111-6c086ffce5b0.png|image> *After* <https://user-images.githubusercontent.com/108608/86210121-a37c0280-bba6-11ea-9a82-471e8e69d367.png|image>
mrorz
2020-07-01 14:28:30
只有一行,但修了很重要的東西 XD
lucien
2020-07-01 14:36:08
登愣
mrorz
14:28:30
只有一行,但修了很重要的東西 XD
lucien
14:36:08
登愣
github
15:30:21
Thanks for adding `reference`. I think we should use `reply.reference` directly instead of composing from `reply.hyperlinks`. Sometimes the author of the reply may <https://old.cofacts.org/reply/ORLVmHEBrhVJn3LNJnmn|put some info in reply's reference field>, such as adding section title between hyperlinks, or provide description to URLs that is more concise to hyperlink titles.
mrorz
2020-07-02 00:46:48
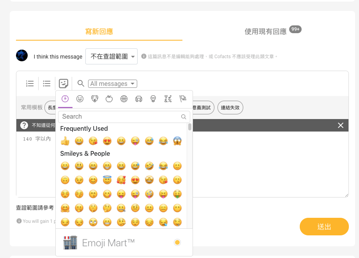
現在 staging 上有新的回應 tool bar 囉,可以搜尋過去的回應加進現在正在撰寫的回應中,也可以插入 emoji~
感謝 @yanglin5689446 👏
感謝 @yanglin5689446 👏
mrorz
2020-07-02 00:53:06
因為 production 上會把 “add category” 按鈕藏起來,所以這個版本我還是在測完之後會先上 production~
把一個月來的 bugfix 以及 editor 先出出去
把一個月來的 bugfix 以及 editor 先出出去
mrorz
2020-07-03 01:39:12
上 production 囉
mrorz
2020-07-03 10:27:48
Svelte 最近似乎有比較完整的 typescript 支援了,有機會用在 LIFF 上 ~
https://github.com/sveltejs/svelte/issues/4518#issuecomment-650635007
https://github.com/sveltejs/svelte/issues/4518#issuecomment-650635007
yanglin
2020-07-03 23:26:03
現在才看到...
加 category 的功能在 editor-toolbar 那支上面還是好的欸
我有特別修掉因為沒更新 cache 所以會更新失敗的問題
不知道為什麼 dev branch 壞了
我等等看看
加 category 的功能在 editor-toolbar 那支上面還是好的欸
我有特別修掉因為沒更新 cache 所以會更新失敗的問題
不知道為什麼 dev branch 壞了
我等等看看
yanglin
2020-07-03 23:29:33
delete 的部分
我不確定是不是 API 問題耶
因為我就是打 `UpdateArticleCategoryStatus` API 而已
不知道為什麼會爆開
我不確定是不是 API 問題耶
因為我就是打 `UpdateArticleCategoryStatus` API 而已
不知道為什麼會爆開
yanglin
2020-07-03 23:53:20
恩
不知道之前為什麼會 work
不過打 `CreateArticleCategory` API 的時候要回傳 user id 才會更新前端的 cache
不知道之前為什麼會 work
不過打 `CreateArticleCategory` API 的時候要回傳 user id 才會更新前端的 cache
mrorz
15:52:20
Replied to a thread: 2020-07-01 10:26:44
今晚大概要處理的事情有
- 追蹤結案進度
- 過趨勢圖表的 spec
- LINE bot release test
- Website release 複測 (上週 blocker 應該已經解了)
- LIFF API 變更討論
- 追蹤結案進度
- 過趨勢圖表的 spec
- LINE bot release test
- Website release 複測 (上週 blocker 應該已經解了)
- LIFF API 變更討論
github
19:06:55
*Pull Request Test Coverage Report for <https://coveralls.io/builds/31796635|Build 984>* • *26* of *44* *(59.09%)* changed or added relevant lines in *4* files are covered. • No unchanged relevant lines lost coverage. • Overall coverage decreased (*-4.7%*) to *93.679%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
2020-07-02
mrorz
00:46:48
Replied to a thread: 2020-07-01 15:30:21
現在 staging 上有新的回應 tool bar 囉,可以搜尋過去的回應加進現在正在撰寫的回應中,也可以插入 emoji~
感謝 @yanglin5689446 👏
感謝 @yanglin5689446 👏
- ❤️5
mrorz
00:53:06
因為 production 上會把 “add category” 按鈕藏起來,所以這個版本我還是在測完之後會先上 production~
把一個月來的 bugfix 以及 editor 先出出去
把一個月來的 bugfix 以及 editor 先出出去
mrorz
08:54:44
https://www.facebook.com/groups/linebot/permalink/2549701032027134/ liff 可以用 npm 載入,還有 Typescript definition

 1
1
2020-07-03
mrorz
10:27:48
Svelte 最近似乎有比較完整的 typescript 支援了,有機會用在 LIFF 上 ~
https://github.com/sveltejs/svelte/issues/4518#issuecomment-650635007
https://github.com/sveltejs/svelte/issues/4518#issuecomment-650635007
github
13:48:20
If we put cron job and web server together, there may be a case that if we have multiple instances for web server, the cron job will be triggered once for each instance, causing the job be run multiple times. I would suggest we just prepare a standalone NodeJS script that can be invoked via command line. On other environments, people can use native cron tab to trigger the script; and on Heroku, we can use <https://devcenter.heroku.com/articles/scheduler|Heroku scheduler> to schedule a run.
github
13:48:20
Since we already use `date-fns` in our application, I think we should use <https://date-fns.org/v2.14.0/docs/add|`date-fns/add`> directly, instead of implementing our own function.
github
13:48:20
I haven't reviewed the core logic in determine who to notify. Just to provide some thought on how cron job can be defined and how user can be notified. I love the test cases, they helped me a lot when understanding how each utility function works :nerd_face:
github
13:48:20
I would suggest we send flex message with button when doing multicast, so that we can hide complex LIFF URLs from users using a button with URI action.
github
13:48:20
If there are multiple instances running the web server, this may cause the cron job being run once for each instance / process. I would suggest we just implement a NodeJS script that can be run using command line. On normal production environment, the devOp can use ordinary cron tab to trigger the job; on our production environment on Heroku, we can use <https://devcenter.heroku.com/articles/scheduler|Heroku scheduler>. In this case, we won't need `CronJob` library; we just need to make sure the script works when run on CLI, just like the <https://github.com/cofacts/rumors-api/blob/master/src/scripts/cleanupUrls.js#L136-L138|hyperlink cleaning job> in rumors-api.
yanglin
23:26:03
現在才看到...
加 category 的功能在 editor-toolbar 那支上面還是好的欸
我有特別修掉因為沒更新 cache 所以會更新失敗的問題
不知道為什麼 dev branch 壞了
我等等看看
加 category 的功能在 editor-toolbar 那支上面還是好的欸
我有特別修掉因為沒更新 cache 所以會更新失敗的問題
不知道為什麼 dev branch 壞了
我等等看看
yanglin
23:29:33
delete 的部分
我不確定是不是 API 問題耶
因為我就是打 `UpdateArticleCategoryStatus` API 而已
不知道為什麼會爆開
我不確定是不是 API 問題耶
因為我就是打 `UpdateArticleCategoryStatus` API 而已
不知道為什麼會爆開
yanglin
23:53:20
恩
不知道之前為什麼會 work
不過打 `CreateArticleCategory` API 的時候要回傳 user id 才會更新前端的 cache
不知道之前為什麼會 work
不過打 `CreateArticleCategory` API 的時候要回傳 user id 才會更新前端的 cache
2020-07-04
mrorz
16:13:32
是說我在看 @ggm 的 https://github.com/cofacts/rumors-line-bot/pull/201/files 與 @acerxp511 的 https://github.com/cofacts/rumors-line-bot/pull/207/files 時發現:
• PR207 cron job 會假設所有 `UserArticleLink` 都有 `lastViewedAt`
• PR201 則有兩種建立 `UserArticleLink` 的方式:建立全新 article 時 `UserArticleLink` 就不會有 `lastViewedAt`,但若是查到現有文章,無論該文章是否有 reply,都會建立或更新 `UserArticleLink` 並且寫入 `lastViewedAt`
我想討論的是:是否需要強制 `UserArticleLink` 一定要有 `lastViewedAt` 欄位呢? (Related spec)
Note: 無論如何 `UserArticleLink.createdAt` 是一定會有而且一但寫入就不會修改的,所以不在討論範圍。
• PR207 cron job 會假設所有 `UserArticleLink` 都有 `lastViewedAt`
• PR201 則有兩種建立 `UserArticleLink` 的方式:建立全新 article 時 `UserArticleLink` 就不會有 `lastViewedAt`,但若是查到現有文章,無論該文章是否有 reply,都會建立或更新 `UserArticleLink` 並且寫入 `lastViewedAt`
我想討論的是:是否需要強制 `UserArticleLink` 一定要有 `lastViewedAt` 欄位呢? (Related spec)
Note: 無論如何 `UserArticleLink.createdAt` 是一定會有而且一但寫入就不會修改的,所以不在討論範圍。

- 😮2
nonumpa
2020-07-04 16:21:12
我沒注意到!以為 lastViewedAt 會一起 create
mrorz
2020-07-04 16:21:23
其實我是贊成 `UserArticleLink` 一律有 `lastViewedAt` 的,因為我看不出需要分「有 `lastViewedAt` 」與「無 `lastViewedAt`」的必要性~
嗯我覺得都可以,強制規定好像實作上會比較好做,只是語意上一點點點怪就是了
欸也不會,也可以這樣說,他送出文章的時候其實就是他看過文章了,所以時間點在那個當下也是合理
mrorz
2020-07-04 16:23:55
如果 `UserArticleLink` 一律有 `lastViewedAt` 的話,`UserArticleLink` 就只需要一種 create or update 的 method [註],cron job 讀取的時候也會稍微輕鬆一點,不用管 `createdAt`。
[註] 現在 `UserArticleLink` model 裡面有 3 個 method:`create` , `updateTimestamp` 跟完全沒人用的 `findOrInsertByUserIdAndArticleId` 都會 upsert `UserArticleLink`,我覺得太多了 XDD
[註] 現在 `UserArticleLink` model 裡面有 3 個 method:`create` , `updateTimestamp` 跟完全沒人用的 `findOrInsertByUserIdAndArticleId` 都會 upsert `UserArticleLink`,我覺得太多了 XDD
mrorz
2020-07-04 16:24:00
2jo4
updateTimestamp 變得有點多餘了,因為沒有那麼多 timestamp 了 😂😂
mrorz
2020-07-04 16:28:20
好喔那我們就
• 第一次 insert `UserArticleLink` 的時候 `createdAt` 與 `lastViewedAt` 都要寫
• 日後僅 update `lastViewedAt`
我會用這個當結論 review 兩位的 PR
感謝討論 m(_ _)m
• 第一次 insert `UserArticleLink` 的時候 `createdAt` 與 `lastViewedAt` 都要寫
• 日後僅 update `lastViewedAt`
我會用這個當結論 review 兩位的 PR
感謝討論 m(_ _)m
欸那 createdAt 好像也有點多餘
什麼時候會用到呀
噢就是純紀錄用
mrorz
2020-07-04 16:30:33
不會用到
但就是記著囉,第一次建立此 object 的 timestamp
但就是記著囉,第一次建立此 object 的 timestamp
mrorz
2020-07-04 16:30:59
有需要的話也可以 show 在 LIFF 裡
雖然有點沒空間 XD
雖然有點沒空間 XD
嗯
我後來把 `updateTimestamp` 改名成 `upsertByUserIdAndArticleId` ,然後把 `findOrInsertByUserIdAndArticleId` 刪掉
我覺得 `upsertByUserIdAndArticleId` 用途比較廣
其他我都改好了,剩下一個要討論的我留著沒有按 resolve,我是覺得可以把 `find()` 搬過去 `Base` ,做為每個 Model 都與生俱來(?)的方法,這樣其實 `UserSettings` 也用得到
mrorz
2020-07-05 16:05:17
同意 `upsertByUserIdAndArticleId`
也支持刪掉 `updateTimestamp`
別忘了 `create` 應該也要刪掉,因為目前沒有不是 `upsertByUserIdAndArticleId` 的 create 需求
不過我看現在最新的 commit 好像還有 `updateTimestamp` ?
然後 `Base#find` 我覺得也 OK~
也支持刪掉 `updateTimestamp`
別忘了 `create` 應該也要刪掉,因為目前沒有不是 `upsertByUserIdAndArticleId` 的 create 需求
不過我看現在最新的 commit 好像還有 `updateTimestamp` ?
然後 `Base#find` 我覺得也 OK~
咦最新的 commit 已經沒有用到 `updateTimestamp` 了耶?我漏看了嗎
啊!XDD 原來我少推一個 commit 呀
使用 `create` 的話,你是在說這段嗎?
https://github.com/cofacts/rumors-line-bot/blob/a3cda30eb414100405b1c3fd9e492308ddff8d34/src/webhook/handlers/askingArticleSubmissionConsent.js#L58
我覺得這段用 `create` 沒什麼問題呀,使用者創建的新文章 `CreateArticle.id` 一定會是新的不會重複的,一定會產生出一筆 `UserArticleLink` 所以用 `create` 很合理吧?
https://github.com/cofacts/rumors-line-bot/blob/a3cda30eb414100405b1c3fd9e492308ddff8d34/src/webhook/handlers/askingArticleSubmissionConsent.js#L58
我覺得這段用 `create` 沒什麼問題呀,使用者創建的新文章 `CreateArticle.id` 一定會是新的不會重複的,一定會產生出一筆 `UserArticleLink` 所以用 `create` 很合理吧?
你是想把這段換成 `upsertByUserIdAndArticleId` 嗎?這樣雖然是可以,但是意圖會有點奇怪會混淆吧,upsert 的用意還是以 update 為主,你想要用來全面取代 create 嗎?
mrorz
2020-07-07 11:05:41
對
我以為「所有 user article link 一定會寫入 `lastViewedAt` 」是上一段討論的共識?
如果「所有 user article link 一定會寫入 `lastViewedAt` 」那就代表 create 跟 upsert 做的事情幾乎快一樣了>
我以為「所有 user article link 一定會寫入 `lastViewedAt` 」是上一段討論的共識?
如果「所有 user article link 一定會寫入 `lastViewedAt` 」那就代表 create 跟 upsert 做的事情幾乎快一樣了>
mrorz
2020-07-07 11:07:18
至於 upsert 的語意問題
這就是為什麼我 rumors-api 類似的 API 會使用 “CreateOrUpdate” 做 API 開頭,而不是用比較常見但確實比較看重 update 的 upsert XD
這就是為什麼我 rumors-api 類似的 API 會使用 “CreateOrUpdate” 做 API 開頭,而不是用比較常見但確實比較看重 update 的 upsert XD
嗯嗯,一定會寫入 `lastViewedAt` 是有共識的。但這跟所有的操作都用 `upsert` 應該是兩回事?我所謂的意圖有點混淆是指
當使用 `create` 的時候代表,這筆 `UserArticleLink` 一定是新的一筆出現
當使用 `upsert` 的時候代表,這筆 `UserArticleLink` 可能以前存在過,後來被刪掉,就像是我們再回溯資料的時候
當使用 `create` 的時候代表,這筆 `UserArticleLink` 一定是新的一筆出現
當使用 `upsert` 的時候代表,這筆 `UserArticleLink` 可能以前存在過,後來被刪掉,就像是我們再回溯資料的時候
mrorz
2020-07-08 17:06:02
但 view article 的 case 不是「以前存在過後來被刪掉」,使用者可能過去看過,也可能從來沒看過
卻也使用 `upsertByUserIdAndArticleId`
卻也使用 `upsertByUserIdAndArticleId`
mrorz
2020-07-08 17:06:46
如果在意語意的話,我會建議用 createOrUpdate 代替 upsert
噢對啦,我要表達的意思就是,`upsert` 的用途是於我們不確定這筆東西在不在,不在的時候我們要插一筆,就我們的狀況是,以前曾經看過而沒有被記錄起來
如果只是單純做 `create` 那我覺得應該就用 `create` ,而不要用 `upsertByUserIdAndArticleId` ,因為 `upsertByUserIdAndArticleId` 隱含了更多的意思
我講一下我覺得現在這兩種狀況:
1. 若 `create` 和 `upsertByUserIdAndArticleId` 都同時存在,好處是開發者在 `askingArticleSubmissionConsent` 裡面會知道,`UserArticleLink` 在這裡是第一次創建,而在 `choosingArticle` 裡面會知道, `UserArticleLink` 以前可能存在過,
2. 若統一使用 `upsertByUserIdAndArticleId` 則少了這個訊息,然後 code 比較簡短
1. 若 `create` 和 `upsertByUserIdAndArticleId` 都同時存在,好處是開發者在 `askingArticleSubmissionConsent` 裡面會知道,`UserArticleLink` 在這裡是第一次創建,而在 `choosingArticle` 裡面會知道, `UserArticleLink` 以前可能存在過,
2. 若統一使用 `upsertByUserIdAndArticleId` 則少了這個訊息,然後 code 比較簡短
我是覺得該 `create` 就 `create` ,該 `update` 就 `update` ,如果要 atomic 的操作 update + create 就做 `upsert`
嗯⋯⋯我想了想還是照你說的改好了,我想說你在別的地方可能也是這樣實作(譬如 API 之類的),那這樣我們整體的設計會比較整齊
mrorz
2020-07-10 12:29:04
Thanks. Did you push? @ggm
推哩 也 rebase 哩
我還是有保留 `UserSettings.create` 和 `UserArticleLink.create` 他們在 test 裡面都還有被用到,也不能被 createOrUpdate 取代
nonumpa
16:21:12
我沒注意到!以為 lastViewedAt 會一起 create
mrorz
16:21:23
其實我是贊成 `UserArticleLink` 一律有 `lastViewedAt` 的,因為我看不出需要分「有 `lastViewedAt` 」與「無 `lastViewedAt`」的必要性~
ggm
16:22:31
嗯我覺得都可以,強制規定好像實作上會比較好做,只是語意上一點點點怪就是了
ggm
16:23:27
欸也不會,也可以這樣說,他送出文章的時候其實就是他看過文章了,所以時間點在那個當下也是合理
mrorz
16:23:55
如果 `UserArticleLink` 一律有 `lastViewedAt` 的話,`UserArticleLink` 就只需要一種 create or update 的 method [註],cron job 讀取的時候也會稍微輕鬆一點,不用管 `createdAt`。
[註] 現在 `UserArticleLink` model 裡面有 3 個 method:`create` , `updateTimestamp` 跟完全沒人用的 `findOrInsertByUserIdAndArticleId` 都會 upsert `UserArticleLink`,我覺得太多了 XDD
[註] 現在 `UserArticleLink` model 裡面有 3 個 method:`create` , `updateTimestamp` 跟完全沒人用的 `findOrInsertByUserIdAndArticleId` 都會 upsert `UserArticleLink`,我覺得太多了 XDD
mrorz
16:24:00
2jo4
ggm
16:25:11
updateTimestamp 變得有點多餘了,因為沒有那麼多 timestamp 了 😂😂
mrorz
16:28:20
好喔那我們就
• 第一次 insert `UserArticleLink` 的時候 `createdAt` 與 `lastViewedAt` 都要寫
• 日後僅 update `lastViewedAt`
我會用這個當結論 review 兩位的 PR
感謝討論 m(_ _)m
• 第一次 insert `UserArticleLink` 的時候 `createdAt` 與 `lastViewedAt` 都要寫
• 日後僅 update `lastViewedAt`
我會用這個當結論 review 兩位的 PR
感謝討論 m(_ _)m
ggm
16:29:12
欸那 createdAt 好像也有點多餘
ggm
16:29:40
什麼時候會用到呀
ggm
16:30:19
噢就是純紀錄用
mrorz
16:30:33
不會用到
但就是記著囉,第一次建立此 object 的 timestamp
但就是記著囉,第一次建立此 object 的 timestamp
mrorz
16:30:59
有需要的話也可以 show 在 LIFF 裡
雖然有點沒空間 XD
雖然有點沒空間 XD
ggm
16:31:04
嗯
github
16:36:23
Why don't we just use mongo client for a find query? (Also for L118) The main point of my previous comment was because `UserSetting.findOrInsertByUserId` will mutate the database to make the test pass, even when the function under test (`singleUserHandler`) does not work as expected. It did not mean we should avoid using `mongoClient` entirely ._.
github
16:36:23
Thanks for updating the PR accordingly! Named a few suggestions and added conclusion from the discussion <https://g0v-tw.slack.com/archives/C2PPMRQGP/p1593850412237300|on Slack> today.
github
16:36:23
There is already a static method called `find` in `UserArticleLink`, which is used by GraphQL resolver for `Query.userArticleLinks`. `find` was added before this branch previously branched out and is now in the file after your rebase. I think we should only leave one endpoint that lists user-article links of a user. I like the naming `findByUserId` because it is more clear (and considering that we need also to find by article id in <https://github.com/cofacts/rumors-line-bot/pull/207|#207>). But the pagination mechanism is also required by the GraphQL API. Would you merge the implementation of the two find methods into `findByUserId()`, remove `find()` and update the resolver (`graphql/resolvers/Query.js`) accordingly?
github
16:36:23
Since `choosingReply` does not involve `UserArticleLink`, I think we should not include these in test file, or it may confuse readers thinking that `choosingReply` has used `UserArticleLink`.
github
16:36:23
As discussed in slack today, we should use an API that also writes `lastViewedAt`. Also, please add `lastViewedAt` as a required field in `userArticleLink.json` to ensure that `lastViewedAt` always exists in DB.
github
16:36:23
Actually there is another method called `findOrInsertByUserIdAndArticleId` in `UserArticleLink` model, doing almost the same thing as `updateTimestamps` does, but it's not used anywhere. I suggest we should leave only one of such method in `UserArticleLink`.
github
18:32:07
1. Accepting inputting multiple `articleIds` and search by `{articleId: {$in: articleIds}}` can provide better flexibility. It should work more efficiently as well. 2. Since this API still returns `UserArticleLink`s instead of users, the `UserList` in its naming is a bit confusing. suggest using something like `findByArticleIds`.
github
18:32:07
According to <https://g0v-tw.slack.com/archives/C2PPMRQGP/p1593850412237300|our discussion on slack>, all `userArticleLink` should have `lastViewedAt`. We may need to update these fixtures to match that.
github
18:32:07
I suggest we move some of the `articleReply`'s `createdAt` outside of the queried time range because • `ListArticle(repliedAt)` includes an article as long as it has _one_ `articleReply` within the time range, thus it is possible for its results having _some_ article-replies outside the time range • Including such possibility in the test case can better cover all scenarios • Currently there are already plenty of `articleReplies` in the fixture, but all of them in the same time range. Moving some of them outside the time range can increase diversity of fixture combinations.
github
18:32:07
I have viewed the logic of cron jobs. Thanks for the contribution! As our <https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/ckUQ|open data analytics> shows, sometimes there will be more than 100 articles replied in a day. I have made some suggestions to enhance robustness of cron jobs by processing in batches. Also there are some suggestions about diversity of test fixtures.
github
18:32:07
The combination of `Promise.all` and `....map()` will cause `UserSettings.findOrInsertByUserId` being invoked in parallel. If there are `N` users to notify, this will trigger `N` queries to database _at once_. This can be dangerous when a very popular article (>100 user article links) receives a new reply. I would suggest • Divide `Object.keys(notificationList)` (user ids) into batches, size of each batch controlled by a constant. • Use for-loop with `await` in loop to make sure only 1 batch is processed at a time. • Create a new static method on `UserSettings` that reads user settings in batch and does not perform upsert. • use `findAll({userId: {$in: userIds}})` in the new method to receive batch of user settings • there is no point inserting `UserSettings` in cron jobs • skip a user when the user does not have `UserSettings` (it should never happen though, just in case)
github
18:32:07
Sending one notification for each user that receive notification may <https://developers.google.com/analytics/devguides/collection/analyticsjs/limits-quotas|hit this quota> if there are more than 20 users to send notification: > Each gtag.js and analytics.js tracker object starts with 20 hits that are replenished at a rate of 2 hits per second I think for now we can just send one event to GA that records the number of notifications we sent this time (in <https://developers.google.com/analytics/devguides/collection/analyticsjs/events|event value> so that the number adds up when query for multiple days).
github
18:32:07
These comments will be sent as part of GraphQL. I think we can remove these comments because the variable name already implies the same meaning.
github
18:32:08
For processing the articles, I would suggest 1. Use pagination to get _all_ articles that match the filter, not just first `N` articles. 2. Sequentially process each batch of `N` articles. Design APIs so that it can handle multiple articles at once. ``` // Async generator that gets a batch of articles with articleReply between `from` and `to`. // The generator encapsulates complex pagination logic so that the function using it can focus on // batch processing logic without worrying pagination. // async function* getArticlesInBatch(from, to) { // Get pageInfo outside the loop since it's expensive for rumors-api const { data: { ListArticles: { pageInfo: {lastCursor} } } } = await gql`...`({from, to}); let after = undefined; while(lastCursor !== after) { // Actually loads `edges` and process. const { data: { ListArticles } } = await gql`...`({from, to, after}); yield ListArticles.edges.map(({node}) => node); // next gql call should go after the last cursor of this page after = ListArticles.edges[ListArticles.edges.length - 1].cursor; } } async function getNotificationList(lastScannedAt, nowWithOffset) { const result = {}; // for loop ensures that only one batch will be processed at a time, so that we do not // make a bunch of queries to our MongoDB at once. // for await (const articles of getArticlesInBatch(lastScannedAt, nowWithOffset)) { // Process the batch // Make an API that processes a batch of articleIds, instead of only one ID at a time const userArticleLinks = await UserArticleLink.findByArticleIds(articles.map(({id}) => id)); userArticleLinks.forEach(/* Logic that populates result */) } return result; } ```
github
19:05:06
Still can't remove a category added by myself from the article detail page. The category first seems to deleted, but re-appear after refresh. I am seeing this warning in console. Not sure if it is relevant. > Warning: fragment with name ArticleWithCategories already exists. > graphql-tag enforces all fragment names across your application to be unique; read more about > this in the docs: <http://dev.apollodata.com/core/fragments.html#unique-names|http://dev.apollodata.com/core/fragments.html#unique-names> I found that • there is no `status` exist in fetched `articleCategories` in apollo cache. • when querying article's `articleCategories` we did not specify `(status: NORMAL)` in GraphQL. I guess that's probably why all `articleCategories` are fetched and displayed. Since the display logic actually do not involve `status`, I suggest specifying `(status: NORMAL)` when querying `articleCategories` in article detail page.
2020-07-05
github
02:34:11
Hmm, because you say `using MongoDb commands` :joy::joy: . It's a bit confusing for me, but doing mongo CLI is also quick, then I made it haha
github
03:35:50
How about we move `find()` into `src/database/models/base.js` ? So that all models can use `find()` just like they already have `findOneAndUpdate`. As a result, `findByUserId()` is for listing user-article links in UserArticleLink, and `find()` is for general use in all models.
ggm
05:30:50
Replied to a thread: 2020-07-04 16:13:32
我後來把 `updateTimestamp` 改名成 `upsertByUserIdAndArticleId` ,然後把 `findOrInsertByUserIdAndArticleId` 刪掉
ggm
05:31:38
我覺得 `upsertByUserIdAndArticleId` 用途比較廣
ggm
05:37:39
其他我都改好了,剩下一個要討論的我留著沒有按 resolve,我是覺得可以把 `find()` 搬過去 `Base` ,做為每個 Model 都與生俱來(?)的方法,這樣其實 `UserSettings` 也用得到
github
10:59:12
But mongodb already have a method named `find()`. I would like to see `findXXX` methods directly invoking methods of mongodb client. Adding one more layer to `find()` is a bit over-engineered to me.
mrorz
2020-07-05 11:13:34
(這個 comment 後來從 github 刪掉囉)
github
11:10:22
Agree adding `find()` to `Base` so that `Base` API is more consistent :woman-gesturing-ok:
mrorz
11:13:34
(這個 comment 後來從 github 刪掉囉)
ggm
12:53:18
是說我昨天犯蠢,我不小心 `git rebase master` 推上去,但我後來又有 `git rebase dev` 推回去,我有檢查一遍應該是沒有改壞,如果看到哪裡有怪異現象(?)可能就是我 rebase 沒改好
mrorz
2020-07-05 15:13:26
我看線圖應該是對的唷
mrorz
15:13:26
我看線圖應該是對的唷
mrorz
16:05:17
同意 `upsertByUserIdAndArticleId`
也支持刪掉 `updateTimestamp`
別忘了 `create` 應該也要刪掉,因為目前沒有不是 `upsertByUserIdAndArticleId` 的 create 需求
不過我看現在最新的 commit 好像還有 `updateTimestamp` ?
然後 `Base#find` 我覺得也 OK~
也支持刪掉 `updateTimestamp`
別忘了 `create` 應該也要刪掉,因為目前沒有不是 `upsertByUserIdAndArticleId` 的 create 需求
不過我看現在最新的 commit 好像還有 `updateTimestamp` ?
然後 `Base#find` 我覺得也 OK~
github
17:24:38
Discussion: <https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2F%40mrorz%2FByKAmKITU|https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2F%40mrorz%2FByKAmKITU> > orz: Google 有針對 ClaimReview 做一個專門的 search box 耶:<https://toolbox.google.com/factcheck/explorer|https://toolbox.google.com/factcheck/explorer> (預設只會顯示瀏覽器語言的 fact-check result) > 好像也有 Search API: <https://toolbox.google.com/factcheck/apis|https://toolbox.google.com/factcheck/apis> > Lucien: 要不要做在 API server > 就能查完直接送進 DB > 或者轉換為一種 reply
github
17:35:00
Spec: <https://g0v.hackmd.io/dYT7zCPGQiKsTne7-kkybw|https://g0v.hackmd.io/dYT7zCPGQiKsTne7-kkybw> Directions: only show deleted article-reply to its author
mrorz
17:39:17
接下來我會把 Cofacts Next 上一階段的未竟事項開成票放在 issue 裡頭追蹤。
這裏希望麻煩 @stbb1025 把之前這份投影片裡提到的 enhancement 中,production 上已經達成的部份做上記號(綠色勾勾之類的),這樣比較方便我整理還沒做的東西 >“< 感謝感謝
https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit
這裏希望麻煩 @stbb1025 把之前這份投影片裡提到的 enhancement 中,production 上已經達成的部份做上記號(綠色勾勾之類的),這樣比較方便我整理還沒做的東西 >“< 感謝感謝
https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit
- 🔮1
mrorz
2020-07-05 18:12:31
也麻煩 @yanglin5689446 更新一下這裡唷
https://github.com/orgs/cofacts/projects/5
因為 note 沒有標 issue / PR 所以我不太確定哪些該移動 >“<
在你更新完之後,我再將 Todo item 開成票~
https://github.com/orgs/cofacts/projects/5
因為 note 沒有標 issue / PR 所以我不太確定哪些該移動 >“<
在你更新完之後,我再將 Todo item 開成票~
stbb1025
2020-07-05 19:37:42
好👌以主站的狀態為主嗎?
mrorz
2020-07-05 19:57:27
目前是跟主站一樣沒錯
stbb1025
2020-07-05 22:04:05
好👌
stbb1025
2020-07-06 23:06:11
https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.g8a84f82e3a_0_0
我把目前已經達成的部份標乘綠色字囉
還未達成的部份維持紅色
我把目前已經達成的部份標乘綠色字囉
還未達成的部份維持紅色
stbb1025
2020-07-06 23:06:23
*標成
stbb1025
2020-07-06 23:07:29
(我是使用firefox)
mrorz
2020-07-07 01:02:17
感謝感謝 🙏
mrorz
18:12:31
也麻煩 @yanglin5689446 更新一下這裡唷
https://github.com/orgs/cofacts/projects/5
因為 note 沒有標 issue / PR 所以我不太確定哪些該移動 >“<
在你更新完之後,我再將 Todo item 開成票~
https://github.com/orgs/cofacts/projects/5
因為 note 沒有標 issue / PR 所以我不太確定哪些該移動 >“<
在你更新完之後,我再將 Todo item 開成票~
stbb1025
19:37:42
好👌以主站的狀態為主嗎?
mrorz
19:57:27
目前是跟主站一樣沒錯
stbb1025
22:04:05
好👌
2020-07-06
mrorz
01:55:43
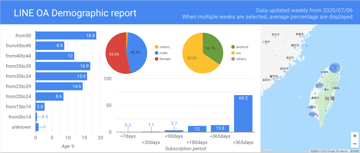
今天花了點時間把 Google data studio 跟 LINE 的 follower & demography API 串起來囉!
Google Apps script 會把 Cofacts chatbot 的 LINE OA 資料透過開在 chatbot 上的 GraphQL endpoint 拉下來,然後寫進 Google spreadsheet;Google data studio 再以上面的 spreadsheet 作為資料源來畫圖。
Follower count 每天凌晨更新,Demography 則每週三凌晨更新唷。
Google Apps script 會把 Cofacts chatbot 的 LINE OA 資料透過開在 chatbot 上的 GraphQL endpoint 拉下來,然後寫進 Google spreadsheet;Google data studio 再以上面的 spreadsheet 作為資料源來畫圖。
Follower count 每天凌晨更新,Demography 則每週三凌晨更新唷。
- 🚀3
 2
2
github
20:55:05
<https://coveralls.io/builds/31882251|Coverage Status> Coverage remained the same at 86.826% when pulling *<https://github.com/cofacts/rumors-api/commit/b65fd038d3a7575e6835d297b21f357675c84f9f|b65fd03> on readme_grpc* into *<https://github.com/cofacts/rumors-api/commit/8ca66a996c9cb8e09da67c5d05e71d32e875ff77|8ca66a9> on master*.
stbb1025
23:06:11
https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.g8a84f82e3a_0_0
我把目前已經達成的部份標乘綠色字囉
還未達成的部份維持紅色
我把目前已經達成的部份標乘綠色字囉
還未達成的部份維持紅色
stbb1025
23:06:23
*標成
stbb1025
23:07:29
(我是使用firefox)
2020-07-07
mrorz
01:02:17
感謝感謝 🙏
ggm
02:46:45
咦最新的 commit 已經沒有用到 `updateTimestamp` 了耶?我漏看了嗎
ggm
02:50:42
啊!XDD 原來我少推一個 commit 呀
ggm
04:05:57
使用 `create` 的話,你是在說這段嗎?
https://github.com/cofacts/rumors-line-bot/blob/a3cda30eb414100405b1c3fd9e492308ddff8d34/src/webhook/handlers/askingArticleSubmissionConsent.js#L58
我覺得這段用 `create` 沒什麼問題呀,使用者創建的新文章 `CreateArticle.id` 一定會是新的不會重複的,一定會產生出一筆 `UserArticleLink` 所以用 `create` 很合理吧?
https://github.com/cofacts/rumors-line-bot/blob/a3cda30eb414100405b1c3fd9e492308ddff8d34/src/webhook/handlers/askingArticleSubmissionConsent.js#L58
我覺得這段用 `create` 沒什麼問題呀,使用者創建的新文章 `CreateArticle.id` 一定會是新的不會重複的,一定會產生出一筆 `UserArticleLink` 所以用 `create` 很合理吧?
ggm
04:12:58
你是想把這段換成 `upsertByUserIdAndArticleId` 嗎?這樣雖然是可以,但是意圖會有點奇怪會混淆吧,upsert 的用意還是以 update 為主,你想要用來全面取代 create 嗎?
mrorz
11:05:41
對
我以為「所有 user article link 一定會寫入 `lastViewedAt` 」是上一段討論的共識?
如果「所有 user article link 一定會寫入 `lastViewedAt` 」那就代表 create 跟 upsert 做的事情幾乎快一樣了>
我以為「所有 user article link 一定會寫入 `lastViewedAt` 」是上一段討論的共識?
如果「所有 user article link 一定會寫入 `lastViewedAt` 」那就代表 create 跟 upsert 做的事情幾乎快一樣了>
mrorz
11:07:18
至於 upsert 的語意問題
這就是為什麼我 rumors-api 類似的 API 會使用 “CreateOrUpdate” 做 API 開頭,而不是用比較常見但確實比較看重 update 的 upsert XD
這就是為什麼我 rumors-api 類似的 API 會使用 “CreateOrUpdate” 做 API 開頭,而不是用比較常見但確實比較看重 update 的 upsert XD
ichieh
12:24:58
Hi Cofact 的大家~ 7 月大松終於回到實體中研院了,所以要找主持人~ 想問看看 Cofacts 這次能不能幫忙這個重要的任務!😆😆
沒問題唷Cofacts接,聽說大家都會輪一次(?)主持人是不是要早起
ichieh
2020-07-07 16:19:31
bil
13:27:15
沒問題唷Cofacts接,聽說大家都會輪一次(?)主持人是不是要早起
ichieh
16:19:31
Replied to a thread: 2020-07-07 12:24:58
HackMD
## 大松主持會議 - 各專案外包主持小心得 ### 源起 揪松團想成為更為多中心化的組織,因此將每次大松的「例行主持」外包給其他單位。 ### 例行主持工作內容 0. 松前哈拉 1. 介紹新手教
 1
1 1
1- ❤️1
- 🦒1
 1
1
github
21:37:40
added schema for analytics per spec at <https://g0v.hackmd.io/0kjaVlFASSyddkltqGR6Nw|https://g0v.hackmd.io/0kjaVlFASSyddkltqGR6Nw>
stbb1025
22:20:57
電腦版 top bar 我都加上了灰色分隔線
但是我覺得還是不加視覺上比較簡潔 一致 QQ
還是有辦法往下捲蓋到其他白色區塊的時候再出現灰色分隔線嗎?這樣會不會比較好?
@lucien @mrorz @yanglin5689446
但是我覺得還是不加視覺上比較簡潔 一致 QQ
還是有辦法往下捲蓋到其他白色區塊的時候再出現灰色分隔線嗎?這樣會不會比較好?
@lucien @mrorz @yanglin5689446
stbb1025
2020-07-07 22:22:52
或大家覺得分隔線ok的話那就維持修改完的灰色分隔線版本~
mrorz
2020-07-07 23:15:03
如果增加一條跟背景一樣顏色的分隔線呢
這樣也能達成「下捲前看不到」「到白色區塊時分開」的效果
甚至還會有神奇的負空間感
這樣也能達成「下捲前看不到」「到白色區塊時分開」的效果
甚至還會有神奇的負空間感
stbb1025
2020-07-07 23:29:20
欸我覺得不錯耶 XD
lucien
2020-07-09 13:45:05
我覺得因為我們 Filter UI 也有灰線,所以用類似的顏色感覺還行。
mrorz
2020-07-09 13:52:35
其實我覺得我們三連 filter 中間的灰線好像有點深,如果直接用底色區隔或許可能不錯
stbb1025
2020-07-14 11:30:50
Filter中間的灰線如果改跟背景一樣看起來會變成三個區塊
mrorz
2020-07-15 13:17:49
好ㄅ
stbb1025
22:22:52
或大家覺得分隔線ok的話那就維持修改完的灰色分隔線版本~
mrorz
23:15:03
如果增加一條跟背景一樣顏色的分隔線呢
這樣也能達成「下捲前看不到」「到白色區塊時分開」的效果
甚至還會有神奇的負空間感
這樣也能達成「下捲前看不到」「到白色區塊時分開」的效果
甚至還會有神奇的負空間感
stbb1025
23:29:20
欸我覺得不錯耶 XD
2020-07-08
ba
09:37:03
@angel112811a has joined the channel
github
10:20:17
LGTM! Sorting imports and exports looks so organized. I think we can also include the `docUsrrId` as discussed in one of the comment <https://g0v.hackmd.io/0kjaVlFASSyddkltqGR6Nw|https://g0v.hackmd.io/0kjaVlFASSyddkltqGR6Nw>
github
15:55:31
This should make pusing & cloning this repo easier <https://github.blog/2018-07-30-git-lfs-2-5-0-now-available/|https://github.blog/2018-07-30-git-lfs-2-5-0-now-available/>
ggm
16:17:36
嗯嗯,一定會寫入 `lastViewedAt` 是有共識的。但這跟所有的操作都用 `upsert` 應該是兩回事?我所謂的意圖有點混淆是指
當使用 `create` 的時候代表,這筆 `UserArticleLink` 一定是新的一筆出現
當使用 `upsert` 的時候代表,這筆 `UserArticleLink` 可能以前存在過,後來被刪掉,就像是我們再回溯資料的時候
當使用 `create` 的時候代表,這筆 `UserArticleLink` 一定是新的一筆出現
當使用 `upsert` 的時候代表,這筆 `UserArticleLink` 可能以前存在過,後來被刪掉,就像是我們再回溯資料的時候
mrorz
17:06:02
但 view article 的 case 不是「以前存在過後來被刪掉」,使用者可能過去看過,也可能從來沒看過
卻也使用 `upsertByUserIdAndArticleId`
卻也使用 `upsertByUserIdAndArticleId`
mrorz
17:06:46
如果在意語意的話,我會建議用 createOrUpdate 代替 upsert
ggm
19:41:07
噢對啦,我要表達的意思就是,`upsert` 的用途是於我們不確定這筆東西在不在,不在的時候我們要插一筆,就我們的狀況是,以前曾經看過而沒有被記錄起來
ggm
19:49:59
如果只是單純做 `create` 那我覺得應該就用 `create` ,而不要用 `upsertByUserIdAndArticleId` ,因為 `upsertByUserIdAndArticleId` 隱含了更多的意思
ggm
20:00:02
我講一下我覺得現在這兩種狀況:
1. 若 `create` 和 `upsertByUserIdAndArticleId` 都同時存在,好處是開發者在 `askingArticleSubmissionConsent` 裡面會知道,`UserArticleLink` 在這裡是第一次創建,而在 `choosingArticle` 裡面會知道, `UserArticleLink` 以前可能存在過,
2. 若統一使用 `upsertByUserIdAndArticleId` 則少了這個訊息,然後 code 比較簡短
1. 若 `create` 和 `upsertByUserIdAndArticleId` 都同時存在,好處是開發者在 `askingArticleSubmissionConsent` 裡面會知道,`UserArticleLink` 在這裡是第一次創建,而在 `choosingArticle` 裡面會知道, `UserArticleLink` 以前可能存在過,
2. 若統一使用 `upsertByUserIdAndArticleId` 則少了這個訊息,然後 code 比較簡短
ggm
20:04:25
我是覺得該 `create` 就 `create` ,該 `update` 就 `update` ,如果要 atomic 的操作 update + create 就做 `upsert`
ggm
20:52:05
嗯⋯⋯我想了想還是照你說的改好了,我想說你在別的地方可能也是這樣實作(譬如 API 之類的),那這樣我們整體的設計會比較整齊
github
21:35:09
*Server side todo list* ☑︎ update schema <https://github.com/cofacts/rumors-db/pull/44|cofacts/rumors-db#44> ☐ fetch data from google analytics and store in elasticsearch ☑︎ oAuth & google API ☐ insert/upsert data to elasticsearch & query to populate docUserId ☐ unit test ☐ data loader: (article ids) -> stats ☐ unit test ☐ new API endpoint to query for stats of a particular article ☐ unit test
2020-07-09
mrorz
02:26:30
LINE messaging API 現在連 ngrok 是不是怪怪的呀 @@
我的 ngrok HTTPS 可以用瀏覽器直連,但用 LINE 戳的時候連 request 都沒送進 ngrok⋯⋯
我的 ngrok HTTPS 可以用瀏覽器直連,但用 LINE 戳的時候連 request 都沒送進 ngrok⋯⋯
mrorz
02:29:55
看來就是不穩 (攤手)
github
03:52:54
Fix release blocker found in 20200708 meeting <https://g0v.hackmd.io/ehzopA3fScSn9PjkBM79bA#%E2%9B%94%EF%B8%8F-Release-Blockers|https://g0v.hackmd.io/ehzopA3fScSn9PjkBM79bA#%E2%9B%94%EF%B8%8F-Release-Blockers> *Typo fix* <https://user-images.githubusercontent.com/108608/86963788-a2933400-c197-11ea-81a6-e2600db09577.png|image> *Translation* The original variable collides with other occurrence. Fixed translation by choosing a different variable name. Note: actually there are some other places that has variable name collision, but ttag still works there. Not sure it does not work this time. <https://user-images.githubusercontent.com/108608/86963620-65c73d00-c197-11ea-909c-cfed763cf979.png|image>
github
03:56:01
*Pull Request Test Coverage Report for <https://coveralls.io/builds/31948667|Build 1018>* • *1* of *1* *(100.0%)* changed or added relevant line in *1* file are covered. • No unchanged relevant lines lost coverage. • Overall coverage remained the same at *98.379%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
mrorz
12:15:42
/github subscribe list features
mrorz
12:16:06
/github subscribe list features
github
12:16:06
<https://github.com/cofacts|cofacts> `issues`, `pulls`, `public`, `comments`, `reviews`
mrorz
12:16:56
/github unsubscribe cofacts public
github
13:42:49
New release scheduled for 2020/7/10 midnight. *Features* <https://github.com/cofacts/rumors-line-bot/pull/185|#185> User setting LIFF <https://github.com/cofacts/rumors-line-bot/pull/197|#197> Loads user article link <https://github.com/cofacts/rumors-line-bot/pull/198|#198> Lists user article link and data from Cofacts API <https://github.com/cofacts/rumors-line-bot/pull/199|#199> Styling user article link LIFF <https://github.com/cofacts/rumors-line-bot/pull/200|#200> Handle clicking user article link <https://github.com/cofacts/rumors-line-bot/pull/203|#203> user article link pagination *Refactor item* <https://github.com/cofacts/rumors-line-bot/pull/194|#194> LIFF auth check relaxed <https://github.com/cofacts/rumors-line-bot/pull/195|#195> Svelte eslint <https://github.com/cofacts/rumors-line-bot/pull/196|#196> unit test for svelte *Bugfix* <https://github.com/cofacts/rumors-line-bot/pull/208|#208> translation fix *Release test result* <https://g0v.hackmd.io/ehzopA3fScSn9PjkBM79bA#Testing-checklist|https://g0v.hackmd.io/ehzopA3fScSn9PjkBM79bA#Testing-checklist>
lucien
13:45:05
我覺得因為我們 Filter UI 也有灰線,所以用類似的顏色感覺還行。
github
13:45:46
*Pull Request Test Coverage Report for <https://coveralls.io/builds/31957857|Build 1020>* • *139* of *139* *(100.0%)* changed or added relevant lines in *12* files are covered. • No unchanged relevant lines lost coverage. • Overall coverage decreased (*-0.06%*) to *98.379%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
mrorz
13:52:35
其實我覺得我們三連 filter 中間的灰線好像有點深,如果直接用底色區隔或許可能不錯
2020-07-10
github
02:04:19
mrorz
2020-07-10 10:45:05
凌晨已經 release 新版 chatbot 囉~
https://github.com/cofacts/rumors-line-bot/releases/tag/release%2F20200710
這次上的主要是跟「已讀訊息列表」以及 notification 設定相關的變更。不過,測試時就有發現設定上似乎有些問題、導致「已讀訊息列表」一直打不開。
所幸目前兩個功能都還沒開放讓使用者直接使用,先把這些 code 放上 production 看看是否會影響正常功能運作,就是這次觀察的重點了。
https://github.com/cofacts/rumors-line-bot/releases/tag/release%2F20200710
這次上的主要是跟「已讀訊息列表」以及 notification 設定相關的變更。不過,測試時就有發現設定上似乎有些問題、導致「已讀訊息列表」一直打不開。
所幸目前兩個功能都還沒開放讓使用者直接使用,先把這些 code 放上 production 看看是否會影響正常功能運作,就是這次觀察的重點了。
nonumpa
2020-07-10 10:52:44
上面那個 gif 是怎麼回事...
mrorz
2020-07-10 12:04:08
因為是 release
mrorz
10:45:05
Replied to a thread: 2020-07-10 02:04:19
凌晨已經 release 新版 chatbot 囉~
https://github.com/cofacts/rumors-line-bot/releases/tag/release%2F20200710
這次上的主要是跟「已讀訊息列表」以及 notification 設定相關的變更。不過,測試時就有發現設定上似乎有些問題、導致「已讀訊息列表」一直打不開。
所幸目前兩個功能都還沒開放讓使用者直接使用,先把這些 code 放上 production 看看是否會影響正常功能運作,就是這次觀察的重點了。
https://github.com/cofacts/rumors-line-bot/releases/tag/release%2F20200710
這次上的主要是跟「已讀訊息列表」以及 notification 設定相關的變更。不過,測試時就有發現設定上似乎有些問題、導致「已讀訊息列表」一直打不開。
所幸目前兩個功能都還沒開放讓使用者直接使用,先把這些 code 放上 production 看看是否會影響正常功能運作,就是這次觀察的重點了。
nonumpa
10:52:44
上面那個 gif 是怎麼回事...
mrorz
12:04:08
因為是 release
github
12:58:08
As <https://g0v.hackmd.io/eIeU2g86Tfu5VnLazNfUvQ#%E8%B3%87%E6%96%99%E8%A1%A8%EF%BC%9AUserArticleLinks|we recently discussed>, we no longer need to populate `lastRepliedAt` :free:
github
14:13:40
mrorz
2020-07-10 14:20:07
關於 `utm_source` 與 `utm_medium` 的部分,我覺得可以這樣做:
https://g0v.hackmd.io/eIeU2g86Tfu5VnLazNfUvQ?view#2020710-Update
目前看起來只要 LIFF url 帶上 `utm_source`、`utm_medium` (如:
`https://liff.line.me/<ID>/liff/index.html?p=articles&utm_source=rumors-line-bot&utm_medium=rich-menu` ),LIFF 裡頭的 google analytics 就會 pick it up。
目前還沒實作「點擊文章回到 chatbot」之後的追蹤,那個會改到 webhook,所以想分到下一個 PR 去。
Notification 部分的 `utm_` 就要麻煩 @acerxp511 更新 notification 相關的 code 惹
https://g0v.hackmd.io/eIeU2g86Tfu5VnLazNfUvQ?view#2020710-Update
目前看起來只要 LIFF url 帶上 `utm_source`、`utm_medium` (如:
`https://liff.line.me/<ID>/liff/index.html?p=articles&utm_source=rumors-line-bot&utm_medium=rich-menu` ),LIFF 裡頭的 google analytics 就會 pick it up。
目前還沒實作「點擊文章回到 chatbot」之後的追蹤,那個會改到 webhook,所以想分到下一個 PR 去。
Notification 部分的 `utm_` 就要麻煩 @acerxp511 更新 notification 相關的 code 惹
mrorz
2020-07-10 14:27:12
是說 LINE notify 的訊息應該會發在 Cofacts OA 之外的地方(如名為 `Line Notify` 的聊天視窗)。如果 push message 裡面放的是 LIFF 的 URL,那點擊 LIFF 內的文章連結,那好像會 send 訊息進名為 `Line Notify` 的聊天視窗 囧
mrorz
14:20:07
關於 `utm_source` 與 `utm_medium` 的部分,我覺得可以這樣做:
https://g0v.hackmd.io/eIeU2g86Tfu5VnLazNfUvQ?view#2020710-Update
目前看起來只要 LIFF url 帶上 `utm_source`、`utm_medium` (如:
`https://liff.line.me/<ID>/liff/index.html?p=articles&utm_source=rumors-line-bot&utm_medium=rich-menu` ),LIFF 裡頭的 google analytics 就會 pick it up。
目前還沒實作「點擊文章回到 chatbot」之後的追蹤,那個會改到 webhook,所以想分到下一個 PR 去。
Notification 部分的 `utm_` 就要麻煩 @acerxp511 更新 notification 相關的 code 惹
https://g0v.hackmd.io/eIeU2g86Tfu5VnLazNfUvQ?view#2020710-Update
目前看起來只要 LIFF url 帶上 `utm_source`、`utm_medium` (如:
`https://liff.line.me/<ID>/liff/index.html?p=articles&utm_source=rumors-line-bot&utm_medium=rich-menu` ),LIFF 裡頭的 google analytics 就會 pick it up。
目前還沒實作「點擊文章回到 chatbot」之後的追蹤,那個會改到 webhook,所以想分到下一個 PR 去。
Notification 部分的 `utm_` 就要麻煩 @acerxp511 更新 notification 相關的 code 惹
mrorz
14:27:12
是說 LINE notify 的訊息應該會發在 Cofacts OA 之外的地方(如名為 `Line Notify` 的聊天視窗)。如果 push message 裡面放的是 LIFF 的 URL,那點擊 LIFF 內的文章連結,那好像會 send 訊息進名為 `Line Notify` 的聊天視窗 囧
github
18:17:10
write a script to fetch page view stats from google analytics and store in elasticsearch ☑︎ oAuth & google API ☐ query to populate docUserId ☐ insert/upsert data to elasticsearch ☐ unit test
github
18:20:09
implement a data loader that returns page view stats when given article ids ☐ data loader: (article ids) -> stats ☐ unit test
2020-07-11
mrorz
14:21:26
github
14:28:03
Implement hyperlink folding when there are more than 4 hyperlinks. <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=2079%3A939|Visual spec> <https://user-images.githubusercontent.com/108608/87218122-81426b80-c382-11ea-9f4b-d8852d09f385.png|image> • 1~3 hyperlinks: show all • 4+ hyperlinks: fold to 2 hyperlinks and a "show" button • No "collapse" button after expansion
github
14:50:37
The ribbon tails are not aligned in narrower screen: <https://user-images.githubusercontent.com/108608/85220902-e3422d80-b3e1-11ea-8c1f-719c6cd6f15a.png|image> (Actually the ribbon in the profile menu is not aligned either.) Since it's difficult calculating border-size to place these triangles, I would suggest using svg instead. It's shape is so simple that we can write the svg <https://www.oxxostudio.tw/articles/201406/svg-04-path-1.html|by hand>: ``` <svg viewBox="0 0 1 2"> <path d="M0 0 H1 L0 1 L1 2 H0 Z" /> </svg> ``` And we get a ribbon tail that we can resize and recolor using CSS. _Originally posted by <https://github.com/MrOrz|@MrOrz> in <https://github.com/cofacts/rumors-site/pull/264|#264>_
github
14:59:35
*As-is* <https://user-images.githubusercontent.com/108608/87218656-4262e480-c387-11ea-8b3a-2546fda7d756.png|image> *To-be* Interactions like this: <https://user-images.githubusercontent.com/108608/87218543-6540c900-c386-11ea-9f10-297ae7260953.gif|interactions> This interaction should be achieved by • performing list processing logic (in <https://github.com/cofacts/rumors-site/blob/dev/lib/editor.js|lib/editor>) when "enter" is pressed and when toolbar button is pressed • when performing logic, find the line the cursor is in, then add / remove "- " or "N. " accordingly • [nice-to-have] support predefined set of list bullets `-`, `*`, or `•` in <https://g0v.hackmd.io/Cx7dQo3YTQS4KwYmYCBY8w#%E6%92%B0%E5%AF%AB%E6%96%B0%E5%9B%9E%E6%87%89|spec> and/or numbering `1.`, `1️⃣`, etc
github
18:10:41
As discussed in <https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2F%40mrorz%2Fr1dQQZbmU|20200212 meeting>, we want to allow editor to edit their reply when • The reply is only used by the editor itself (the author should know the impact of the edit) • The reply has not yet received any feedback (the edit should now invalidate user's feedbacks) We plan to add 1 mutation API, and one new field to `Reply` type for this: ``` """ The reason why the editor cannot edit """ enum ReplyUpdateBlocker { NOT_AUTHORIZED # Not logged in or not the author of reply HAS_FEEDBACK USED_BY_OTHER_EDITORS } type Reply { """ The reason why the current user cannot edit this reply. null if the current user can edit. The blockers are determined in the following order: (1) current user is the author or not (2) `positiveFeedbackCount` and `negativeFeedbackCount` are both 0 or not (3) all normal article-reply to this article are by the current author or not """ updateBlocker: ReplyUpdateBlocker } mutation { """ Updates reply text, type & reference when (1) current user is the author (2) `positiveFeedbackCount` and `negativeFeedbackCount` are both 0 (3) all normal article-reply to this article are by the current author """ UpdateReply( replyId: String! text: String type: ReplyTypeEnum reference: String waitForHyperlinks: Boolean = false ) { ""' The reply after update. `null` when update is not successful """ reply: Reply """ The reason why update fails. null when can update. """ blocker: ReplyUpdateBlocker } } ``` "all normal article-reply to this article are by the current author" can be achieved by loading article-reply of a reply using <https://github.com/cofacts/rumors-api/blob/master/src/graphql/dataLoaders/articleRepliesByReplyIdLoaderFactory.js|`articleRepliesByReplyIdLoader`> and check each article-reply's author ID.
mrorz
2020-07-11 18:26:36
5k4ek7
lucien
2020-07-12 00:19:44
我明天整理給你
lucien
2020-07-12 20:19:26
1. 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
lucien
2020-07-12 20:27:15
2. 我自己現在的 Graphql mutation 結果設計是用前 medium 的設計延伸的,所有的操作不是權限跟 input 格式問題的話,都統一回傳 <Mutation>Result 。 Result 是 錯誤 Type 跟 成功結果的 union。
```Type Reply {...}
interface UserError {
message: String!
}
Type IsBlockedError extend UserError {
message: String!
// other props you want to show
}
union UpdateReplyResult = Reply | IsBlockedError
Mutation {
updateReply(input: UpdateReplyInput!): UpdateReplyResult!
}```
```Type Reply {...}
interface UserError {
message: String!
}
Type IsBlockedError extend UserError {
message: String!
// other props you want to show
}
union UpdateReplyResult = Reply | IsBlockedError
Mutation {
updateReply(input: UpdateReplyInput!): UpdateReplyResult!
}```
mrorz
2020-07-13 00:30:32
> 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面兩個 issue:
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面兩個 issue:
mrorz
2020-07-13 00:35:07
> 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面 issue:
1. 我自己的使用習慣是會蒐集 N 個類似訊息、寫一個回應,然後通通連結到同一個回應。如果我發現原始回應有錯字想改、或是想到更好的寫法或出處,我就要改 N 次。
2. duplicate 之後再進行修改,此 articleReply 的 id 仍然保留原本 reply,但 reply text 可能已經不同。在 text 不一樣的狀況下,我們還能說這個 reply id 有連結到此 article 嗎?
3. 承 2,目前「加入現有回應」搜尋結果,其實會過濾掉已經被加過的回應。如果現在某人加了回應 `R` 並且修改內容為 `R'`(但仍然使用 `R` 的 ID)。之後,另外一個編輯看到了,覺得應該要用 `R` 比較好,但他搜尋時就會很納悶怎麼沒有 `R` 。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面 issue:
1. 我自己的使用習慣是會蒐集 N 個類似訊息、寫一個回應,然後通通連結到同一個回應。如果我發現原始回應有錯字想改、或是想到更好的寫法或出處,我就要改 N 次。
2. duplicate 之後再進行修改,此 articleReply 的 id 仍然保留原本 reply,但 reply text 可能已經不同。在 text 不一樣的狀況下,我們還能說這個 reply id 有連結到此 article 嗎?
3. 承 2,目前「加入現有回應」搜尋結果,其實會過濾掉已經被加過的回應。如果現在某人加了回應 `R` 並且修改內容為 `R'`(但仍然使用 `R` 的 ID)。之後,另外一個編輯看到了,覺得應該要用 `R` 比較好,但他搜尋時就會很納悶怎麼沒有 `R` 。
mrorz
2020-07-13 00:44:00
把 success 的結果跟 error 的結構 union 起來很酷!感謝分享。
感覺這除了用在 `UpdateReply` 的結果之外,似乎還可以用在 `Reply` 回傳「此使用者是否可以更新這個 reply」的結果——此欄位可以回傳 `boolean | Error1 | Error 2 | Error3` 之類的東西
感覺這除了用在 `UpdateReply` 的結果之外,似乎還可以用在 `Reply` 回傳「此使用者是否可以更新這個 reply」的結果——此欄位可以回傳 `boolean | Error1 | Error 2 | Error3` 之類的東西
mrorz
2020-07-13 16:26:56
想問 @lucien 有沒有遇到某個 field return type 是個 list,但又想要幫他加個 error type 的狀況。
因為 GraphQL union 只支援 named object type,這樣要 union 的話,不是 error 也要放進 list 裡,就是 list 本人要包一個醜醜的 object type QQ
因為 GraphQL union 只支援 named object type,這樣要 union 的話,不是 error 也要放進 list 裡,就是 list 本人要包一個醜醜的 object type QQ
lucien
2020-07-13 16:42:11
取決於你的 batch 操作是全有全無還是可以部分錯誤部分成功吧
lucien
2020-07-13 16:43:21
喔喔以 search result 的語意上包一層 object type 是合理的,這是 gql 的必要之惡
mrorz
2020-07-13 16:46:30
嗯嗯通常是全有全無~
我剛才想了一下,如果不用 union type,那 return type 最後還是會寫成
```type ReturnType {
data: [Data],
error: Error
}```
所以其實還是會多一個 field “data” ,跟 union type 多包一層差不多意思;但若用了 union type,error 就不用多一層 `error` field XD
我剛才想了一下,如果不用 union type,那 return type 最後還是會寫成
```type ReturnType {
data: [Data],
error: Error
}```
所以其實還是會多一個 field “data” ,跟 union type 多包一層差不多意思;但若用了 union type,error 就不用多一層 `error` field XD
lucien
2020-07-13 16:46:57
我的 case 有部分成功的,這樣的設計就很方面
lucien
2020-07-13 16:47:05
[<XXX>Result]
lucien
2020-07-13 16:47:26
你可以在同樣的結構裡呈現成功與失敗的結果與原因
lucien
2020-07-13 16:50:51
不過 union 的代價是 client operation 會有點囉唆
mrorz
2020-07-13 17:12:26
自由就是囉唆 XD
client 可以不接沒興趣的 type 呀~
client 可以不接沒興趣的 type 呀~
lucien
2020-07-13 17:39:00
> 但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
我的用意是,不想讓原作者修改自己的意見會被 Blocked ,目標是他可以改自己以及自己引用自己的結果,但其他已被引用的回覆,與原文隔離開,不受影響原作者修改影響
我的用意是,不想讓原作者修改自己的意見會被 Blocked ,目標是他可以改自己以及自己引用自己的結果,但其他已被引用的回覆,與原文隔離開,不受影響原作者修改影響
mrorz
2020-07-13 18:12:07
聽起來滿酷的
我想想看
我想想看
zoe
18:15:40
@ggm, yo, I have some questions regarding chat bot GA logging
mrorz
18:17:06
這邊有 chatbot GA 事件總表~
https://github.com/cofacts/rumors-line-bot#google-analytics-events-table
https://github.com/cofacts/rumors-line-bot#google-analytics-events-table
- 🎉1
zoe
18:17:11
I don't think event label is logging the article/reply id as specified in the spec ( https://g0v.hackmd.io/0kjaVlFASSyddkltqGR6Nw under line inquiry)
mrorz
18:18:46
chatbot usage 要被 visualize 的是 production line bot 下的 All Web Site Data 的「User chooses a found article」的 event,此 event 的 `Event category` / `Event action` / `Event label` 分別是`Article` / `Selected` / `<selected article id>`
zoe
18:18:53
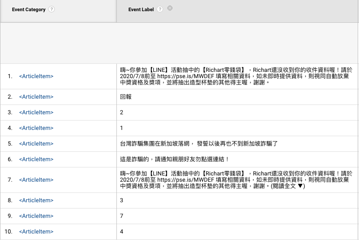
mrorz
2020-07-11 18:19:31
這個是 website 的 view 吧
mrorz
2020-07-11 18:21:40
chatbot 是 “production line bot” (staging 是 “staging line bot”) 這個 property 下面的 view 唷
ohhh, got it
thanks
mrorz
18:19:31
這個是 website 的 view 吧
mrorz
18:21:40
chatbot 是 “production line bot” (staging 是 “staging line bot”) 這個 property 下面的 view 唷
zoe
18:24:24
ohhh, got it
zoe
18:26:23
thanks
mrorz
18:26:36
5k4ek7
github
18:58:47
*As-is* *Desktop* *Reply to this message* Expands an empty section <https://user-images.githubusercontent.com/108608/87222646-0a1fce00-c3a8-11ea-893d-e4d53abb1d11.gif|Jul-11-2020 18-54-42> *Comment section* Allows user to input long comments, but block on submission <https://user-images.githubusercontent.com/108608/87222771-4d2e7100-c3a9-11ea-8c49-14663aa03f00.gif|comment-click> *Mobile* Block the user from doing anything...... <https://user-images.githubusercontent.com/108608/87222669-36d3e580-c3a8-11ea-981f-c315f72f2cc6.gif|mobile> *To-be* <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO?node-id=2011:0#30609561|Designers said>: <https://user-images.githubusercontent.com/108608/87222711-ba8dd200-c3a8-11ea-9713-49e4e1f5874a.png|image> Let's keep the buttons clickable, but add an `alert()` asking the user to login immediately after it's clicked. (Popping up login screen can be even better, but it's a bit more difficult to achieve.)
github
19:08:10
According to <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=1302%3A18|spec> <https://camo.githubusercontent.com/f716a22c8201eb9412adee1cf38a27f0654bc3fc/68747470733a2f2f73332d61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f6730762d6861636b6d642d696d616765732f75706c6f6164732f75706c6f61645f64613931626237623562396232656630356236636364653461356138626532372e706e67|Reference red dot> Please add a <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=1302%3A18|Material UI Dot Badge> on the "Reference" tab when the user did not enter reference yet.
github
20:05:27
See recording <https://drive.google.com/file/d/1aET09JJ_AxgFkRUDLYqR2CV3L4AAkagB/view?usp=sharing|https://drive.google.com/file/d/1aET09JJ_AxgFkRUDLYqR2CV3L4AAkagB/view?usp=sharing> We should allow Android users to be able to scroll down to access full editing area
github
20:26:50
After iOS users finish input in top search bar, the search bar would disappear. Here is a simulation using Safari: <https://user-images.githubusercontent.com/108608/87223969-cf239780-c3b3-11ea-801a-95ac7359087c.gif|ios search> On real iOS devices, as long as soft keyboard is dismissed, the search bar disappears. Replacing the current on-blur mechanism with Material-UI <https://material-ui.com/components/click-away-listener/#click-away-listener|Click-away listener> should work.
github
20:45:13
*As-is* The search input in search page is only 1 line high <https://user-images.githubusercontent.com/108608/87224213-0004cc00-c3b6-11ea-9365-51316eeb015d.gif|search> *To-be* As <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=432%3A2727|in spec>, the search input should grow as input. <https://user-images.githubusercontent.com/108608/87224366-4575c900-c3b7-11ea-8255-57ca43ff249a.png|image> This should be achievable using Material UI's <https://material-ui.com/components/textarea-autosize/|Textarea autosize>.
github
20:47:24
See items in read text in: <https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.g885e62dcbb_0_75|https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.g885e62dcbb_0_75> Spec: <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=681%3A0|https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=681%3A0>
github
20:48:48
Should add icons & levels. See p1, p5 in <https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.p|https://docs.google.com/presentation/d/18VnEBMr9m-t81ppRwHcjbA1keltg-CIn7wUF9pu1oLo/edit#slide=id.p> Visual spec: <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=681%3A0|https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=681%3A0>
github
20:54:14
Clicking this button has no effect: <https://user-images.githubusercontent.com/108608/87224542-a18d1d00-c3b8-11ea-86dd-fb40784e3aba.png|截圖 2020-07-11 下午8 53 04> It should work the same as its desktop counterpart.
github
23:42:42
After clicking “Add this reply to my reply” on searched result in editor, the contents of the copied reply appears in text area, but references shows "undefined". <https://user-images.githubusercontent.com/108608/87227845-0acc5a80-c3d0-11ea-8348-213a6e2ac28d.png|image>
2020-07-12
lucien
00:19:44
我明天整理給你
mrorz
00:59:11
想提醒一下我在兩週前有針對網站的 global style 以及 `ArticlePageLayout` 的重構發 PR
https://github.com/cofacts/rumors-site/pulls
因為放得有點久,而且會卡到接下來的重構,所以如果大家沒異議的話我週三會議前就會全 merge 唷
https://github.com/cofacts/rumors-site/pulls
因為放得有點久,而且會卡到接下來的重構,所以如果大家沒異議的話我週三會議前就會全 merge 唷
mrorz
2020-07-12 15:47:17
這些 PR 的內容已經重新佈上 Staging 囉
https://dev.cofacts.org
Component storybook
https://dev.cofacts.org/storybook/index.html?path=/story/listpage-filters--filters-and-options
https://dev.cofacts.org
Component storybook
https://dev.cofacts.org/storybook/index.html?path=/story/listpage-filters--filters-and-options
mrorz
2020-07-15 13:25:00
放太久的兩個 PR 先 merge 了,目前上面的是一些比較 trivial 的整理與打包性質的東西,為第二階段 page list display 的 PR 鋪路(不然第二階段又會超大包)
github
01:14:04
A connector is no longer needed, the visualizations are connected to google cloud storage open data CSV files now. Closing.
github
01:16:34
Implement "Direction 2" in <https://g0v.hackmd.io/ZcoUOX_-RQSkJyl5xz4_Zg#%E6%96%B9%E5%90%91-2-%E9%87%9D%E5%B0%8D%E6%AF%8F%E5%80%8B-backend-user-%E9%83%BD%E7%94%A2%E7%94%9F%E4%B8%80%E5%80%8B-user-document|userId & appId management proposal>. ☐ <https://github.com/cofacts/rumors-db/tree/create-user|Migration script> • adds user for backend app articles, reply-requests & article-reply feedbacks ☐ API change • organize auth & login routes • create user when resolving user
github
01:22:38
*Related bugs* • Search page 應該 sort by relevance • Replied by me filter 目前是壞的 • Latest reply 頁面卻有沒回應過的訊息 *目標* • 不同頁面使用不同 filter • 不同頁面使用不同 sort • 不同頁面顯示不同 UI、載入不同資料 *進行* ArticlePageLayout (可疑訊息、最新查核、等你來答、搜尋頁面) 的 refactor 預計會這樣進行: <https://g0v.hackmd.io/h8rP0TOGTh2Clxi_Oi_QKw|https://g0v.hackmd.io/h8rP0TOGTh2Clxi_Oi_QKw> 1. 會影響列表的 controls (如 filter, search, more button) 直接對 URL param 讀寫。單純化的 component input / output 有利於在各個 page components 重用。 2. page components 管理 data loading,讀取 URL param 之後拼湊成 graphql query。各頁面有特殊 Query 需求,也是在這個階段對 graphql query 加蔥。 3. 將會分 3 個 pull request 進 code *進度* ☐ Packaging input components • <https://github.com/cofacts/rumors-site/pull/267|#267> , <https://github.com/cofacts/rumors-site/pull/268|#268> ☐ Packaging display components: Header, layouts, list items 抽成 component,檢視其 props 設計 ☐ Extract logic to page
ggm
11:38:42
推哩 也 rebase 哩
ggm
11:42:52
我還是有保留 `UserSettings.create` 和 `UserArticleLink.create` 他們在 test 裡面都還有被用到,也不能被 createOrUpdate 取代
mrorz
15:47:17
Replied to a thread: 2020-07-12 00:59:11
這些 PR 的內容已經重新佈上 Staging 囉
https://dev.cofacts.org
Component storybook
https://dev.cofacts.org/storybook/index.html?path=/story/listpage-filters--filters-and-options
https://dev.cofacts.org
Component storybook
https://dev.cofacts.org/storybook/index.html?path=/story/listpage-filters--filters-and-options
dev.cofacts.org
Cofacts is a collaborative system connecting instant messages and fact-check reports or different opinions together. It’s a grass-root effort fighting mis/disinformation in Taiwan.
- 👍1
lucien
20:19:26
Replied to a thread: 2020-07-11 18:10:41
1. 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
- 👍1
lucien
20:27:15
Replied to a thread: 2020-07-11 18:10:41
2. 我自己現在的 Graphql mutation 結果設計是用前 medium 的設計延伸的,所有的操作不是權限跟 input 格式問題的話,都統一回傳 <Mutation>Result 。 Result 是 錯誤 Type 跟 成功結果的 union。
```Type Reply {...}
interface UserError {
message: String!
}
Type IsBlockedError extend UserError {
message: String!
// other props you want to show
}
union UpdateReplyResult = Reply | IsBlockedError
Mutation {
updateReply(input: UpdateReplyInput!): UpdateReplyResult!
}```
```Type Reply {...}
interface UserError {
message: String!
}
Type IsBlockedError extend UserError {
message: String!
// other props you want to show
}
union UpdateReplyResult = Reply | IsBlockedError
Mutation {
updateReply(input: UpdateReplyInput!): UpdateReplyResult!
}```
Medium
We all know how great GraphQL is when things go well, but what happens when things don’t go well?
- 👍2
github
22:15:33
`makeStyle`'s serial number in classnames often cause storyshots to change as we write new stories, resulting in irrelevant code changes in pull requests. This PR removes the serial number from snapshots so that the snapshots can be more independent from each other.
2020-07-13
mrorz
00:30:32
> 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面兩個 issue:
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面兩個 issue:
mrorz
00:35:07
Replied to a thread: 2020-07-11 18:10:41
> 放寬修改的限制我覺得很棒,但如果思考一下,如果改成,被引用的瞬間, duplicate 一份所有被引用的回應,讓所有引用都是對應到一個副本,是不是可以解決這個問題。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面 issue:
1. 我自己的使用習慣是會蒐集 N 個類似訊息、寫一個回應,然後通通連結到同一個回應。如果我發現原始回應有錯字想改、或是想到更好的寫法或出處,我就要改 N 次。
2. duplicate 之後再進行修改,此 articleReply 的 id 仍然保留原本 reply,但 reply text 可能已經不同。在 text 不一樣的狀況下,我們還能說這個 reply id 有連結到此 article 嗎?
3. 承 2,目前「加入現有回應」搜尋結果,其實會過濾掉已經被加過的回應。如果現在某人加了回應 `R` 並且修改內容為 `R'`(但仍然使用 `R` 的 ID)。之後,另外一個編輯看到了,覺得應該要用 `R` 比較好,但他搜尋時就會很納悶怎麼沒有 `R` 。
這樣確實可以解決 article reply feedback 對應到 reply 文字的問題
但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
如果是這樣的話,我想到會有下面 issue:
1. 我自己的使用習慣是會蒐集 N 個類似訊息、寫一個回應,然後通通連結到同一個回應。如果我發現原始回應有錯字想改、或是想到更好的寫法或出處,我就要改 N 次。
2. duplicate 之後再進行修改,此 articleReply 的 id 仍然保留原本 reply,但 reply text 可能已經不同。在 text 不一樣的狀況下,我們還能說這個 reply id 有連結到此 article 嗎?
3. 承 2,目前「加入現有回應」搜尋結果,其實會過濾掉已經被加過的回應。如果現在某人加了回應 `R` 並且修改內容為 `R'`(但仍然使用 `R` 的 ID)。之後,另外一個編輯看到了,覺得應該要用 `R` 比較好,但他搜尋時就會很納悶怎麼沒有 `R` 。
mrorz
00:44:00
Replied to a thread: 2020-07-11 18:10:41
把 success 的結果跟 error 的結構 union 起來很酷!感謝分享。
感覺這除了用在 `UpdateReply` 的結果之外,似乎還可以用在 `Reply` 回傳「此使用者是否可以更新這個 reply」的結果——此欄位可以回傳 `boolean | Error1 | Error 2 | Error3` 之類的東西
感覺這除了用在 `UpdateReply` 的結果之外,似乎還可以用在 `Reply` 回傳「此使用者是否可以更新這個 reply」的結果——此欄位可以回傳 `boolean | Error1 | Error 2 | Error3` 之類的東西
- 👍1
- 🙌1
github
01:39:12
This is about cleaning up and pave way to the ArticlePageLayout refactor PR (<https://github.com/cofacts/rumors-site/pull/288|#288> ) TBD
github
02:46:09
These are minor improvements made during implementation of main refactor <https://github.com/cofacts/rumors-site/pull/288|#288> ; isolated as a new PR to make the main PR clean. *Features* • Extract `<Tooltip>` from `ArticleInfo`'s `CustomTooltip` • Fine-tune style so that font size, margin and padding matches <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=436%3A441|the mockup> • Replaces all Material-UI `Tooltip` usage to the customized version *Refactors* • Updated `<ExpandableText>` to support background color other than white • This will be required when we implement `ArticleItem`'s "visited" state • Reads new CSS variable `--background` • Use `mask-image` to implement gradient background (because we cannot turn `var(--background)` transparent and put it in as a color stop in color gradient directly) • Add ellipsis in `wordCount` mode • Adjust button style
github
13:34:04
• nit: we can add `s` to function name (`findByUserIds`) to align with `UserArticleLink.findByArticleIds`
github
13:34:04
Looks in a good shape! I have some trivial comments here, but in general we are good to go!
github
13:34:12
If this is for dev only, how about we use `babel-node` to run `src/scripts/scanRepliesAndNotify` instead of building the entire project?
github
14:41:54
• Left: Current production website. When "show more" is clicked, many feedback are not shown. • Right: Old cofacts website, displaying all feedbacks (old websites don't differentiate upvote / downvote, though). <https://user-images.githubusercontent.com/108608/87278239-8d5f3200-c516-11ea-8988-f2f6d4faa556.png|image> API can correctly return all feedbacks, so it's UI issue. <https://user-images.githubusercontent.com/108608/87278400-f3e45000-c516-11ea-8275-3c17c4992b39.png|image> Bug found during <https://g0v.hackmd.io/ehzopA3fScSn9PjkBM79bA#%E6%9C%AA%E7%AB%9F%E9%A0%85%E7%9B%AE|20200708 release check>.
mrorz
2020-07-13 14:45:41
這些 feedback 寫「沒有」兩個字的,都是覺得回應有用的。
看來是因為我們在使用者回報一個回應有用時,會這樣問使用者:
> 已經記下您的評價。很開心這則回應有幫助到您。
> 針對這則回應,有沒有想補充的呢?
這個提問導致使用者輸入「沒有」然後送出。但在 Cofacts 網站上,就會看到有一堆人 upvote 然後又表示「沒有」,有點沒頭沒尾。
這 copy 該怎麼改呢 🤔
看來是因為我們在使用者回報一個回應有用時,會這樣問使用者:
> 已經記下您的評價。很開心這則回應有幫助到您。
> 針對這則回應,有沒有想補充的呢?
這個提問導致使用者輸入「沒有」然後送出。但在 Cofacts 網站上,就會看到有一堆人 upvote 然後又表示「沒有」,有點沒頭沒尾。
這 copy 該怎麼改呢 🤔
mrorz
2020-07-13 14:56:14
「想補充回應、或有要對編輯說的話的話,可以在下面留言唷!」這樣嗎
lucien
2020-07-13 17:35:29
但我覺得還是要把一些常見字詞濾掉
mrorz
2020-07-13 18:12:58
但我想要保留大家說謝謝
鼓勵編輯 XD
鼓勵編輯 XD
Stimim
2020-07-13 19:38:50
可以用 place holder 寫「沒有其他意見」之類的,這樣使用者應該會直接按送出?
mrorz
2020-07-13 23:22:44
喔喔這也是聰明的一手
mrorz
14:45:41
Replied to a thread: 2020-07-13 14:41:54
這些 feedback 寫「沒有」兩個字的,都是覺得回應有用的。
看來是因為我們在使用者回報一個回應有用時,會這樣問使用者:
> 已經記下您的評價。很開心這則回應有幫助到您。
> 針對這則回應,有沒有想補充的呢?
這個提問導致使用者輸入「沒有」然後送出。但在 Cofacts 網站上,就會看到有一堆人 upvote 然後又表示「沒有」,有點沒頭沒尾。
這 copy 該怎麼改呢 🤔
看來是因為我們在使用者回報一個回應有用時,會這樣問使用者:
> 已經記下您的評價。很開心這則回應有幫助到您。
> 針對這則回應,有沒有想補充的呢?
這個提問導致使用者輸入「沒有」然後送出。但在 Cofacts 網站上,就會看到有一堆人 upvote 然後又表示「沒有」,有點沒頭沒尾。
這 copy 該怎麼改呢 🤔

mrorz
14:56:14
「想補充回應、或有要對編輯說的話的話,可以在下面留言唷!」這樣嗎
mrorz
16:26:56
想問 @lucien 有沒有遇到某個 field return type 是個 list,但又想要幫他加個 error type 的狀況。
因為 GraphQL union 只支援 named object type,這樣要 union 的話,不是 error 也要放進 list 裡,就是 list 本人要包一個醜醜的 object type QQ
因為 GraphQL union 只支援 named object type,這樣要 union 的話,不是 error 也要放進 list 裡,就是 list 本人要包一個醜醜的 object type QQ
lucien
16:42:11
取決於你的 batch 操作是全有全無還是可以部分錯誤部分成功吧
lucien
16:43:21
喔喔以 search result 的語意上包一層 object type 是合理的,這是 gql 的必要之惡
mrorz
16:46:30
嗯嗯通常是全有全無~
我剛才想了一下,如果不用 union type,那 return type 最後還是會寫成
```type ReturnType {
data: [Data],
error: Error
}```
所以其實還是會多一個 field “data” ,跟 union type 多包一層差不多意思;但若用了 union type,error 就不用多一層 `error` field XD
我剛才想了一下,如果不用 union type,那 return type 最後還是會寫成
```type ReturnType {
data: [Data],
error: Error
}```
所以其實還是會多一個 field “data” ,跟 union type 多包一層差不多意思;但若用了 union type,error 就不用多一層 `error` field XD
lucien
16:46:57
我的 case 有部分成功的,這樣的設計就很方面
lucien
16:47:05
[<XXX>Result]
lucien
16:47:26
你可以在同樣的結構裡呈現成功與失敗的結果與原因
lucien
16:50:51
不過 union 的代價是 client operation 會有點囉唆
mrorz
17:12:26
自由就是囉唆 XD
client 可以不接沒興趣的 type 呀~
client 可以不接沒興趣的 type 呀~
lucien
17:35:29
但我覺得還是要把一些常見字詞濾掉
lucien
17:39:00
> 但這也代表修改回應文字時,只會修改在一個 article reply 上這樣嗎?
我的用意是,不想讓原作者修改自己的意見會被 Blocked ,目標是他可以改自己以及自己引用自己的結果,但其他已被引用的回覆,與原文隔離開,不受影響原作者修改影響
我的用意是,不想讓原作者修改自己的意見會被 Blocked ,目標是他可以改自己以及自己引用自己的結果,但其他已被引用的回覆,與原文隔離開,不受影響原作者修改影響
mrorz
18:12:07
聽起來滿酷的
我想想看
我想想看
mrorz
18:12:58
但我想要保留大家說謝謝
鼓勵編輯 XD
鼓勵編輯 XD
Stimim
19:38:50
可以用 place holder 寫「沒有其他意見」之類的,這樣使用者應該會直接按送出?
mrorz
23:22:44
喔喔這也是聰明的一手
2020-07-14
stbb1025
11:30:50
Filter中間的灰線如果改跟背景一樣看起來會變成三個區塊
stbb1025
11:58:03
https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=994%3A111
最新版的 landing page 出來囉,我把絕大多數的藍色省去,讓整個畫面的色系更單純。除此之外,所有線條都有重新順過,降低草稿感。上次提到的 icon 表情等等也都有做調整了。
另外我現在把整個頁面切成兩個大區塊(黃背景 & 紅背景),分別代表平台介紹及人才招募兩大主題。
再請大家過目,這頁確認後我這邊就可以進行後續的成就 & mobile Landing page 設計了。
@lucien @mrorz @bil
最新版的 landing page 出來囉,我把絕大多數的藍色省去,讓整個畫面的色系更單純。除此之外,所有線條都有重新順過,降低草稿感。上次提到的 icon 表情等等也都有做調整了。
另外我現在把整個頁面切成兩個大區塊(黃背景 & 紅背景),分別代表平台介紹及人才招募兩大主題。
再請大家過目,這頁確認後我這邊就可以進行後續的成就 & mobile Landing page 設計了。
@lucien @mrorz @bil
mrorz
2020-07-14 13:22:20
喜歡最右邊那版的背景顏色配置 ❤️
mrorz
2020-07-15 20:40:45
我跟 @bil @acerxp511 都覺得最新版本 OK 唷~
(今天 @lucien )
(今天 @lucien )
stbb1025
2020-07-15 20:46:34
好唷,那我可以進行成就和mobile的話請跟我說~感恩
lucien
2020-07-15 21:31:25
我要過去惹
stbb1025
2020-07-15 21:32:26
我在板橋XD 需要線上討論麻煩跟我說一下唷
stbb1025
12:00:29
https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=2011%3A0
404 頁面的部份這邊也再做了四個版本,最後一個提案的線條也有再重繪過,我認為改灰階是個不錯的選擇~應該可以更融入?
@lucien @mrorz @bil
404 頁面的部份這邊也再做了四個版本,最後一個提案的線條也有再重繪過,我認為改灰階是個不錯的選擇~應該可以更融入?
@lucien @mrorz @bil
- 🐳1
mrorz
2020-07-14 13:19:27
最後一個的線條變細我覺得很不錯~
不過瀏海剪掉有點看不出是手機角色 XD
不過瀏海剪掉有點看不出是手機角色 XD
stbb1025
2020-07-14 17:57:14
好,瀏海可以加回來😂
mrorz
2020-07-15 20:46:59
這個部分大家意見比較分歧
三個人各自喜歡了一個
共識是先把第二個排除 XDDD
三個人各自喜歡了一個
共識是先把第二個排除 XDDD
stbb1025
2020-07-15 20:48:27
好XD 再麻煩幫我統整一下XD
mrorz
13:02:13
我自己在寫 Cofacts 回應的時候,有掌握到一些讓回應比較好讀好入口的小技巧,整理在這裡(草稿):
https://hackmd.io/@cofacts/S1XQu2c1D
大家可以把看到覺得寫得很好的 Cofacts 回應提供給我唷,這份文件的每一個 tip 都需要案例 QQ
也說不定可以從案例中歸納出新的技巧。
目前 hackfoldr 裡面,針對編輯的有 UI 操作說明,或者是涵蓋比較全面(從分析到撰寫)的奇幻旅程。此份文件聚焦在寫作技巧,希望讓編輯有不同的靈感。
https://hackmd.io/@cofacts/S1XQu2c1D
大家可以把看到覺得寫得很好的 Cofacts 回應提供給我唷,這份文件的每一個 tip 都需要案例 QQ
也說不定可以從案例中歸納出新的技巧。
目前 hackfoldr 裡面,針對編輯的有 UI 操作說明,或者是涵蓋比較全面(從分析到撰寫)的奇幻旅程。此份文件聚焦在寫作技巧,希望讓編輯有不同的靈感。
HackMD
# 撰寫回應小撇步 :::danger - 狀態:草稿 - 撰寫要點 - 分不同 reply type,提供不同 tip 與範例 - 每個 tip 在兩段內,每段 100 字內 -
- 👄1
 1
1
mrorz
13:19:27
最後一個的線條變細我覺得很不錯~
不過瀏海剪掉有點看不出是手機角色 XD
不過瀏海剪掉有點看不出是手機角色 XD
mrorz
13:22:20
喜歡最右邊那版的背景顏色配置 ❤️
stbb1025
17:57:14
好,瀏海可以加回來😂
2020-07-15
mrorz
02:48:01
mrorz
2020-07-15 14:34:12
議程整理完畢,請大家過目
每週都有很多東西要討論 (抹臉
每週都有很多東西要討論 (抹臉
mrorz
12:46:23
@ggm @gary96302000.eecs96 @darkbtf
承上週會議對新 category 的討論
請問過去的 category 有沒有相關的文件在釐清各個 category 之間的差異呢?
如果大松要準備開放讓大家體驗標記 category,那我們要在大松之前把這些文件資料備齊呢
承上週會議對新 category 的討論
請問過去的 category 有沒有相關的文件在釐清各個 category 之間的差異呢?
如果大松要準備開放讓大家體驗標記 category,那我們要在大松之前把這些文件資料備齊呢
gary96302000.eecs96
2020-07-15 13:01:54
歐歐 這部分資訊我不知道耶 看看 ggm和蝴蝶有沒有決定了 不然晚上我們開會可以討論一下
darkbtf
2020-07-15 14:40:12
應該可以用若水那份改改看嗎
mrorz
2020-07-15 14:42:23
好哇那份有公開ㄇ
@mrorz 還沒公開耶,在我們的 google drive 裡面你搜搜看若水
請問過去的 category 有沒有相關的文件在釐清各個 category 之間的差異呢?這是意思啊?
阿我懂了
你是要說大家來標記的話有什麼準則嗎?
有的有一份流程圖,我找找
晚上討論好了
gary96302000.eecs96
13:01:54
歐歐 這部分資訊我不知道耶 看看 ggm和蝴蝶有沒有決定了 不然晚上我們開會可以討論一下
mrorz
13:17:49
好ㄅ
mrorz
13:25:00
Replied to a thread: 2020-07-12 00:59:11
放太久的兩個 PR 先 merge 了,目前上面的是一些比較 trivial 的整理與打包性質的東西,為第二階段 page list display 的 PR 鋪路(不然第二階段又會超大包)
github
14:21:52
As discussed in <https://g0v-slack-archive.g0v.ronny.tw/index/channel/C2PPMRQGP/2020-07#ts-1594556835.293700|https://g0v-slack-archive.g0v.ronny.tw/index/channel/C2PPMRQGP/2020-07#ts-1594556835.293700> The return type of the API can leverage union type, <https://medium.com/@sachee/200-ok-error-handling-in-graphql-7ec869aec9bc|as Medium suggested>.
darkbtf
14:40:12
應該可以用若水那份改改看嗎
mrorz
14:42:23
好哇那份有公開ㄇ
ggm
15:03:35
@mrorz 還沒公開耶,在我們的 google drive 裡面你搜搜看若水
ggm
15:03:56
請問過去的 category 有沒有相關的文件在釐清各個 category 之間的差異呢?這是意思啊?
ggm
15:04:06
阿我懂了
ggm
15:04:18
你是要說大家來標記的話有什麼準則嗎?
ggm
15:04:22
有的有一份流程圖,我找找
ggm
15:04:36
晚上討論好了
github
15:33:21
After testing, this error message only shows on iOS if user didn't allow `send messages to chat` permission but still try to trigger a button that will call `liff.sendMessages`. <https://user-images.githubusercontent.com/6376572/87516185-91728780-c6af-11ea-9c82-882818dc3017.png|https://user-images.githubusercontent.com/6376572/87516185-91728780-c6af-11ea-9c82-882818dc3017.png> Although Line will always ask for permission every time liff opening if user didn't grant, for better user experience, we should handle <https://developers.line.biz/en/reference/liff/#return-value-19|LiffError> returns from `liff.sendMessages`.
- 2
mrorz
20:40:45
我跟 @bil @acerxp511 都覺得最新版本 OK 唷~
(今天 @lucien )
(今天 @lucien )
stbb1025
20:46:34
好唷,那我可以進行成就和mobile的話請跟我說~感恩
mrorz
20:46:59
這個部分大家意見比較分歧
三個人各自喜歡了一個
共識是先把第二個排除 XDDD
三個人各自喜歡了一個
共識是先把第二個排除 XDDD
stbb1025
20:48:27
好XD 再麻煩幫我統整一下XD
github
21:10:38
As discussed in <https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E8%A8%8E%E8%AB%96%EF%BC%9A%E8%AE%93%E4%BD%9C%E8%80%85%E8%83%BD%E7%B7%A8%E8%BC%AF%E5%9B%9E%E6%87%89|https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E8%A8%8E%E8%AB%96%EF%BC%9A%E8%AE%93%E4%BD%9C%E8%80%85%E8%83%BD%E7%B7%A8%E8%BC%AF%E5%9B%9E%E6%87%89> the priority of this item is set to `low`.
lucien
21:31:25
我要過去惹
stbb1025
21:32:26
我在板橋XD 需要線上討論麻煩跟我說一下唷
2020-07-16
github
01:48:27
I have a bold idea. When we catch `liffError`, we can explain that we need "Send messages to chats" just because we want to send message back to Cofacts, then provide a button that reads "Go back and click 'send' by myself". The button is actually a link to a LINE URL scheme that <https://developers.line.biz/en/docs/line-login/using-line-url-scheme/#sending-text-messages|sends text to an official account>, in this case, `@cofacts`. One example to such link is: <https://line.me/R/oaMessage/@cofacts/?%F0%9F%91%8D%20%E9%80%99%E5%80%8B%E5%9B%9E%E6%87%89%E5%BE%88%E6%9C%89%E7%94%A8%EF%BC%8C%E6%88%91%E6%83%B3%E8%A3%9C%E5%85%85%3A%0Atest|https://line.me/R/oaMessage/@cofacts/?%F0%9F%91%8D%20%E9%80%99%E5%80%8B%E5%9B%9E%E6%87%89%E5%BE%88%E6%9C%89%E7%94%A8%EF%BC%8C%E6%88%91%E6%83%B3%E8%A3%9C%E5%85%85%3A%0Atest> Then we can put the text previously in `sendMessage()` into the URL scheme, so that when the user clicks the button, the URL scheme will bring them back to `@cofacts` chat screen, with message to send inside their text dialog. When the user clicks "send" button, the chatbot receives the message (prefixed with LIFF prefixes), and then proceed the steps.
github
06:01:43
Bumps <https://github.com/lodash/lodash|lodash> from 4.17.15 to 4.17.19. Release notes _Sourced from <https://github.com/lodash/lodash/releases|lodash's releases>._ > *4.17.16* Commits • <https://github.com/lodash/lodash/commit/d7fbc52ee0466a6d248f047b5d5c3e6d1e099056|`d7fbc52`> Bump to v4.17.19 • <https://github.com/lodash/lodash/commit/2e1c0f22f425e9c013815b2cd7c2ebd51f49a8d6|`2e1c0f2`> Add npm-package • <https://github.com/lodash/lodash/commit/1b6c282299f4e0271f932b466c67f0f822aa308e|`1b6c282`> Bump to v4.17.18 • <https://github.com/lodash/lodash/commit/a370ac81408de2da77a82b3c4b61a01a3b9c2fac|`a370ac8`> Bump to v4.17.17 • <https://github.com/lodash/lodash/commit/1144918f3578a84fcc4986da9b806e63a6175cbb|`1144918`> Rebuild lodash and docs • <https://github.com/lodash/lodash/commit/3a3b0fd339c2109563f7e8167dc95265ed82ef3e|`3a3b0fd`> Bump to v4.17.16 • <https://github.com/lodash/lodash/commit/c84fe82760fb2d3e03a63379b297a1cc1a2fce12|`c84fe82`> fix(zipObjectDeep): prototype pollution (<https://github-redirect.dependabot.com/lodash/lodash/issues/4759|#4759>) • <https://github.com/lodash/lodash/commit/e7b28ea6cb17b4ca021e7c9d66218c8c89782f32|`e7b28ea`> Sanitize sourceURL so it cannot affect evaled code (<https://github-redirect.dependabot.com/lodash/lodash/issues/4518|#4518>) • <https://github.com/lodash/lodash/commit/0cec225778d4ac26c2bac95031ecc92a94f08bbb|`0cec225`> Fix lodash.isEqual for circular references (<https://github-redirect.dependabot.com/lodash/lodash/issues/4320|#4320>) (<https://github-redirect.dependabot.com/lodash/lodash/issues/4515|#4515>) • <https://github.com/lodash/lodash/commit/94c3a8133cb4fcdb50db72b4fd14dd884b195cd5|`94c3a81`> Document matches* shorthands for over* methods (<https://github-redirect.dependabot.com/lodash/lodash/issues/4510|#4510>) (<https://github-redirect.dependabot.com/lodash/lodash/issues/4514|#4514>) • Additional commits viewable in <https://github.com/lodash/lodash/compare/4.17.15...4.17.19|compare view> Maintainer changes This version was pushed to npm by <https://www.npmjs.com/~mathias|mathias>, a new releaser for lodash since your current version. <https://help.github.com/articles/configuring-automated-security-fixes|Dependabot compatibility score> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. * * * Dependabot commands and options You can trigger Dependabot actions by commenting on this PR: • `@dependabot rebase` will rebase this PR • `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it • `@dependabot merge` will merge this PR after your CI passes on it • `@dependabot squash and merge` will squash and merge this PR after your CI passes on it • `@dependabot cancel merge` will cancel a previously requested merge and block automerging • `@dependabot reopen` will reopen this PR if it is closed • `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually • `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself) • `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language • `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language • `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language • `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language You can disable automated security fix PRs for this repo from the <https://github.com/cofacts/rumors-site/network/alerts|Security Alerts page>.
mrorz
2020-07-16 12:46:40
我們沒裝 depandabot 呀 .__. 為什麼他會叫
tw0517tw
2020-07-16 13:19:17
被買走了之後過了一陣子變成預設開啟幫忙檢查安全問題的樣子
mrorz
2020-07-16 13:19:48
原來是自動的 ._.
但我們已經有 renovate 了
現在兩個 bot 都各開一個 PR 叫我升級 XD
但我們已經有 renovate 了
現在兩個 bot 都各開一個 PR 叫我升級 XD
github
06:46:23
This PR contains the following updates: *GitHub Vulnerability Alerts* *<https://www.npmjs.com/advisories/1523|GHSA-p6mc-m468-83gw>* Versions of lodash prior to 4.17.19 are vulnerable to Prototype Pollution. The function zipObjectDeep allows a malicious user to modify the prototype of Object if the property identifiers are user-supplied. Being affected by this issue requires zipping objects based on user-provided property arrays. This vulnerability causes the addition or modification of an existing property that will exist on all objects and may lead to Denial of Service or Code Execution under specific circumstances. * * * *Release Notes* lodash/lodash *<https://togithub.com/lodash/lodash/compare/4.17.15...4.17.16|`v4.17.16`>* <https://togithub.com/lodash/lodash/compare/4.17.15...4.17.16|Compare Source> * * * *Renovate configuration* :date: *Schedule*: "" (UTC). :vertical_traffic_light: *Automerge*: Disabled by config. Please merge this manually once you are satisfied. :recycle: *Rebasing*: Whenever PR becomes conflicted, or you tick the rebase/retry checkbox. :no_bell: *Ignore*: Close this PR and you won't be reminded about this update again. * * * ☐ If you want to rebase/retry this PR, check this box * * * This PR has been generated by <https://renovate.whitesourcesoftware.com|WhiteSource Renovate>. View repository job log <https://app.renovatebot.com/dashboard#cofacts/rumors-site|here>.
tw0517tw
13:19:17
被買走了之後過了一陣子變成預設開啟幫忙檢查安全問題的樣子
mrorz
13:19:48
原來是自動的 ._.
但我們已經有 renovate 了
現在兩個 bot 都各開一個 PR 叫我升級 XD
但我們已經有 renovate 了
現在兩個 bot 都各開一個 PR 叫我升級 XD
mrorz
13:22:22
延續昨天開會時討論的,Google analytics 因為 fbclid 那些 query param 導致統計分散的問題
我試著撈出 URL 裡面被加料的那些 page view 放在這裡:
https://docs.google.com/spreadsheets/d/1_KjmSLc1uwKDZPV_wG7tynN_alR_9r-GhqPbq1ViJ5k/edit#gid=1298620982
除了最大宗的 `fbclid` (Facebook) 之外,赫然發現有微信的 `?from=singlemessage` 或 `?from=timeline&from=singlemessage`
所以有人把 Cofacts 連結貼去微信讓人點開,或是放在自己的 timeline 上耶
有點酷
我試著撈出 URL 裡面被加料的那些 page view 放在這裡:
https://docs.google.com/spreadsheets/d/1_KjmSLc1uwKDZPV_wG7tynN_alR_9r-GhqPbq1ViJ5k/edit#gid=1298620982
除了最大宗的 `fbclid` (Facebook) 之外,赫然發現有微信的 `?from=singlemessage` 或 `?from=timeline&from=singlemessage`
所以有人把 Cofacts 連結貼去微信讓人點開,或是放在自己的 timeline 上耶
有點酷
github
13:54:53
mrorz
2020-07-16 13:55:21
@acerxp511 可以 rebase 你的 PR 囉~
mrorz
2020-07-16 13:56:33
@ggm 請問這個 ready for review 了嗎
https://github.com/cofacts/rumors-line-bot/pull/204/files
https://github.com/cofacts/rumors-line-bot/pull/204/files
阿還沒 我要 rebase 一下
mrorz
2020-07-16 14:03:14
好的麻煩惹 🙇♀️
mrorz
13:55:21
@acerxp511 可以 rebase 你的 PR 囉~
mrorz
13:56:33
@ggm 請問這個 ready for review 了嗎
https://github.com/cofacts/rumors-line-bot/pull/204/files
https://github.com/cofacts/rumors-line-bot/pull/204/files
ggm
13:57:28
阿還沒 我要 rebase 一下
mrorz
14:03:14
好的麻煩惹 🙇♀️
github
16:49:40
Bumps <https://github.com/lodash/lodash|lodash> from 4.17.10 to 4.17.19. Release notes _Sourced from <https://github.com/lodash/lodash/releases|lodash's releases>._ > *4.17.16* Commits • <https://github.com/lodash/lodash/commit/d7fbc52ee0466a6d248f047b5d5c3e6d1e099056|`d7fbc52`> Bump to v4.17.19 • <https://github.com/lodash/lodash/commit/2e1c0f22f425e9c013815b2cd7c2ebd51f49a8d6|`2e1c0f2`> Add npm-package • <https://github.com/lodash/lodash/commit/1b6c282299f4e0271f932b466c67f0f822aa308e|`1b6c282`> Bump to v4.17.18 • <https://github.com/lodash/lodash/commit/a370ac81408de2da77a82b3c4b61a01a3b9c2fac|`a370ac8`> Bump to v4.17.17 • <https://github.com/lodash/lodash/commit/1144918f3578a84fcc4986da9b806e63a6175cbb|`1144918`> Rebuild lodash and docs • <https://github.com/lodash/lodash/commit/3a3b0fd339c2109563f7e8167dc95265ed82ef3e|`3a3b0fd`> Bump to v4.17.16 • <https://github.com/lodash/lodash/commit/c84fe82760fb2d3e03a63379b297a1cc1a2fce12|`c84fe82`> fix(zipObjectDeep): prototype pollution (<https://github-redirect.dependabot.com/lodash/lodash/issues/4759|#4759>) • <https://github.com/lodash/lodash/commit/e7b28ea6cb17b4ca021e7c9d66218c8c89782f32|`e7b28ea`> Sanitize sourceURL so it cannot affect evaled code (<https://github-redirect.dependabot.com/lodash/lodash/issues/4518|#4518>) • <https://github.com/lodash/lodash/commit/0cec225778d4ac26c2bac95031ecc92a94f08bbb|`0cec225`> Fix lodash.isEqual for circular references (<https://github-redirect.dependabot.com/lodash/lodash/issues/4320|#4320>) (<https://github-redirect.dependabot.com/lodash/lodash/issues/4515|#4515>) • <https://github.com/lodash/lodash/commit/94c3a8133cb4fcdb50db72b4fd14dd884b195cd5|`94c3a81`> Document matches* shorthands for over* methods (<https://github-redirect.dependabot.com/lodash/lodash/issues/4510|#4510>) (<https://github-redirect.dependabot.com/lodash/lodash/issues/4514|#4514>) • Additional commits viewable in <https://github.com/lodash/lodash/compare/4.17.10...4.17.19|compare view> Maintainer changes This version was pushed to npm by <https://www.npmjs.com/~mathias|mathias>, a new releaser for lodash since your current version. <https://help.github.com/articles/configuring-automated-security-fixes|Dependabot compatibility score> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. * * * Dependabot commands and options You can trigger Dependabot actions by commenting on this PR: • `@dependabot rebase` will rebase this PR • `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it • `@dependabot merge` will merge this PR after your CI passes on it • `@dependabot squash and merge` will squash and merge this PR after your CI passes on it • `@dependabot cancel merge` will cancel a previously requested merge and block automerging • `@dependabot reopen` will reopen this PR if it is closed • `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually • `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself) • `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language • `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language • `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language • `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language You can disable automated security fix PRs for this repo from the <https://github.com/cofacts/rumors-fb-bot/network/alerts|Security Alerts page>.
mrorz
21:54:05
LIFF 再更新 https://www.facebook.com/groups/linebot/permalink/2561376310859606/
看起來要開個 Module mode 不然使用者會按到把 LIFF URL 分享出去的功能
看起來要開個 Module mode 不然使用者會按到把 LIFF URL 分享出去的功能
facebook.com
【LIFF Header 新功能】 於七月初提到的 LIFF Header 新功能今日已正式推出囉! 以下再次整理提供給大家更新內容: :point_right: 於原本頁面左上角 LINE Login chanel 的圖示將會隱藏 :point_right: 分享(Share)按鈕:按下後會分享、重整的選項(僅支援 LIFF Full size) - 分享:可將目前頁面透過 LINE Message 分享給其他用戶 -...
2020-07-17
mrorz
03:19:52
Emoji 選單很棒 <3
https://cofacts.org/article/3i3l9grtm802g
不過我連出處都想用 emoji,我現在是在回應視窗點出 emoji 之後在複製貼上下去 ._.
https://cofacts.org/article/3i3l9grtm802g
不過我連出處都想用 emoji,我現在是在回應視窗點出 emoji 之後在複製貼上下去 ._.
mrorz
2020-07-17 03:21:05
然後看來回應的 URL preview 可能也要折疊一下 ._.
mrorz
03:21:05
然後看來回應的 URL preview 可能也要折疊一下 ._.
mrorz
13:23:29
- 🦒2
- 🐳1

ky
15:23:28
喔喔喔喔喔喔
stbb1025
16:18:48
mrorz
2020-07-17 16:57:15
「曾經獲得過優秀回答者」(Good answer)是什麼呀
mrorz
2020-07-17 16:58:30
「回應 request」(個人總 reply Request)其實是這個人很會回報訊息給 Cofacts 的概念
(抓耙子?)
(抓耙子?)
lucien
2020-07-17 18:00:51
> 「曾經獲得過優秀回答者」(Good answer)是什麼呀
mrorz
2020-07-18 00:04:00
群眾票選嗎
感覺確實可以作為一種與編輯或使用者之間的的互動呢
感覺確實可以作為一種與編輯或使用者之間的的互動呢
stbb1025
16:19:48
Hi hi 這是成就的草稿,麻煩大家看看詮釋方式有沒有什麼問題,ok 的話我們就進行後續精稿跟上色唷,感恩~
@lucien @mrorz @bil @yanglin5689446
@lucien @mrorz @bil @yanglin5689446
 1
1
mrorz
2020-07-17 17:05:22
各種機器人很可愛~
感謝感謝,很可愛唷=D
mrorz
16:57:15
「曾經獲得過優秀回答者」(Good answer)是什麼呀
mrorz
16:58:30
「回應 request」(個人總 reply Request)其實是這個人很會回報訊息給 Cofacts 的概念
(抓耙子?)
(抓耙子?)
mrorz
17:05:22
各種機器人很可愛~
lucien
18:00:51
> 「曾經獲得過優秀回答者」(Good answer)是什麼呀
2020-07-18
mrorz
00:04:00
群眾票選嗎
感覺確實可以作為一種與編輯或使用者之間的的互動呢
感覺確實可以作為一種與編輯或使用者之間的的互動呢
bil
21:27:03
感謝感謝,很可愛唷=D
2020-07-19
github
11:30:27
It's not a bug. This case is `ASKING_REPLY_REQUEST_REASON` state that means the article was already submitted.
github
17:19:32
I see, in that case the trap options like "我在 LINE 外頭看到的" should be hidden from the LIFF. If we can ensure the trap options are hidden, we can close the issue.
github
18:03:48
*Pull Request Test Coverage Report for <https://coveralls.io/builds/32171890|Build 1040>* • *1* of *8* *(12.5%)* changed or added relevant lines in *1* file are covered. • No unchanged relevant lines lost coverage. • Overall coverage decreased (*-0.8%*) to *79.695%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
mrorz
19:52:08
為了作報告,我又在 analytics 增加了 reply 在 chatbot 中被指名要閱讀的次數
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/aBhYB
https://datastudio.google.com/u/0/reporting/18J8jZYumsoaCPBk9bdRd97GKvi_W5v-r/page/aBhYB
Google Data Studio
Google Data Studio turns your data into informative dashboards and reports that are easy to read, easy to share, and fully customizable.
- 1
mrorz
19:52:34
這樣可以看到在 Cofacts chatbot 被閱讀最多次的回應有哪些~
mrorz
21:16:29
補充功能被用來回應回應 ._.
https://cofacts.g0v.tw/article/1d0lu8giqz323
https://cofacts.g0v.tw/article/1d0lu8giqz323
2020-07-20
github
12:02:34
Fixes <https://github.com/cofacts/rumors-line-bot/issues/192|#192> It’s because default reply `context` object doesn’t have `data` property, when the next message comes in, getting `context.data.sessionId` will have such error.
github
12:05:52
*Pull Request Test Coverage Report for <https://coveralls.io/builds/32181129|Build 1044>* • *0* of *0* changed or added relevant lines in *0* files are covered. • No unchanged relevant lines lost coverage. • Overall coverage remained the same at *80.521%* * * * * * * *:yellow_heart: - <https://coveralls.io|Coveralls>*
github
13:25:51
<https://github.com/nonumpa|@nonumpa> Nice catch! Thanks for debugging. I think we can have an unit test that reproduces the case when default reply is used. Another thing is, it seems that I cannot reproduce the bug on LINE -- sending sticker message triggers the default reply, but sending further message does not crash the chatbot. May I know the correct steps to reproduce <https://github.com/cofacts/rumors-line-bot/issues/192|#192> ? In this way we can verify the bug is really fixed within the chatbot.
github
13:29:33
Oh, the next message should be a postback, only postback messages will get `context.data.sessionId`.
github
13:45:18
> Oh, the next message should be a postback, only postback messages will get context.data.sessionId. Thanks! So the reproduction step is clear now. 1. Send any text that shows a button (ex: `1234`) 2. Send a sticker and get "I cannot understand messages ..." 3. Click the previously shown button I think we can have a snapshot test for the default reply (probably using sticker message as mock input) and we are good to go.
github
13:51:13
LGTM! Just curious, <https://developers.line.biz/en/reference/liff/#liff-errors|the documentation> actually lists many LIFF error codes that is in strings. So only 403 is used in practice?
github
14:16:34
The document says that 403 is associated with authorization error. Actually I directly calls liff.sendMessages on desktop, the error message is not the same as the one on mobile (`user doesn't grant required permissions yet`). Since we've told user to use mobile version, dunno if we need also check the error message to match the condition precisely. Another thing is `LiffError` collects all errors together, I don't know which API will return `403`, which will return `UNAUTHORIZED`.
stbb1025
15:55:16
套上UI框架的樣子,接著大家確認後會上色跟線條精修。有任何問題請務必提出喔~感恩
@mrorz @lucien @bil @yanglin5689446
@mrorz @lucien @bil @yanglin5689446
- 🐳1
mrorz
2020-07-20 15:56:09
想問線條粗細也是精修的時候修嗎
好奇它放進整個 UI 頁面的時候會是什麼感覺
好奇它放進整個 UI 頁面的時候會是什麼感覺
stbb1025
2020-07-20 15:56:57
我可以請插畫家先做五個精稿
stbb1025
2020-07-20 15:57:09
擺上去看看 大家再來調整~
chihao
2020-07-20 18:52:32
哦哦哦哦哦哦(路過)
設計師很帥>w<
lucien
2020-07-22 20:07:14
這個風格方向可以參考 https://steamcommunity.com/stats/698870/achievements
粗獷風格做外匡、陰影跟效果線等細節,讓成就看起來誘人,希望最後成果粗中有細,感謝熊!
粗獷風格做外匡、陰影跟效果線等細節,讓成就看起來誘人,希望最後成果粗中有細,感謝熊!
lucien
2020-07-22 20:08:19
順帶一提這是知乎的
stbb1025
2020-07-22 21:11:07
感謝回覆~~我覺得第一個steam的樣式滿不錯的,我會請熊照這個走向先畫三到五個精稿,擺上來給大家看看
mrorz
2020-07-23 01:14:33
steam 的很讚
mrorz
15:56:09
想問線條粗細也是精修的時候修嗎
好奇它放進整個 UI 頁面的時候會是什麼感覺
好奇它放進整個 UI 頁面的時候會是什麼感覺
stbb1025
15:56:57
我可以請插畫家先做五個精稿
stbb1025
15:57:09
擺上去看看 大家再來調整~
chihao
18:52:32
哦哦哦哦哦哦(路過)
2020-07-21
github
13:02:30
Nit: when invoking `toMatchSnapshot` multiple times in one `it` test, we can pass in snapshot names to make snapshots easier to read.
github
13:02:49
LGTM! Thanks for the fix! Let's merge and see if <https://github.com/cofacts/rumors-line-bot/issues/192|#192> still happens.
github
13:12:03
1. What does `USER_ID` do? I may have missed where it is used. 2. Since the backtrack will only be run once, I think we can just put a comment to indicate how to run this function instead of putting it in package.json. In reality we may be executing the script using `heroku exec`.
github
13:53:43
Confirmed that the `LIFF` / `chooseArticle` event is working. Ready to review now. <https://user-images.githubusercontent.com/108608/88018062-87da9b00-cb59-11ea-993d-99db6f81f383.png|image>
mrorz
14:18:37
老 PR 求 review:
• 在 LIFF 加上 google analytics https://github.com/cofacts/rumors-line-bot/pull/206
• Trivial: 讓 snapshot 乾淨點 https://github.com/cofacts/rumors-site/pull/287
• component 大搬風,把 list page 的 control 與 display 分開 https://github.com/cofacts/rumors-site/pull/289
• 抽出 `Tooltip` component: https://github.com/cofacts/rumors-site/pull/290
如果週三沒人看的話我也會 merge 唷。
• 在 LIFF 加上 google analytics https://github.com/cofacts/rumors-line-bot/pull/206
• Trivial: 讓 snapshot 乾淨點 https://github.com/cofacts/rumors-site/pull/287
• component 大搬風,把 list page 的 control 與 display 分開 https://github.com/cofacts/rumors-site/pull/289
• 抽出 `Tooltip` component: https://github.com/cofacts/rumors-site/pull/290
如果週三沒人看的話我也會 merge 唷。
mrorz
14:30:32
mLab 要關啦啊啊啊 😱 🙀 @ggm
https://devcenter.heroku.com/changelog-items/1823
https://devcenter.heroku.com/changelog-items/1823
ggm
14:30:48
什麼!
mrorz
14:32:21
他們被 MongoDB 母公司買下來
所以 mLab 就不再提供 Heroku addon
要馬是直接用 MongoDB Atlas
要馬是用別人家
所以 mLab 就不再提供 Heroku addon
要馬是直接用 MongoDB Atlas
要馬是用別人家
mrorz
2020-07-21 14:33:29
至於 MongoDB Atlas 也有 free plan
但有 operation limit
100 operation per second
https://docs.atlas.mongodb.com/reference/free-shared-limitations/#operational-limitations
但有 operation limit
100 operation per second
https://docs.atlas.mongodb.com/reference/free-shared-limitations/#operational-limitations
其實還行?
mrorz
2020-07-21 17:55:23
我也覺得還好
如果要跑 backtrack
可能跑在 local 環境,再 mongodump 出來、再 mongoimport 進去?
如果要跑 backtrack
可能跑在 local 環境,再 mongodump 出來、再 mongoimport 進去?
mrorz
14:33:29
至於 MongoDB Atlas 也有 free plan
但有 operation limit
100 operation per second
https://docs.atlas.mongodb.com/reference/free-shared-limitations/#operational-limitations
但有 operation limit
100 operation per second
https://docs.atlas.mongodb.com/reference/free-shared-limitations/#operational-limitations
mrorz
14:36:50
本來想說 insert article merge 之後,明天開會來測新 chatbot 包含 viewed article 的功能
但如果要換資料庫,那還是下週再測 + 上線好了,今天來不及研究新資料庫服務 QQ
但如果要換資料庫,那還是下週再測 + 上線好了,今天來不及研究新資料庫服務 QQ
mrorz
2020-07-21 14:39:17
mLab free sandbox --> MongoDB Atlas M0 free quota 的搬家指南
https://docs.mlab.com/how-to-migrate-sandbox-heroku-addons-to-atlas/
https://docs.mlab.com/how-to-migrate-sandbox-heroku-addons-to-atlas/
mrorz
14:39:17
mLab free sandbox --> MongoDB Atlas M0 free quota 的搬家指南
https://docs.mlab.com/how-to-migrate-sandbox-heroku-addons-to-atlas/
https://docs.mlab.com/how-to-migrate-sandbox-heroku-addons-to-atlas/
github
14:57:08
Inputting this will break staging chatbot: ``` 📃 查看這篇的回應: <https://dev.cofacts.org/article/AV1vp0l4yCdS-nWhuc4e> ``` The error in console says: ``` { "message": "A message (messages[2]) in the request body is invalid", "details": [ { "message": "must be non-empty text", "property": "/contents/5/body/contents/0/text" }, { "message": "must be non-empty text", "property": "/contents/6/body/contents/0/text" }, { "message": "must be non-empty text", "property": "/contents/7/body/contents/0/text" } ] } ``` This is because there are some replies with empty text (probably caused by a previous bug.) The reply sending mechanism should prevent empty text from being sent as an option.
ggm
15:57:21
不對呀他是整個服務都不提供,還是只是不提供 addon 啊?
mrorz
2020-07-21 17:53:59
整個 mLab 都 subset,搬去 MongoDB Atlas
https://docs.mlab.com/mlab-to-atlas/
https://docs.mlab.com/mlab-to-atlas/
ggm
15:57:59
噢看起來是整個都要搬過去
ggm
16:03:37
其實還行?
mrorz
17:53:59
整個 mLab 都 subset,搬去 MongoDB Atlas
https://docs.mlab.com/mlab-to-atlas/
https://docs.mlab.com/mlab-to-atlas/
mrorz
17:54:18
賀出場
mrorz
17:55:23
我也覺得還好
如果要跑 backtrack
可能跑在 local 環境,再 mongodump 出來、再 mongoimport 進去?
如果要跑 backtrack
可能跑在 local 環境,再 mongodump 出來、再 mongoimport 進去?
kiang
21:14:13
不知道是不是快取造成,剛剛試著送一個連結給 linebot ,也收到回應說感謝提供資訊,但再次送出同樣連結一樣會提示要我再次送進資料庫
從前台網頁也看不到剛剛送出的連結,還是訊息要經過審核才會出現在通報的內容中?
從前台網頁也看不到剛剛送出的連結,還是訊息要經過審核才會出現在通報的內容中?
mrorz
2020-07-21 22:35:06
請問有互動的截圖嗎~?
mrorz
2020-07-22 12:35:27
在 LINE 外頭看到的訊息不會放進資料庫唷~
mrorz
2020-07-22 12:37:25
這是過去為了防止資料庫被塞入太多跟謠言無關的東西,所以做的過濾機制
不過幾週以前 @bil 覺得可以拿掉了
大家覺得如何呢
不過幾週以前 @bil 覺得可以拿掉了
大家覺得如何呢
我覺得可以拿掉了唷
kiang
2020-07-22 18:51:04
Line 以外的也許以連結為主?之前新聞小幫手是以網址為主就是了
lucien
2020-07-22 21:24:19
現在有 crawler 比對的話,我覺得可以拿掉
mrorz
2020-07-23 02:34:02
好的,我週末抓一下對話資料
算一下開放之後會多多少訊息進資料庫~
算一下開放之後會多多少訊息進資料庫~
mrorz
22:35:06
請問有互動的截圖嗎~?
kiang
22:41:51
github
23:48:04
1. Use in rumors-line-bot-log-parser to show userId, because we hide the userId by default <https://github.com/cofacts/rumors-line-bot-log-parser/blob/5446ec86976e4c55f24fd355fe595a45da5f31e2/index.js#L93|https://github.com/cofacts/rumors-line-bot-log-parser/blob/5446ec86976e4c55f24fd355fe595a45da5f31e2/index.js#L93> 2. okok
2020-07-22
mrorz
01:49:33
7/22 議程
https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2F9qp8dE7dReK2q8FTeP9Feg
明天中午會開上週提到的一些票
然後我會完成 category 標籤定義
針對週六大松也要稍微討論一下分工~
https://g0v.hackmd.io/@mrorz/cofacts-meeting-notes/%2F9qp8dE7dReK2q8FTeP9Feg
明天中午會開上週提到的一些票
然後我會完成 category 標籤定義
針對週六大松也要稍微討論一下分工~
mrorz
12:35:27
在 LINE 外頭看到的訊息不會放進資料庫唷~
mrorz
12:37:25
Replied to a thread: 2020-07-21 21:14:13
這是過去為了防止資料庫被塞入太多跟謠言無關的東西,所以做的過濾機制
不過幾週以前 @bil 覺得可以拿掉了
大家覺得如何呢
不過幾週以前 @bil 覺得可以拿掉了
大家覺得如何呢
github
13:05:47
From discussions in <https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E6%9C%AA%E7%AB%9F%E9%A0%85%E7%9B%AE|https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E6%9C%AA%E7%AB%9F%E9%A0%85%E7%9B%AE> even though we can support multi-line, "enter" should still trigger search instead of new lines
github
13:25:38
From: <https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E6%9C%AA%E7%AB%9F%E9%A0%85%E7%9B%AE|https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E6%9C%AA%E7%AB%9F%E9%A0%85%E7%9B%AE> *As-is* <https://user-images.githubusercontent.com/108608/88136711-70b0b180-cc1c-11ea-999b-7ec356b5dbae.png|image> • Clicking upvote / downvote shows reason dialog. • Upvote / downvote are sent along with its reason after clicking "Send". *To-be* • Upvote / downvote (without reason) is submitted as soon as the upvote / button button is clicked. • Clicking upvote / downvote still shows reason dialog, but with different prompt: "Thank you for the feedback." + "Do you have anything to add?" / "Why do you think it is not useful?" • "Send" --> "Close" when no content, "Send" when inputted something • After clicking "Send", the vote is submitted again, this time with reason.
github
13:35:41
*As-is* From <https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E5%9B%9E%E6%87%89%E3%80%8C%E6%B2%92%E6%9C%89%E3%80%8D%E7%9A%84%E6%AD%A3%E8%A9%95|https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w?both#%E5%9B%9E%E6%87%89%E3%80%8C%E6%B2%92%E6%9C%89%E3%80%8D%E7%9A%84%E6%AD%A3%E8%A9%95> > 看來是因為我們在使用者回報一個回應有用時,會這樣問使用者: > <https://camo.githubusercontent.com/a18cb9ea3680766154d5b90b67e931aa80460493/68747470733a2f2f73332d61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f6730762d6861636b6d642d696d616765732f75706c6f6164732f75706c6f61645f32613165663531623633356238343966393664663836376533646462383364362e706e67|https://camo.githubusercontent.com/a18cb9ea3680766154d5b90b67e931aa80460493/68747470733a2f2f73332d61702d6e6f727468656173742d312e616d617a6f6e6177732e636f6d2f6730762d6861636b6d642d696d616765732f75706c6f6164732f75706c6f61645f32613165663531623633356238343966393664663836376533646462383364362e706e67> > 這個提問導致使用者輸入「沒有」然後送出。但在 Cofacts 網站上,就會看到有一堆人 upvote 然後又表示「沒有」,有點沒頭沒尾。 > <https://user-images.githubusercontent.com/108608/88138295-f5e99580-cc1f-11ea-9eb9-9aa435699fbf.png|image> > [name=MrOrz] > > 可以用 place holder 寫「沒有其他意見」之類的,這樣使用者應該會直接按送出? > [name=stimim] *To-be* Change the wording so that: • The dialog still asks "Do you have anything to add" • Change the placeholder of text area to "Nothing to add". • If the dialog is empty, change text of the button to "Close"; reads "Submit" only after textarea has content
github
13:49:22
*As-is* <https://user-images.githubusercontent.com/108608/88139136-adcb7280-cc21-11ea-8649-eafd0b04d3e1.png|image> • 搜尋框很不明顯 • 搜尋結果無法拉大,列表呈現在很小的地方 • 搜尋的當下沒有 loading state • Enter 搜尋不直觀,而且 iOS 上 enter 會顯示「換行」 • 有時候其實只是想看一看搜尋結果,按搜尋旁邊的 X 關掉實在太不直觀 • iOS 上點按「Add this reply to my reply」會直接送出回應! *To-be* Figma: <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=908%3A91|https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=908%3A91> <https://user-images.githubusercontent.com/108608/88139207-cdfb3180-cc21-11ea-94f4-1d34a501ee7e.png|image> • 搜尋框加上「參考過往回應」的 placeholder • 使理由與來源的 input 能垂直拉大(水平方向則固定) • 搜尋時加上 loading indicator • 修正 iOS 點按「Add this reply to my reply」送出的問題
mrorz
2020-07-22 13:50:18
關於這張票下面這兩個 user feedback:
• Enter 搜尋不直觀,而且 iOS 上 enter 會顯示「換行」
• 有時候其實只是想看一看搜尋結果,按搜尋旁邊的 X 關掉實在太不直觀
在互動與設計上要怎麼改比較好呢? @lucien @stbb1025
• Enter 搜尋不直觀,而且 iOS 上 enter 會顯示「換行」
• 有時候其實只是想看一看搜尋結果,按搜尋旁邊的 X 關掉實在太不直觀
在互動與設計上要怎麼改比較好呢? @lucien @stbb1025
stbb1025
2020-07-22 16:01:09
有兩種做法:
1. 開始打字之後就即時顯示搜尋結果,這樣一樣維持按 X 關掉就不會很怪
2. 開始打字之後右邊除了顯示 X 之外也顯示 V 代表送出,或也可以變成「送出/取消」或「搜尋/取消」兩個按鈕
1. 開始打字之後就即時顯示搜尋結果,這樣一樣維持按 X 關掉就不會很怪
2. 開始打字之後右邊除了顯示 X 之外也顯示 V 代表送出,或也可以變成「送出/取消」或「搜尋/取消」兩個按鈕
mrorz
2020-07-22 17:09:16
關於「有時候其實只是想看一看搜尋結果」
這個情境是使用者打完字看到結果
捲動了一下搜尋結果,覺得沒有想要的東西
這個時候比較不會想到要回到搜尋框按旁邊的叉叉~
這個情境是使用者打完字看到結果
捲動了一下搜尋結果,覺得沒有想要的東西
這個時候比較不會想到要回到搜尋框按旁邊的叉叉~
mrorz
2020-07-22 17:11:37
這種 case 下
LINE 或 messenger 裡面搜尋模式時會加上的 banner + 「完成」按鈕或許會有些用?
banner 可以
1. 還沒搜完前顯示搜尋進度
2. 搜完之後顯示關鍵字本人
3. 擺放「完成」按鈕
缺點則是 banner 會佔去已經很少了的空間 QQ
LINE 或 messenger 裡面搜尋模式時會加上的 banner + 「完成」按鈕或許會有些用?
banner 可以
1. 還沒搜完前顯示搜尋進度
2. 搜完之後顯示關鍵字本人
3. 擺放「完成」按鈕
缺點則是 banner 會佔去已經很少了的空間 QQ
mrorz
2020-07-22 17:14:19
至於開始搜尋的時機,邊打字邊搜尋是不錯的嘗試
之前 old.cofacts.org 的實作則是在 on blur 的時候搜尋,不失為一種懶惰的做法 (?
之前 old.cofacts.org 的實作則是在 on blur 的時候搜尋,不失為一種懶惰的做法 (?
lucien
2020-07-26 22:40:25
我看到大松有好心人做了相關的基礎修正。
1. ios `<input type="search" />` 事實上只要他放進 form with action element 就可以讓 enter 變成 搜尋。
```<form action>
<input
type="search"
>
</form>```
2. 搜尋目前會完全取代輸入 textarea ,但我覺得這裡應該是展開一個新的區塊
3. 快速看一下搜尋結果這件事,我認爲是要加上 esc reset 搜尋的功能, auto complete 類型的快速預覽我覺得要放更壓縮的內容,比如說 hit search 的 summary
4. 我覺得桌面版可以考慮在右側開一個搜尋的浮動視窗,增加顯示內容
5. 我認為至少搜尋結果要至少可以看到一個完整的內容,這裡的桌面版卡片我想設計地更 compact
1. ios `<input type="search" />` 事實上只要他放進 form with action element 就可以讓 enter 變成 搜尋。
```<form action>
<input
type="search"
>
</form>```
2. 搜尋目前會完全取代輸入 textarea ,但我覺得這裡應該是展開一個新的區塊
3. 快速看一下搜尋結果這件事,我認爲是要加上 esc reset 搜尋的功能, auto complete 類型的快速預覽我覺得要放更壓縮的內容,比如說 hit search 的 summary
4. 我覺得桌面版可以考慮在右側開一個搜尋的浮動視窗,增加顯示內容
5. 我認為至少搜尋結果要至少可以看到一個完整的內容,這裡的桌面版卡片我想設計地更 compact
mrorz
13:50:18
關於這張票下面這兩個 user feedback:
• Enter 搜尋不直觀,而且 iOS 上 enter 會顯示「換行」
• 有時候其實只是想看一看搜尋結果,按搜尋旁邊的 X 關掉實在太不直觀
在互動與設計上要怎麼改比較好呢? @lucien @stbb1025
• Enter 搜尋不直觀,而且 iOS 上 enter 會顯示「換行」
• 有時候其實只是想看一看搜尋結果,按搜尋旁邊的 X 關掉實在太不直觀
在互動與設計上要怎麼改比較好呢? @lucien @stbb1025
mrorz
14:45:39
https://g0v.hackmd.io/D4KfdMRWS-OmCKd-Fhli2Q
這是週末讓大家標分類時會使用的定義
• 「目標編輯」就是想像目標會看、會回這類訊息的人是誰,是分類的重要依據
• 相關內容寫後面
請 @ggm @darkbtf @gary96302000.eecs96 看一下我對各個分類的認知是否跟你們一致唷
另外,現在分出來的感覺好像跟這份文件也滿不同的,不知道週六的協作場合下要怎麼進行 clean up 會比較好 QQ
最後,有些分類想要拆開或合併(如把性少數跟愛滋病分家,併到性平教育分類),不知道有沒有什麼比全部重標還要更聰明的做法
這是週末讓大家標分類時會使用的定義
• 「目標編輯」就是想像目標會看、會回這類訊息的人是誰,是分類的重要依據
• 相關內容寫後面
請 @ggm @darkbtf @gary96302000.eecs96 看一下我對各個分類的認知是否跟你們一致唷
另外,現在分出來的感覺好像跟這份文件也滿不同的,不知道週六的協作場合下要怎麼進行 clean up 會比較好 QQ
最後,有些分類想要拆開或合併(如把性少數跟愛滋病分家,併到性平教育分類),不知道有沒有什麼比全部重標還要更聰明的做法
stbb1025
16:01:09
有兩種做法:
1. 開始打字之後就即時顯示搜尋結果,這樣一樣維持按 X 關掉就不會很怪
2. 開始打字之後右邊除了顯示 X 之外也顯示 V 代表送出,或也可以變成「送出/取消」或「搜尋/取消」兩個按鈕
1. 開始打字之後就即時顯示搜尋結果,這樣一樣維持按 X 關掉就不會很怪
2. 開始打字之後右邊除了顯示 X 之外也顯示 V 代表送出,或也可以變成「送出/取消」或「搜尋/取消」兩個按鈕
mrorz
17:09:16
關於「有時候其實只是想看一看搜尋結果」
這個情境是使用者打完字看到結果
捲動了一下搜尋結果,覺得沒有想要的東西
這個時候比較不會想到要回到搜尋框按旁邊的叉叉~
這個情境是使用者打完字看到結果
捲動了一下搜尋結果,覺得沒有想要的東西
這個時候比較不會想到要回到搜尋框按旁邊的叉叉~
mrorz
17:11:37
這種 case 下
LINE 或 messenger 裡面搜尋模式時會加上的 banner + 「完成」按鈕或許會有些用?
banner 可以
1. 還沒搜完前顯示搜尋進度
2. 搜完之後顯示關鍵字本人
3. 擺放「完成」按鈕
缺點則是 banner 會佔去已經很少了的空間 QQ
LINE 或 messenger 裡面搜尋模式時會加上的 banner + 「完成」按鈕或許會有些用?
banner 可以
1. 還沒搜完前顯示搜尋進度
2. 搜完之後顯示關鍵字本人
3. 擺放「完成」按鈕
缺點則是 banner 會佔去已經很少了的空間 QQ
mrorz
17:14:19
至於開始搜尋的時機,邊打字邊搜尋是不錯的嘗試
之前 old.cofacts.org 的實作則是在 on blur 的時候搜尋,不失為一種懶惰的做法 (?
之前 old.cofacts.org 的實作則是在 on blur 的時候搜尋,不失為一種懶惰的做法 (?
bil
17:53:28
我覺得可以拿掉了唷
bil
17:53:51
設計師很帥>w<
kiang
18:51:04
Line 以外的也許以連結為主?之前新聞小幫手是以網址為主就是了
lucien
20:04:15
lucien
20:07:14
Replied to a thread: 2020-07-20 15:55:16
這個風格方向可以參考 https://steamcommunity.com/stats/698870/achievements
粗獷風格做外匡、陰影跟效果線等細節,讓成就看起來誘人,希望最後成果粗中有細,感謝熊!
粗獷風格做外匡、陰影跟效果線等細節,讓成就看起來誘人,希望最後成果粗中有細,感謝熊!
- 2
lucien
20:08:19
順帶一提這是知乎的
github
21:03:31
According to <https://g0v.hackmd.io/OC7BneJ3TEGJHge1hWV-0w#Cofacts-Next-%E8%BF%BD%E8%B9%A4|discussion>, we don't open articles page via LINE Notify anymore.
github
21:11:01
Done in <https://github.com/cofacts/rumors-site/pull/210|#210>, will continue tracking in <https://github.com/cofacts/rumors-site/issues/262|#262>
stbb1025
21:11:07
感謝回覆~~我覺得第一個steam的樣式滿不錯的,我會請熊照這個走向先畫三到五個精稿,擺上來給大家看看
lucien
21:24:19
現在有 crawler 比對的話,我覺得可以拿掉
github
21:28:27
As discussed on Slack in 7/22 we plan to remove the step that asks source. Closing this issue.
2020-07-23
mrorz
01:14:33
steam 的很讚
mrorz
02:27:05
今晚開會討論的大松標記事情呀
https://g0v.hackmd.io/9qp8dE7dReK2q8FTeP9Feg#%E5%88%86%E5%B7%A5
我覺得重整性別議題 / 愛滋病的工作
1. 有滿明確的範圍(就是處理原「性少數與愛滋病」標籤)
2. 時效性比 COVID-19 低
3. 比較適合直接在 excel 處理掉
所以我覺得大松集中在 `COVID-19 疫情` 與 `跨國互動` 新標籤比較重要
不知道有沒有合適作業的範圍呢?(如:優先標記最新的文章?或拿特定分類來標就好?要先開 `醫藥` parent category 嗎?直接開網站標、還是像小聚開好 tab 讓人認領好?)
https://g0v.hackmd.io/9qp8dE7dReK2q8FTeP9Feg#%E5%88%86%E5%B7%A5
我覺得重整性別議題 / 愛滋病的工作
1. 有滿明確的範圍(就是處理原「性少數與愛滋病」標籤)
2. 時效性比 COVID-19 低
3. 比較適合直接在 excel 處理掉
所以我覺得大松集中在 `COVID-19 疫情` 與 `跨國互動` 新標籤比較重要
不知道有沒有合適作業的範圍呢?(如:優先標記最新的文章?或拿特定分類來標就好?要先開 `醫藥` parent category 嗎?直接開網站標、還是像小聚開好 tab 讓人認領好?)
mrorz
02:34:02
好的,我週末抓一下對話資料
算一下開放之後會多多少訊息進資料庫~
算一下開放之後會多多少訊息進資料庫~
ichieh
17:38:32
Hi all,感謝大家年初的時候幫忙揪松撰寫的 Impact Report,終於在經過半年要準備印製了,在出版前希望請大家再確認內容,也歡迎有幫忙撰寫的專案可以再加上 2020 上半年的成果,審閱期至 7/27(一)中午 12:00,再麻煩大家了!
https://docs.google.com/document/d/1BRL9tLmilp14367UQnUTbNnZ-tnD5b6SZVujNX3GlD0/edit?usp=sharing
https://docs.google.com/document/d/1BRL9tLmilp14367UQnUTbNnZ-tnD5b6SZVujNX3GlD0/edit?usp=sharing
2020-07-24
github
02:36:33
*How to Reproduce* • `npm run dev` to start a dev server. • Open <http://localhost:3000/article/1fi7dla9wtwjn|http://localhost:3000/article/1fi7dla9wtwjn> with Google Chrome or Safari. • Click the `Login` button in top right corner. • You should be redirected to <https://cofacts.hacktabl.org/article/1fi7dla9wtwjn|https://cofacts.hacktabl.org/article/1fi7dla9wtwjn> • Go back to <http://localhost:3000/article/1fi7dla9wtwjn|http://localhost:3000/article/1fi7dla9wtwjn> • *What is expected*: You should be logged in, and your account should be shown in top right corner. • *What actually happened*: Not logged in, `Login` button is still shown in top right corner. *Additional Info* In both browser, there is no cookie from cofacts domain. *Google Chrome* Found the following message in developer console: ``` A cookie associated with a cross-site resource at <http://cofacts-api.hacktabl.org/> was set without the `SameSite` attribute. It has been blocked, as Chrome now only delivers cookies with cross-site requests if they are set with `SameSite=None` and `Secure`. You can review cookies in developer tools under Application>Storage>Cookies and see more details at <https://www.chromestatus.com/feature/5088147346030592> and <https://www.chromestatus.com/feature/5633521622188032>. ``` *Safari* Found the following message in javascript console: ``` [Error] The source list for Content Security Policy directive 'script-src' contains an invalid source: ''report-sample''. It will be ignored. ```
mrorz
2020-07-24 11:09:01
我昨天用了 move issue 的功能
把這張處理 sameSite cookie 的票,從 rumors-site 移動到 rumors-api 囉
把這張處理 sameSite cookie 的票,從 rumors-site 移動到 rumors-api 囉
mrorz
2020-07-24 11:09:42
主要是現在越來越多人會踩到這個問題 ><
old.cofacts.org 也有可能是因為這個問題而無法運作
old.cofacts.org 也有可能是因為這個問題而無法運作
github
04:04:15
Working on a <https://github.com/cofacts/rumors-api/tree/samesite|branch> to mitigate this, but blocked by `secure` detection issue: • <https://github.com/pillarjs/cookies/issues/51|pillarjs/cookies#51> • <https://github.com/koajs/koa/issues/974|koajs/koa#974>
mrorz
11:09:01
我昨天用了 move issue 的功能
把這張處理 sameSite cookie 的票,從 rumors-site 移動到 rumors-api 囉
把這張處理 sameSite cookie 的票,從 rumors-site 移動到 rumors-api 囉
mrorz
11:09:42
主要是現在越來越多人會踩到這個問題 ><
old.cofacts.org 也有可能是因為這個問題而無法運作
old.cofacts.org 也有可能是因為這個問題而無法運作
github
13:50:40
As discussed in 0722, we are going to let collaborators try out our category UI in the hackathon tomorrow. In order to properly display the <https://g0v.hackmd.io/D4KfdMRWS-OmCKd-Fhli2Q|category definition>, we add line breaks to make descriptions more readable. <https://user-images.githubusercontent.com/108608/88364059-70e3b500-cdb4-11ea-825b-0c72da281ce7.png|image>
mrorz
2020-07-24 13:51:08
這個今晚想進,請大家協助 review m(_ _)m
mrorz
13:51:08
這個今晚想進,請大家協助 review m(_ _)m
mrorz
13:57:49
@ggm 請問之前 category 是怎麼從 staging sync 到 production 的呢
我現在在做類似的事情 ._.
我現在在做類似的事情 ._.
應該是跑個 script @darkbtf
mrorz
2020-07-24 14:07:10
204
ggm
14:04:40
應該是跑個 script @darkbtf
mrorz
14:07:10
204
mrorz
22:36:10
我發現禮拜三 merge 進 dev 的我的 rumors-site refactor 會把整個 dev 弄壞 QQ
mrorz
23:25:56
但新的 category 還沒放
bil
23:26:50
感謝感謝
2020-07-25
mrorz
08:59:55
bil
09:00:32
看到了
dang
09:28:20
@vulxj0j8j8 has joined the channel
fly
10:30:30
AI 自動分類好帥啊啊啊,想訂閱主題但出現 Internal Server Error
https://cofacts.g0v.tw/api/articles/rss2?categoryIds=kj287XEBrIRcahlYvQoS
https://cofacts.g0v.tw/api/articles/rss2?categoryIds=kj287XEBrIRcahlYvQoS
mrorz
2020-07-27 10:41:20
swind
12:10:10
@swind has joined the channel
github
14:23:20
Done 搜尋框加上「參考過往回應」的 placeholder 使理由與來源的 input 能垂直拉大 增加搜尋圖示提供搜尋功能,而不是只能用 Enter TODOs 使理由與來源的 input 水平方向則固定 搜尋時加上 loading indicator 修正 iOS 點按「Add this reply to my reply」送出的問題
ggm
15:49:58
@darkbtf AI-master 的 production 的 cron job 有開嗎?沒開的話把他跑起來吧
github
16:41:11
ArticleInfo should query for articleReplies as it is using articleReply data. *Before* <https://user-images.githubusercontent.com/108608/88452851-9b0ca400-ce94-11ea-9b1f-15e8fdf0547e.png|image> *After* Detail page can load without problem *Analysis* `<ArticleInfo>` in `ArticleDetail` page actually uses `articleReplies` field. However, It's not declared in its fragment, thus `articleReplies` fields are not populated properly in detail page. This PR adds the field in loading sequence so that the field exists no matter where `<ArticleInfo>` is used.
github
17:07:29
Thank you for locating the root cause! After trying the UI out, I found that `flex: 1` is actually required on mobile to enlarge the textarea. I suggest leaving `flex: 1` as-is and adding the following in `[theme.breakpoints.up('md')]`: ``` flex: 'none', // Disable flex so that user can enlarge textarea by themselves minHeight: 144, ```
potsung.wang
17:33:59
@potsung.wang has joined the channel
github
18:01:38
Personally I would prefer `onExpanded` or `onToggle` because this is the scenario that a child component component notifies parent component about something happening. Parent component can determine how to react to such event. ``` <GlobalSearch onExpand={expanded => setDisplayLogo(!expanded)} /> ```
github
23:16:36
I've refactor the relation between the parent and the child component so that parent listen to child's change rather then the child change the parent directly
2020-07-26
lucien
22:40:25
Replied to a thread: 2020-07-22 13:49:22
我看到大松有好心人做了相關的基礎修正。
1. ios `<input type="search" />` 事實上只要他放進 form with action element 就可以讓 enter 變成 搜尋。
```<form action>
<input
type="search"
>
</form>```
2. 搜尋目前會完全取代輸入 textarea ,但我覺得這裡應該是展開一個新的區塊
3. 快速看一下搜尋結果這件事,我認爲是要加上 esc reset 搜尋的功能, auto complete 類型的快速預覽我覺得要放更壓縮的內容,比如說 hit search 的 summary
4. 我覺得桌面版可以考慮在右側開一個搜尋的浮動視窗,增加顯示內容
5. 我認為至少搜尋結果要至少可以看到一個完整的內容,這裡的桌面版卡片我想設計地更 compact
1. ios `<input type="search" />` 事實上只要他放進 form with action element 就可以讓 enter 變成 搜尋。
```<form action>
<input
type="search"
>
</form>```
2. 搜尋目前會完全取代輸入 textarea ,但我覺得這裡應該是展開一個新的區塊
3. 快速看一下搜尋結果這件事,我認爲是要加上 esc reset 搜尋的功能, auto complete 類型的快速預覽我覺得要放更壓縮的內容,比如說 hit search 的 summary
4. 我覺得桌面版可以考慮在右側開一個搜尋的浮動視窗,增加顯示內容
5. 我認為至少搜尋結果要至少可以看到一個完整的內容,這裡的桌面版卡片我想設計地更 compact
- 1
2020-07-27
stbb1025
10:35:58
https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=912%3A384
成就部分我請插畫家先針對首次闢謠上了色,我放在 UI 裡給大家看看
有三種風格,其中最右邊應該是最接近 Lucien 提的 steam 樣式
歡迎發表看法~
@lucien @mrorz @bil
成就部分我請插畫家先針對首次闢謠上了色,我放在 UI 裡給大家看看
有三種風格,其中最右邊應該是最接近 Lucien 提的 steam 樣式
歡迎發表看法~
@lucien @mrorz @bil
- 🐳1
- 🦒1
讓我們多多為這個提供看法,有看法請在接下來兩小時內提出來=D@ggm @lucien @acerxp511
mrorz
2020-07-29 20:07:32
最左邊的色彩很繽紛
badge 是個滿值得色彩繽紛的地方
badge 是個滿值得色彩繽紛的地方
文武喜歡中間的=D喜歡感覺
lucien
2020-07-29 21:35:03
最右邊的顏色搭配會看不清楚圖樣耶
stbb1025
2020-07-29 22:54:25
嗯嗯看不清楚圖樣的話可以換別的底色,但有可能會跟UI配色風格有落差
stbb1025
2020-07-29 22:56:52
不過不管這三個哪個詮釋方式,都可以再調整顏色,重點是詮釋方式要:
1.繽紛黑線
2.單色黑線
3.單色白線
再麻煩大家選擇了,謝謝。
1.繽紛黑線
2.單色黑線
3.單色白線
再麻煩大家選擇了,謝謝。
lucien
2020-07-30 00:24:13
白線現在因為背景關係,我覺得大家都不會選哈哈😂
lucien
2020-07-30 00:24:20
這樣我選1,2
lucien
2020-07-30 00:27:21
然後現在縮放比例到 100 %的時候,細節已經看不清楚了,單色版之後調整可以參考 Metaverse Keeper 的效果線,跟負空間畫法
https://steamcommunity.com/stats/698870/achievements
https://steamcommunity.com/stats/698870/achievements
lucien
2020-07-30 00:28:08
以白色為例,機器人的臉是塗白,但線條挖空的畫法
mrorz
2020-07-30 01:26:34
凹版印刷變凸版印刷的感覺 (?
mrorz
2020-07-30 01:26:45
如果要白色作圖的話,底色可能要選得像是 landing page 闢謠者聯盟招手那塊那麼深
那邊就有負空間作畫感
那邊就有負空間作畫感
stbb1025
2020-07-30 08:39:18
好那我們就以黑色彩色為方向繼續進行囉~
然後細節會再加強
感恩
然後細節會再加強
感恩
mrorz
10:41:20
mrorz
12:36:50
https://github.com/cofacts/rumors-site/pull/298 這個是個小小 fix
但可以早日 merge,否則 dev 會是壞的 QQ
但可以早日 merge,否則 dev 會是壞的 QQ
ArticleInfo should query for articleReplies as it is using articleReply data. *Before* Staging: <https://user-images.githubusercontent.com/108608/88452851-9b0ca400-ce94-11ea-9b1f-15e8fdf0547e.png|image> Localhost: <https://user-images.githubusercontent.com/108608/88452996-c9d74a00-ce95-11ea-971f-dade9b3dfe1c.png|image> *After* Detail page can load without problem *Analysis* `<ArticleInfo>` in `ArticleDetail` page actually uses `articleReplies` field. However, It's not declared in its fragment, thus `articleReplies` fields are not populated properly in detail page. This PR adds the field in loading sequence so that the field exists no matter where `<ArticleInfo>` is used.
github
13:23:45
When using `babel-node`, we should be able to run from `src/script` directly, or there may be error when it's not built yet
github
13:48:50
<https://coveralls.io/builds/32335154|Coverage Status> Coverage increased (+0.02%) to 86.849% when pulling *<https://github.com/cofacts/rumors-api/commit/ed6b99aa581ea3f19f2f6125dee119ae53fedd09|ed6b99a> on replyrequests* into *<https://github.com/cofacts/rumors-api/commit/236152b3af550ddebce0b110e3458bf3941c84dc|236152b> on master*.
mrorz
14:15:23
rumors-line-bot staging 成功連線到 MongoDB Atlas 囉!
請 @acerxp511 @ggm 把自己的 MongoDB Atlas 帳號私訊給我,我把大家加到 Cofacts organization 來
請 @acerxp511 @ggm 把自己的 MongoDB Atlas 帳號私訊給我,我把大家加到 Cofacts organization 來
- 👌1
已私
ggm
14:17:28
已私
2020-07-28
github
13:36:44
*As-is* *Desktop* <https://user-images.githubusercontent.com/108608/88622890-4f493d00-d0d6-11ea-8f80-a570689c0739.png|image> *Mobile* <https://user-images.githubusercontent.com/108608/88622952-6851ee00-d0d6-11ea-95bf-32535bc8ee75.png|image> *To-be* • Add progress bar in desktop menu • Add "仍須 N 篇闢謠升級" / "N replies left to next level" (無需如圖般左右對齊,直接置中對齊也可以) • Clicking name should allow user to change their name using <https://developer.mozilla.org/en-US/docs/Web/API/Window/prompt|`window.prompt()`>. *Desktop* <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=138%3A25|https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=138%3A25> <https://user-images.githubusercontent.com/108608/88622868-448ea800-d0d6-11ea-9281-c394108c105c.png|image> *Mobile* <https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=235%3A666|https://www.figma.com/file/zpD45j8nqDB2XfA6m2QskO/Cofacts-website?node-id=235%3A666> <https://user-images.githubusercontent.com/108608/88622996-861f5300-d0d6-11ea-8316-89c13b28891a.png|image>
2020-07-29
github
14:29:08
This PR implements `<Infos>` and `<TimeInfo>` and reuse them in `<ArticleInfo>` and `<ReplyInfo>` temporarily. Actually, in the mockup the info lines are very diverse and has different info to display in each place. In the future, `<ArticleInfo>` and `<ReplyInfo>` will be removed, and `<Infos>` and `<TimeInfo>` will be directly used in article items instead. *Storybook* <https://user-images.githubusercontent.com/108608/88764598-cef30c80-d1a7-11ea-8d7e-cda42676579d.gif|info optional> <https://user-images.githubusercontent.com/108608/88764605-d0243980-d1a7-11ea-8dcf-78bbdc20ef3f.gif|TimeINfo> *Reply list* <https://user-images.githubusercontent.com/108608/88764230-2644ad00-d1a7-11ea-92a4-6721f7ac23b1.png|image> *Article detail* <https://user-images.githubusercontent.com/108608/88764283-42484e80-d1a7-11ea-8c53-f85812de3238.png|image>
mrorz
2020-07-29 14:34:09
這也是 article list refactor 的副產品
就是把 Cofacts UI 裡常見的 `A| B | C` 這個東西包成 component
由於 UI 裡面用到滿多這種外觀的東西,它們外觀上一致,但內容很多樣,所以想說包成外觀 component。
現有的 `ArticleInfo` 與 `ReplyInfo` 兩個 component,暫時先在內部實作改用 `Infos`。未來這兩者會直接被內容自由度更高的 `Infos` 完全取代。
就是把 Cofacts UI 裡常見的 `A| B | C` 這個東西包成 component
由於 UI 裡面用到滿多這種外觀的東西,它們外觀上一致,但內容很多樣,所以想說包成外觀 component。
現有的 `ArticleInfo` 與 `ReplyInfo` 兩個 component,暫時先在內部實作改用 `Infos`。未來這兩者會直接被內容自由度更高的 `Infos` 完全取代。
mrorz
14:34:09
這也是 article list refactor 的副產品
就是把 Cofacts UI 裡常見的 `A| B | C` 這個東西包成 component
由於 UI 裡面用到滿多這種外觀的東西,它們外觀上一致,但內容很多樣,所以想說包成外觀 component。
現有的 `ArticleInfo` 與 `ReplyInfo` 兩個 component,暫時先在內部實作改用 `Infos`。未來這兩者會直接被內容自由度更高的 `Infos` 完全取代。
就是把 Cofacts UI 裡常見的 `A| B | C` 這個東西包成 component
由於 UI 裡面用到滿多這種外觀的東西,它們外觀上一致,但內容很多樣,所以想說包成外觀 component。
現有的 `ArticleInfo` 與 `ReplyInfo` 兩個 component,暫時先在內部實作改用 `Infos`。未來這兩者會直接被內容自由度更高的 `Infos` 完全取代。
fly
14:53:29
https://credibilitycoalition.org/credcatalog/
This is an effort to compile projects and initiatives that aim to improve information quality. We are collecting information on fact-checking groups, technology tools, academic research institutions and so much more. Explore our growing list of entries by geography, language, funders and solutions categories.
This is an effort to compile projects and initiatives that aim to improve information quality. We are collecting information on fact-checking groups, technology tools, academic research institutions and so much more. Explore our growing list of entries by geography, language, funders and solutions categories.
Credibility Coalition
Welcome to CredCatalog. This is an effort to compile projects and initiatives that aim to improve information quality. We are collecting information on fact-checking groups, technology tools, academic research institutions and so much more. Explore our growing list of entries by geography, language, funders and solutions categories.
- 1
mrorz
2020-07-29 15:17:11
感謝資訊
我發現這裡可以送出新的:https://docs.google.com/document/d/19bXZOQ-KfzHtF4EJ8iKHgLDFHItT6A7D9766YkhmbB0/edit
所以我就送了一份 XD
我發現這裡可以送出新的:https://docs.google.com/document/d/19bXZOQ-KfzHtF4EJ8iKHgLDFHItT6A7D9766YkhmbB0/edit
所以我就送了一份 XD
mrorz
2020-07-29 15:17:27
MyGoPen 好像也可以送一份?
mrorz
2020-07-29 15:26:09
W3C 的 Credible Web Community Group 看起來滿 active 的耶,開會記錄也都會上網
https://credweb.org/
https://credweb.org/
已推坑 MyGoPen Rob~
mrorz
2020-07-29 19:05:18
感謝
mrorz
15:17:11
感謝資訊
我發現這裡可以送出新的:https://docs.google.com/document/d/19bXZOQ-KfzHtF4EJ8iKHgLDFHItT6A7D9766YkhmbB0/edit
所以我就送了一份 XD
我發現這裡可以送出新的:https://docs.google.com/document/d/19bXZOQ-KfzHtF4EJ8iKHgLDFHItT6A7D9766YkhmbB0/edit
所以我就送了一份 XD
mrorz
15:17:27
MyGoPen 好像也可以送一份?
mrorz
15:26:09
W3C 的 Credible Web Community Group 看起來滿 active 的耶,開會記錄也都會上網
https://credweb.org/
https://credweb.org/
fly
16:34:13
已推坑 MyGoPen Rob~
mrorz
19:05:18
感謝
bil
20:03:57
Replied to a thread: 2020-07-27 10:35:58
讓我們多多為這個提供看法,有看法請在接下來兩小時內提出來=D@ggm @lucien @acerxp511
bil
20:06:00
比鄰喜歡style 1,這樣在很遠的地方也可以看得很清楚
mrorz
20:07:32
最左邊的色彩很繽紛
badge 是個滿值得色彩繽紛的地方
badge 是個滿值得色彩繽紛的地方
bil
20:12:10
文武喜歡中間的=D喜歡感覺
bil
20:18:54
文武喜歡中間的=D喜歡感覺
lucien
21:35:03
最右邊的顏色搭配會看不清楚圖樣耶
stbb1025
22:54:25
嗯嗯看不清楚圖樣的話可以換別的底色,但有可能會跟UI配色風格有落差
stbb1025
22:56:52
不過不管這三個哪個詮釋方式,都可以再調整顏色,重點是詮釋方式要:
1.繽紛黑線
2.單色黑線
3.單色白線
再麻煩大家選擇了,謝謝。
1.繽紛黑線
2.單色黑線
3.單色白線
再麻煩大家選擇了,謝謝。
2020-07-30
lucien
00:24:13
白線現在因為背景關係,我覺得大家都不會選哈哈😂
lucien
00:24:20
這樣我選1,2
lucien
00:27:21
然後現在縮放比例到 100 %的時候,細節已經看不清楚了,單色版之後調整可以參考 Metaverse Keeper 的效果線,跟負空間畫法
https://steamcommunity.com/stats/698870/achievements
https://steamcommunity.com/stats/698870/achievements
lucien
00:28:08
以白色為例,機器人的臉是塗白,但線條挖空的畫法
mrorz
01:26:34
凹版印刷變凸版印刷的感覺 (?
mrorz
01:26:45
如果要白色作圖的話,底色可能要選得像是 landing page 闢謠者聯盟招手那塊那麼深
那邊就有負空間作畫感
那邊就有負空間作畫感
github
05:33:32
Bumps <https://github.com/indutny/elliptic|elliptic> from 6.5.1 to 6.5.3. Commits • <https://github.com/indutny/elliptic/commit/8647803dc3d90506aa03021737f7b061ba959ae1|`8647803`> 6.5.3 • <https://github.com/indutny/elliptic/commit/856fe4d99fe7b6200556e6400b3bf585b1721bec|`856fe4d`> signature: prevent malleability and overflows • <https://github.com/indutny/elliptic/commit/60489415e545efdfd3010ae74b9726facbf08ca8|`6048941`> 6.5.2 • <https://github.com/indutny/elliptic/commit/9984964457c9f8a63b91b01ea103260417eca237|`9984964`> package: bump dependencies • <https://github.com/indutny/elliptic/commit/ec735edde187a43693197f6fa3667ceade751a3a|`ec735ed`> utils: leak less information in `getNAF()` • See full diff in <https://github.com/indutny/elliptic/compare/v6.5.1...v6.5.3|compare view> <https://help.github.com/articles/configuring-automated-security-fixes|Dependabot compatibility score> Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`. * * * Dependabot commands and options You can trigger Dependabot actions by commenting on this PR: • `@dependabot rebase` will rebase this PR • `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it • `@dependabot merge` will merge this PR after your CI passes on it • `@dependabot squash and merge` will squash and merge this PR after your CI passes on it • `@dependabot cancel merge` will cancel a previously requested merge and block automerging • `@dependabot reopen` will reopen this PR if it is closed • `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually • `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself) • `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself) • `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language • `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language • `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language • `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language You can disable automated security fix PRs for this repo from the <https://github.com/cofacts/rumors-site/network/alerts|Security Alerts page>.
stbb1025
08:39:18
好那我們就以黑色彩色為方向繼續進行囉~
然後細節會再加強
感恩
然後細節會再加強
感恩
github
12:56:36
Fix <https://g0v.hackmd.io/r3NK7xssSwCNPFxthlw7tA#%E2%9B%94%EF%B8%8F-Release-Blockers1|20200729 release blocker>. *Screenshot* <https://user-images.githubusercontent.com/108608/88882177-ef809c80-d263-11ea-87c4-93db092bb067.png|image>
mrorz
2020-07-30 12:56:58
這是今晚預計 release 的 release blocker 的 fix 唷
github
18:23:28
There's an edge case when the cron job runs at midnight, the first cron job of the day should also update the value for yesterday ie. if the last cron job of the day runs at 23:00, and the next one runs at 0:00, any activities between the last cron job till midnight won't be accounted for. I'm not sure if this should be handled by the script itself (i.e. check if current time is near midnight), or just set another cron job to run it once a day. The former is kinda weird and needs to watch out for the timezone setting of the server and GA. The later has a catch, that is, to run the script for any dates other than today would be ran in migration setting, which would use url path to determine doc id instead of content grouping. It shouldn't be that big of a day since there aren't that many entries per day...
mrorz
2020-07-30 23:23:13
如果我們跟 Google analytics 要以小時為精度的資料
寫進 elasticsearch 的時候也是小時為精度
只有在 rumors-api 吐給 UI 時使用 elasticsearch 的 date histogram aggregation 弄成一天天 (可能在這裡才處理時區問題)
這樣會比較好做嗎?
寫進 elasticsearch 的時候也是小時為精度
只有在 rumors-api 吐給 UI 時使用 elasticsearch 的 date histogram aggregation 弄成一天天 (可能在這裡才處理時區問題)
這樣會比較好做嗎?
GA 那邊可以設時區,我有去看cofacts設定的時區是台北,所以他的「當日」流量是看台北時間的當日
我是覺得好像沒有必要在db存到每個小時的流量,如果要往前回朔抓資料的話也等於要花24倍的的 quota
除非之後有應用需要到那麼細的資料,不然我覺得好像確定 server 跟GA那邊的時區是一致的可能會比較簡單,或是不要依賴server設定的話也是可以記錄GA的時區用moment timezone之類的調一下
我也有想過目前我是用是cronjob查 contentgroup 不然查 url的分辨方法,也可以改成 2020/7/xx 之後的資料查 contentgroup 之前再看 url
除非之後有應用需要到那麼細的資料,不然我覺得好像確定 server 跟GA那邊的時區是一致的可能會比較簡單,或是不要依賴server設定的話也是可以記錄GA的時區用moment timezone之類的調一下
我也有想過目前我是用是cronjob查 contentgroup 不然查 url的分辨方法,也可以改成 2020/7/xx 之後的資料查 contentgroup 之前再看 url
_Time zone country or territory_: The country or territory and the time zone you want to use as the day boundary for your reports, regardless of where the data originates. For example, if you choose _United States, Los Angeles Time_, then the beginning and end of each day is calculated based on Los Angeles Time, even if the hit comes from New York, London, or Moscow.
https://support.google.com/analytics/answer/1010249?hl=en
https://support.google.com/analytics/answer/1010249?hl=en
補一下來源 XD
github
18:27:49
<https://coveralls.io/builds/32423923|Coverage Status> Coverage increased (+0.8%) to 87.593% when pulling *<https://github.com/cofacts/rumors-api/commit/7dc45064a84a9ae4e129d45dc77d1ff44270ae23|7dc4506> on fetchGA* into *<https://github.com/cofacts/rumors-api/commit/236152b3af550ddebce0b110e3458bf3941c84dc|236152b> on master*.
mrorz
23:23:13
如果我們跟 Google analytics 要以小時為精度的資料
寫進 elasticsearch 的時候也是小時為精度
只有在 rumors-api 吐給 UI 時使用 elasticsearch 的 date histogram aggregation 弄成一天天 (可能在這裡才處理時區問題)
這樣會比較好做嗎?
寫進 elasticsearch 的時候也是小時為精度
只有在 rumors-api 吐給 UI 時使用 elasticsearch 的 date histogram aggregation 弄成一天天 (可能在這裡才處理時區問題)
這樣會比較好做嗎?
2020-07-31

mrorz
14:38:55
最近剛好在重整 article list
週日 4000 提到,文章列表裡面希望可以放文章超連結的 title。
下面是我用志超 search result 的 UI,拿掉 URL description 之後試排的結果。我比較喜歡沒有 URL 的版本 XD
https://www.figma.com/file/DvmAQjMJCncuPORWKnljM1/Cofacts-website-MrOrz-s-copy?node-id=2675%3A221
週日 4000 提到,文章列表裡面希望可以放文章超連結的 title。
下面是我用志超 search result 的 UI,拿掉 URL description 之後試排的結果。我比較喜歡沒有 URL 的版本 XD
https://www.figma.com/file/DvmAQjMJCncuPORWKnljM1/Cofacts-website-MrOrz-s-copy?node-id=2675%3A221
github
19:04:06
Fixes <https://github.com/cofacts/rumors-site/issues/262|#262> feedUrl cannot handle options passed by ArticlePageLayout, so put option into query.