#disinfo
2020-01-01
lexifdev
10:44:57
yeah. many websites are cannot crawl without real browser based tool.
but I always try this once.
every time I crawl Facebook, I use mobile website (https://iphone.facebook.com/ or https://iphone.facebook.com/). it has also ‘noscript’ version.
some sites that blocked by ‘User-Agent’ or ‘Referer’ are can avoid by
```session = requests.Session()
session.headers.update('Referer', 'https://~~~') # or
session.headers.update('User-Agent', 'Mozilla/5.0 ~~~~')```
(maybe you already know)
but I always try this once.
every time I crawl Facebook, I use mobile website (https://iphone.facebook.com/ or https://iphone.facebook.com/). it has also ‘noscript’ version.
some sites that blocked by ‘User-Agent’ or ‘Referer’ are can avoid by
```session = requests.Session()
session.headers.update('Referer', 'https://~~~') # or
session.headers.update('User-Agent', 'Mozilla/5.0 ~~~~')```
(maybe you already know)
iphone.facebook.com
Create an account or log into Facebook. Connect with friends, family and other people you know. Share photos and videos, send messages and get updates.
pm5
11:19:41
這啥⋯⋯
chihao
11:25:20
中時怎麼了
chihao
11:49:09
我以為《反滲透法》對衍明無效 
pm5
12:13:35
昨天晚上重新開始 hourly 跑 batch_discover 了。看 log 感覺都有順利被砍掉,不知道 memory 情況如何?
pm5
12:14:01
特別是 selenium 有沒有順利 kill 掉
ronnywang
13:23:12
應該是有正常砍掉,看起來沒有再累積了
pm5
13:54:13
感謝 🙏 新年快樂
isabelhou
19:00:21
不是說中天中時要停播停刊
2020-01-02
Victoria Welborn
02:34:11
Hi @chihao and @pm5 happy new year! I spoke to the production company and Luke - my POC there - said he’d happily interview you both on the 4th at the hackathon, without me (if that still works for you both)! I will introduce you both to him via email shortly. Thank you for your patience and understanding!
chihao
09:23:12
假新聞、假訊息,到底長什麼樣子?從哪裡來?要回答這個問題,首先,要有資料。
由 g0v 社群參與者發起,《零時檔案局》要用開源鄉民的力量,備份台灣資訊空間。目前,《零時檔案局》已經備份了 274,501 篇來自一般新聞網站、可疑內容農場的文章,不一起來研究一下嗎?
這週六,2020 年 1 月 4 日,第零次不實資訊松,一起來玩資料、挖掘不實訊息的面貌吧 🙋♀️🙋♂️ 已經報名的朋友,今、明兩天請密切注意通知地點的 email 😎
報名由此去 → https://forms.gle/kqffyonCYWTdeUgk8
更多資訊 → https://g0v.hackmd.io/@chihao/0archive/
由 g0v 社群參與者發起,《零時檔案局》要用開源鄉民的力量,備份台灣資訊空間。目前,《零時檔案局》已經備份了 274,501 篇來自一般新聞網站、可疑內容農場的文章,不一起來研究一下嗎?
這週六,2020 年 1 月 4 日,第零次不實資訊松,一起來玩資料、挖掘不實訊息的面貌吧 🙋♀️🙋♂️ 已經報名的朋友,今、明兩天請密切注意通知地點的 email 😎
報名由此去 → https://forms.gle/kqffyonCYWTdeUgk8
更多資訊 → https://g0v.hackmd.io/@chihao/0archive/

 3
3- ❤️2
mrorz
2020-01-02 10:52:33
是說我跟比鄰會去君竹開的 workshop,時間有所衝突,我應該會下午才到唷
chihao
2020-01-02 10:53:13
哦哦哦,有活動資訊嗎?
a-chioh
2020-01-02 18:59:34
請問,不在台灣的人可以線上參加嗎?
a-chioh
2020-01-02 19:03:40
(資料在哪裡?)
a-chioh
2020-01-02 20:46:20
(the links from 12/21 seem to be dead)
chihao
10:53:13
哦哦哦,有活動資訊嗎?
mrorz
11:06:41
facebook.com
【敬邀參加1月4日「未來媒體工作坊」】 *#人數已滿,表單關閉* 各位媒體前輩好,我是台大新聞所學生會會長蘇彥誠。1月4日,台大新聞所學生會和「公視P#新聞實驗室」合辦一場「#未來媒體工作坊」,主講人包含本所碩三學生方君竹Jun-Zhu Fang、事實查核中心查核記者劉芮菁。 在一整天的工作坊當中,將聚焦「#事實查核數位工具」、「#記者真心話產製心法」兩大主題。...
- 🙌1
a-chioh
18:57:50
@a-chioh has joined the channel
a-chioh
18:59:34
請問,不在台灣的人可以線上參加嗎?
a-chioh
19:03:40
(資料在哪裡?)
a-chioh
20:46:20
(the links from 12/21 seem to be dead)
2020-01-03
shuchen
05:40:37
@linshuchen922 has joined the channel
yitzu
10:49:05
@yitzu7 has joined the channel
Hung-Yi Wu
12:37:44
@hywu0110 has joined the channel
chihao
15:25:47
📧 sent 😉
pm5
18:48:51
@ronnywang 如果你有空的話,我需要你幫忙砍掉 NewsScraper tainan-sun-500796 的 Python process XD 它們卡住 db migration 了。然後想問一下為什麼 run_discover.sh 的 cronjob log 都沒有出現呀?
ronnywang
22:17:35
哈哈,看到累積好多.. 目前 middle2 的寫法 cron 要跑完 cronjob log 才會寫入
ronnywang
22:17:42
但是因為卡住了所以就沒寫入了
ronnywang
22:19:03
我把超過一小時的都砍掉了
pm5
23:47:17
orz
2020-01-04
pm5
00:40:01
看來還是有點問題,那我先把 hourly discover cronjob 關掉
pm5
01:25:42
上次把 middle2 搞到用完記憶體的 memory leak 問題,我把 parser 改成每次最多只跑 20000 筆資料就結束,經過測試應該都可以在 1 小時內跑完,這樣子地暫時解決了
 1
1
pm5
11:56:04
theinitium.com
宮廟的「公共」與「政治」性格,使其在地方選舉中佔有一席之地。數年一次的地方選舉,讓各地方的政治勢力與廟宇互動密切,成為社會關係確認、交換與展演的場所。但宮廟是否確實影響選舉?透過互動地圖,我們帶你一次看懂。
 1
1
pm5
11:56:17
端傳媒 Initium Media
近年來,不少媽祖廟都有赴陸交流的經驗,誰去得最多?他們為何想去?去了就等於「被滲透」嗎?
ronnywang
12:50:58
more like this 發現到怒吼跟芋傳媒轉同一篇新聞 XD
https://taronews.tw/2019/10/04/485580/
https://nooho.net/2019/10/DPPfraud26257/
https://taronews.tw/2019/10/04/485580/
https://nooho.net/2019/10/DPPfraud26257/
芋傳媒 TaroNews
台北市長柯文哲指總統府祕書長陳菊「不是妳上半生坐過牢,下半生就可以為非作歹」,他今天表示,民進黨要誠實面對高雄執政失敗而選輸的事實,對於被要求道歉則說「管他的」。

chihao
13:16:18
那個,小松現在午休中,大家吃飯後會回歸(吧?)
ronnywang
14:11:11
@pm5 好像有些內容有 parsing 錯誤?像是 46449, 47303, 47330, 46914 的 publication_text 都一樣,但是跟標題不合
先記下有錯誤的 id,我們有時間的話看看吧
pm5
14:12:04
先記下有錯誤的 id,我們有時間的話看看吧
tumi
14:19:15
@tumi729 has joined the channel
pm5
14:41:43
怒吼蠻有趣的,有點像是某個視角的媒體分析器 https://g0vhackmd.blob.core.windows.net/g0v-hackmd-images/upload_5711749a233bae2dfdc2bfaef2d8ff34
ronnywang
15:59:15
 1
1- 👏1
ronnywang
2020-01-04 16:00:26
用 Elasticsearch 的 morelikethis 找出哪些文章相似度是 > 2.0 (分數是直接拿 elasticsearch 算的,所以不知道 2.0 的標準是什麼,只是感覺 2.0 這個數字好像抓出來的效果還不錯)
mrorz
2020-01-04 23:43:56
`_score` 是各 query term 的 weighted tf-idf 和唷。tf-idf 是 (normalized) term frequency 與 inverse document frequency 的積。
如果是 request body search,可以打開 `explain:true` 請它列出計算公式與各項 (https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-explain)
另外也有 explain API,explain 結果像這樣:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
所以大致上是
1. query 越長、字越多,「各 query term 的 tf-idf 和」會越大。因此,*tf-idf 對不同 query 來說沒有可比性,只能用來比較同一個 search query 底下不同 document 的 relevance score。因為 query length、query 用的字是否有鑑別力,都會影響 _score 的大小*。
2. 單一 term 出現在越多文件(越沒辨別力),該 term 的 tf-idf 會變小,導致整體「tf-idf 和」變少。
3. 單一 term 出現在被打分數的這篇文章越多次,tf-idf 會變大,導致整體「tf-idf 和」變大。
如果是 request body search,可以打開 `explain:true` 請它列出計算公式與各項 (https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-explain)
另外也有 explain API,explain 結果像這樣:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
所以大致上是
1. query 越長、字越多,「各 query term 的 tf-idf 和」會越大。因此,*tf-idf 對不同 query 來說沒有可比性,只能用來比較同一個 search query 底下不同 document 的 relevance score。因為 query length、query 用的字是否有鑑別力,都會影響 _score 的大小*。
2. 單一 term 出現在越多文件(越沒辨別力),該 term 的 tf-idf 會變小,導致整體「tf-idf 和」變少。
3. 單一 term 出現在被打分數的這篇文章越多次,tf-idf 會變大,導致整體「tf-idf 和」變大。
mrorz
2020-01-04 23:48:32
Cofacts chatbot 後來其實是
用 elasticsearch 的 more-like-this 抓出前幾名 document 當成 search hit,
然後再另外用其他 string similarity (https://github.com/aceakash/string-similarity)來算 0~1 的相似度。
用 elasticsearch 的 more-like-this 抓出前幾名 document 當成 search hit,
然後再另外用其他 string similarity (https://github.com/aceakash/string-similarity)來算 0~1 的相似度。
ronnywang
16:00:26
用 Elasticsearch 的 morelikethis 找出哪些文章相似度是 > 2.0 (分數是直接拿 elasticsearch 算的,所以不知道 2.0 的標準是什麼,只是感覺 2.0 這個數字好像抓出來的效果還不錯)
pm5
17:39:53
我先走囉,今天謝謝大家參與
chihao
17:40:39
\pm5/
kwangyin.liu
17:44:33
@kwangyin.liu has joined the channel
julialiu
20:21:29
@julialiu2223 has joined the channel
Richard
22:20:01
@hlshao2 has joined the channel
mrorz
23:43:56
`_score` 是各 query term 的 weighted tf-idf 和唷。tf-idf 是 (normalized) term frequency 與 inverse document frequency 的積。
如果是 request body search,可以打開 `explain:true` 請它列出計算公式與各項 (https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-explain)
另外也有 explain API,explain 結果像這樣:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
所以大致上是
1. query 越長、字越多,「各 query term 的 tf-idf 和」會越大。因此,*tf-idf 對不同 query 來說沒有可比性,只能用來比較同一個 search query 底下不同 document 的 relevance score。因為 query length、query 用的字是否有鑑別力,都會影響 _score 的大小*。
2. 單一 term 出現在越多文件(越沒辨別力),該 term 的 tf-idf 會變小,導致整體「tf-idf 和」變少。
3. 單一 term 出現在被打分數的這篇文章越多次,tf-idf 會變大,導致整體「tf-idf 和」變大。
如果是 request body search,可以打開 `explain:true` 請它列出計算公式與各項 (https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-explain)
另外也有 explain API,explain 結果像這樣:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-explain.html
所以大致上是
1. query 越長、字越多,「各 query term 的 tf-idf 和」會越大。因此,*tf-idf 對不同 query 來說沒有可比性,只能用來比較同一個 search query 底下不同 document 的 relevance score。因為 query length、query 用的字是否有鑑別力,都會影響 _score 的大小*。
2. 單一 term 出現在越多文件(越沒辨別力),該 term 的 tf-idf 會變小,導致整體「tf-idf 和」變少。
3. 單一 term 出現在被打分數的這篇文章越多次,tf-idf 會變大,導致整體「tf-idf 和」變大。
mrorz
23:48:32
Cofacts chatbot 後來其實是
用 elasticsearch 的 more-like-this 抓出前幾名 document 當成 search hit,
然後再另外用其他 string similarity (https://github.com/aceakash/string-similarity)來算 0~1 的相似度。
用 elasticsearch 的 more-like-this 抓出前幾名 document 當成 search hit,
然後再另外用其他 string similarity (https://github.com/aceakash/string-similarity)來算 0~1 的相似度。
GitHub
Finds degree of similarity between two strings, based on Dice's Coefficient, which is mostly better than Levenshtein distance. - aceakash/string-similarity
2020-01-05
tumi
14:08:25
數位時代
有感於媒體因立場取向而經常產出偏頗新聞,台大資工系助理教授陳縕儂用AI架設媒體與時事分析網站「島民衛星」,深度剖析時事新聞,找出不同媒體操作議題手法。
2020-01-06

chihao
01:07:57
對於配色還不是很確定 ._.
fly
18:32:28
gugod
2020-01-06 19:16:44
看來可以直接引用這影片裡提到的「生產標籤」來幫「新聞品質」的下定義了。
新聞與牠們的產地!
julialiu
2020-01-18 03:41:55
他們引用資料的來源,還有用資料的方式it should be data driven, 最好不要引導讀者立場,open end 的方式讓人有思考的空間,記者的問問題的專業度跟人品(在我找到更好字之前先用這字)
gugod
19:16:44
看來可以直接引用這影片裡提到的「生產標籤」來幫「新聞品質」的下定義了。
gugod
19:17:23
gugod
來丟個問題:先不論事實成份多少與立場問題,各位覺得一篇新聞的「製作品質」,該怎麼來定義? (thread)
- Forwarded from #disinfo
- 2019-12-14 18:54:15
pm5
20:06:18
@chihao 開會喔
chihao
20:07:23
來了 \o/
fly
21:54:45
新聞與牠們的產地!
2020-01-07
a-chioh
14:42:15
Hi there
a-chioh
14:44:15
我開始試試看一些Topic Modeling的實驗
chihao
14:46:07
a-chioh++
a-chioh
14:48:03
就會有很多問題^^
a-chioh
14:54:28
not sure about data cleaning/normalizing, and also about proper visualisation for your needs
a-chioh
14:56:01
我在設計一種一天又一天的model
a-chioh
15:12:48
也許我們應該在hackmd開一頁一起寫stop words list
a-chioh
15:17:18
first try, on 12/8, 30 topics the 7 most probable terms for each topic :
```0 0,02689 美國 報導 總統 表示 綜合 政府 川普
1 0,02362 民黨 選人 韓國瑜 總統 國民 國瑜 國民黨
2 0,00844 民眾 表示 提供 提醒 歲以 衛生 呼籲
3 0,08461 沒有 就是 自己 一個 很多 因為 我們
4 0,01998 看新 看新聞 APP 現在用 點我下載 保證天 按我
5 0,01271 外交 民黨 國民 外交部 交部 立委 國民黨
6 0,02905 國家 中國 政府 表示 民主 社會 台灣
7 0,0073 氣溫 中央 天氣 冷氣團 低溫 氣象 氣象局
8 0,00427 其中 作品 下午 表示 當時 為了 真相
9 0,00407 日本 富汗 阿富 阿富汗 人士 政府 表示
10 0,01088 醫療 醫師 醫院 服務 衛福部 衛福 政府
11 0,03221 可能 因此 研究 影響 沒有 指出 需要
12 0,01445 中国 12 国家 2019 发展 可以 工作
13 0,01102 進行 報導 新聞 指出 相關 持續 對於
14 0,02246 中央社 中央 日電 央社 中央社記 中央社記者 新聞資料來源
15 0,04157 表示 活動 舉辦 提供 今年 希望 分享
16 0,01646 版權 版權所有 版權所 社群網 新聞 社群網站 專供
17 0,01027 遊行 香港 分享 聯合 國際 民陣 媒體
18 0,02419 立委 民進黨 民進 支持 進黨 總統 選人
19 0,01516 表示 报道 原标题 12 原标 一个 已经
20 0,02478 自己 演出 粉絲 演唱 台北 演唱會 音樂
21 0,02383 警方 發生 記者 男子 表示 一名 附近
22 0,03561 今年 經濟 市場 表示 成長 明年 目前
23 0,00533 以及 台股 12 指數 市場 美國 分享
24 0,0101 分享 表示 提供 台灣 進行 未來 一個
25 0,00758 表示 台灣 相關 台北 安全 目前 處理
26 0,01733 判決 姓男 萬元 男子 法院 法官 認定
27 0,03029 提供 推出 分享 搭配 使用 記者 設計
28 0,02311 網友 綜合報 綜合報導 綜合 翻攝 翻攝自 臉書
29 0,0179 球隊 比賽 球員 教練 12 記者 分享 ```
```0 0,02689 美國 報導 總統 表示 綜合 政府 川普
1 0,02362 民黨 選人 韓國瑜 總統 國民 國瑜 國民黨
2 0,00844 民眾 表示 提供 提醒 歲以 衛生 呼籲
3 0,08461 沒有 就是 自己 一個 很多 因為 我們
4 0,01998 看新 看新聞 APP 現在用 點我下載 保證天 按我
5 0,01271 外交 民黨 國民 外交部 交部 立委 國民黨
6 0,02905 國家 中國 政府 表示 民主 社會 台灣
7 0,0073 氣溫 中央 天氣 冷氣團 低溫 氣象 氣象局
8 0,00427 其中 作品 下午 表示 當時 為了 真相
9 0,00407 日本 富汗 阿富 阿富汗 人士 政府 表示
10 0,01088 醫療 醫師 醫院 服務 衛福部 衛福 政府
11 0,03221 可能 因此 研究 影響 沒有 指出 需要
12 0,01445 中国 12 国家 2019 发展 可以 工作
13 0,01102 進行 報導 新聞 指出 相關 持續 對於
14 0,02246 中央社 中央 日電 央社 中央社記 中央社記者 新聞資料來源
15 0,04157 表示 活動 舉辦 提供 今年 希望 分享
16 0,01646 版權 版權所有 版權所 社群網 新聞 社群網站 專供
17 0,01027 遊行 香港 分享 聯合 國際 民陣 媒體
18 0,02419 立委 民進黨 民進 支持 進黨 總統 選人
19 0,01516 表示 报道 原标题 12 原标 一个 已经
20 0,02478 自己 演出 粉絲 演唱 台北 演唱會 音樂
21 0,02383 警方 發生 記者 男子 表示 一名 附近
22 0,03561 今年 經濟 市場 表示 成長 明年 目前
23 0,00533 以及 台股 12 指數 市場 美國 分享
24 0,0101 分享 表示 提供 台灣 進行 未來 一個
25 0,00758 表示 台灣 相關 台北 安全 目前 處理
26 0,01733 判決 姓男 萬元 男子 法院 法官 認定
27 0,03029 提供 推出 分享 搭配 使用 記者 設計
28 0,02311 網友 綜合報 綜合報導 綜合 翻攝 翻攝自 臉書
29 0,0179 球隊 比賽 球員 教練 12 記者 分享 ```
chihao
15:17:20
哦可以啊,你要不要就直接開始?😛
chihao
15:18:13
```8461 沒有 就是 自己 一個 很多 因為 我們```
a-chioh
15:18:19
yep
chihao
15:18:23
這個 😆
a-chioh
15:18:30
^^
chihao
15:19:04
a-chioh 之前有跳過其他 g0v 的坑嗎?
a-chioh
15:19:32
我也發現,沒有stopwords 就會出現一個stopword的topic
a-chioh
15:19:43
M0E
chihao
15:20:00
難怪覺得 id 有點眼熟但想不太起來 XD
a-chioh
15:20:03
大部分都是萌典松
a-chioh
15:20:51
可是回去法國之後(三年前)就比較忙別的
a-chioh
15:21:07
所以很久沒有在這裡出現
chihao
15:22:55
我想起來在哪裡看過你的 id 了,2015 年為了某藝術節做展覽的時候有整理過一份貢獻者 id 列表,因為你的 id 是 `a-` 開頭所以排在很前面(第一個?)😆
a-chioh
15:23:45
哈哈哈
tkirby
15:24:30
是說 disinfo 有前端網頁的需求嗎
tkirby
15:25:33
@a-chioh 有要再來台灣嗎 ( 還是已經在台灣了!? )
chihao
15:26:00
我有開始(用比較小的 dataset)試寫一些玩資料的 web 介面,但還沒寫出什麼,所以也還沒 push
a-chioh
15:27:54
我上個月有回來,在台南辦hackathon那天就得回去了......
tkirby
2020-01-07 15:28:19
阿阿~ 太可惜~
chihao
2020-01-07 15:28:39
好可惜 QQ
a-chioh
2020-01-07 15:50:50
我也覺得 T.T
tkirby
15:28:19
阿阿~ 太可惜~
chihao
15:28:39
好可惜 QQ
a-chioh
15:50:50
我也覺得 T.T
hkazami
16:06:42
twreporter.org
炒輿論、帶風向已非新鮮事,但背後是誰源源不絕提供武器?「輿論軍火商」又如何讓各種難核實的訊息送進封閉的人際網絡內?
bruce
17:09:09
想問有人看過這個心理測驗遊戲嗎?最近看到朋友玩,感覺這很像是來偷資料的遊戲

bruce
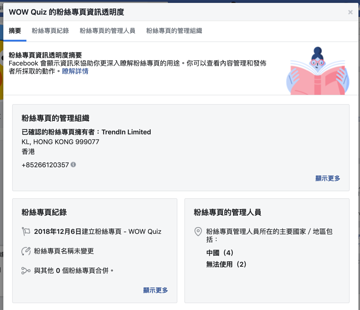
2020-01-07 17:14:51
https://www.facebook.com/WOW-Quiz-1086758181502446/
我看他粉絲頁描述自己成立於2012年,而我看粉絲頁卻是成立於2018/12/6,同時管理員6人,有4人來自中國,2人未知
我看他粉絲頁描述自己成立於2012年,而我看粉絲頁卻是成立於2018/12/6,同時管理員6人,有4人來自中國,2人未知
tumi
2020-01-08 12:22:44
我臉書版面上三不五時可看到(我都忍住不點因為想到劍橋分析)
bruce
17:14:51
https://www.facebook.com/WOW-Quiz-1086758181502446/
我看他粉絲頁描述自己成立於2012年,而我看粉絲頁卻是成立於2018/12/6,同時管理員6人,有4人來自中國,2人未知
我看他粉絲頁描述自己成立於2012年,而我看粉絲頁卻是成立於2018/12/6,同時管理員6人,有4人來自中國,2人未知
2020-01-08
pm5
11:39:27
@fockerlee @ayw255 I left some notes about FB and PTT crawler https://g0v.hackmd.io/@chihao/0archive/https%3A%2F%2Fg0v.hackmd.io%2FlMQO37z6SbWNWo3R4-X_EA
HackMD
# 0archive 零時檔案局 :closed_book: ## 想跳坑嗎 - [跳坑指南](<https://g0v.hackmd.io/cdctnMJWQpKWQYhSxB8sCw>) - [Roadmap](/L1
- 👍1
You might want to check them when you have some time.
bruce
2020-01-08 12:08:46
是關於用url去爬post和comment的時候,會是在同一台機器或不同機器嗎?目前設計我是想同時爬多個post跟comment的url,然後用同一個fb帳號在同一台機器去爬(但直覺好像很容易被fb擋)但還沒想到是否需要用在不同台機器
是關於 url crawler 跟 post/comment content crawler 是同一支程式,還是不同程式
我可能需要知道 url crawler 與 content crawler 它們啟動與結束邏輯的 pseudocode,例如 url crawler 爬到什麼程度時會停下來,而沒爬完的部份以後怎麼辦;content crawler 每次啟動的時候都去 db 找出還沒爬過的 url 來爬,都爬完了就結束,那 content crawler 要多久重新啟動一次?
bruce
2020-01-08 12:18:57
我有在想針對第一次抓的 content(post和comment)是不是改抓 page 的 raw html,然後post 和 comment 直接去解析,而不是再去爬(因為原本是用page 返回的網址清單再去爬 post 和 comment,但實際上返回清單的同時 page 也可以抓到 post 和 comment 的 raw html 了
第二次之後的 content ,就是透過 url 去更新
第二次之後的 content ,就是透過 url 去更新
bruce
2020-01-08 12:19:57
我想一下,我再針對我上面的想法更新一下 pseudo code
bruce
2020-01-08 18:27:32
@pm5 想問兩個問題:
1. 目前 snapshot 的概念,每次都另存一份新的嗎?還是覆蓋舊的?
2. 目前臉書方面,是不是可以先只抓新的 post 和 comment,而之前抓過的 post 或 comment 就不會再去重抓來更新(但抓過的 post 有新的 comment 還是會抓),因為感覺 po 出來的內容好像很少變動
1. 目前 snapshot 的概念,每次都另存一份新的嗎?還是覆蓋舊的?
2. 目前臉書方面,是不是可以先只抓新的 post 和 comment,而之前抓過的 post 或 comment 就不會再去重抓來更新(但抓過的 post 有新的 comment 還是會抓),因為感覺 po 出來的內容好像很少變動
snapshot 是每次都存一份新的;我想可以先不抓已經抓過的 post & comment 的內文更新
pm5
11:39:46
You might want to check them when you have some time.
bruce
12:08:46
是關於用url去爬post和comment的時候,會是在同一台機器或不同機器嗎?目前設計我是想同時爬多個post跟comment的url,然後用同一個fb帳號在同一台機器去爬(但直覺好像很容易被fb擋)但還沒想到是否需要用在不同台機器
pm5
12:10:50
是關於 url crawler 跟 post/comment content crawler 是同一支程式,還是不同程式
pm5
12:15:23
我可能需要知道 url crawler 與 content crawler 它們啟動與結束邏輯的 pseudocode,例如 url crawler 爬到什麼程度時會停下來,而沒爬完的部份以後怎麼辦;content crawler 每次啟動的時候都去 db 找出還沒爬過的 url 來爬,都爬完了就結束,那 content crawler 要多久重新啟動一次?
bruce
12:18:57
我有在想針對第一次抓的 content(post和comment)是不是改抓 page 的 raw html,然後post 和 comment 直接去解析,而不是再去爬(因為原本是用page 返回的網址清單再去爬 post 和 comment,但實際上返回清單的同時 page 也可以抓到 post 和 comment 的 raw html 了
第二次之後的 content ,就是透過 url 去更新
第二次之後的 content ,就是透過 url 去更新
tumi
12:22:44
我臉書版面上三不五時可看到(我都忍住不點因為想到劍橋分析)
chihao
13:42:51
@pm5 @ayw255 @fockerlee 我已經在 g0v #sns 編輯台寫好 0archive 2019/12 工作月報了,希望明天可以從 g0v 粉專發文,請幫忙看看 😄 內容有用到 pm5 做的兩個初步分析,那個怒吼的 publish time 是不是需要再確認,我們抓到的時間跟他網站上顯示的時間不一樣(mouse hover 日期之後會顯示時間)
- 🖖2
- 🙌1
- 1
julialiu
2020-01-18 03:45:40
請問要怎麼訂月報
chihao
13:46:42
上週 disinf0thon 的參與者也有出現在月報文案裡哦 😆
chihao
13:46:54
```2020 年的第一個週六,0archive 專案成員在台北舉辦第零次「不實資訊松」,不同的專業的參與者,包括軟體開發者、行銷、律師、事實查核員、社群經營、記者、寫 NLP 的人、AI(?)、跑者(?),以「g0v 小黑客松」的形式自由提案、展開討論、現場實作,感謝 15 位參與者的熱情參與和貢獻。```
pm5
18:02:13
關於爬蟲的架構,我們也可以在 middle2 上跑 scrapyd 來管理 scraper process,好處是會有些現成的 API 可以監看爬蟲的動態,壞處是我們的臉書爬蟲也要改成 scrapy spider 才能用上這套工具,不然就要維護兩套爬蟲的架構(跟現在的情況差不多啦) https://scrapyd.readthedocs.io/en/stable/
- 🙌2
bruce
18:27:32
@pm5 想問兩個問題:
1. 目前 snapshot 的概念,每次都另存一份新的嗎?還是覆蓋舊的?
2. 目前臉書方面,是不是可以先只抓新的 post 和 comment,而之前抓過的 post 或 comment 就不會再去重抓來更新(但抓過的 post 有新的 comment 還是會抓),因為感覺 po 出來的內容好像很少變動
1. 目前 snapshot 的概念,每次都另存一份新的嗎?還是覆蓋舊的?
2. 目前臉書方面,是不是可以先只抓新的 post 和 comment,而之前抓過的 post 或 comment 就不會再去重抓來更新(但抓過的 post 有新的 comment 還是會抓),因為感覺 po 出來的內容好像很少變動
2020-01-09
pm5
11:31:28
看 log 最近幾個小時好像都沒有抓到東西...
chihao
11:31:53
。w。
chihao
11:32:44
幫 tag @ayw255 @fockerlee
bruce
11:41:48
我還沒放上去,所以不會有log
wenyi
12:16:42
咦我看看
wenyi
12:41:44
看起來是跟Multiprocess有關
https://stackoverflow.com/questions/31087268/multiprocessing-of-scrapy-spiders-in-parallel-processes
https://stackoverflow.com/questions/31087268/multiprocessing-of-scrapy-spiders-in-parallel-processes
Stack Overflow
There as several similar questions that I have already read on Stack Overflow. Unfortunately, I lost links of all of them, because my browsing history got deleted unexpectedly. All of the above
pm5
13:19:10
看來我們還是改用 Twisted 做多工比較不會有問題 🤔
pm5
13:22:52
Scrapy 可以在一個 crawler process 裡跑多個 spider https://docs.scrapy.org/en/1.8/topics/practices.html#running-multiple-spiders-in-the-same-process,我們可能可以改成開很多 spider 放進同一個 CrawlerRunner 裡去跑,Twisted 應該會處理多工
之前我想說多跑幾個 process 應該也可以,沒想到會這樣。上面的錯誤訊息看起來可能是多個 subprocess 在搶同一個 port。
pm5
13:31:17
之前我想說多跑幾個 process 應該也可以,沒想到會這樣。上面的錯誤訊息看起來可能是多個 subprocess 在搶同一個 port。
chun
21:31:49
@yuchunlin33 has joined the channel
2020-01-10
moneycat2128
22:49:44
@moneycat2128 has joined the channel
2020-01-12
pm5
11:59:07
I stopped automatic article discovery two days ago to manually test the new parallel crawler with twisted. The parallel crawling part works fine, but there seems to be some smaller problems with the crawler itself.
1) Some links to line.me and linkedin were also crawled. This is probably because of the URL parameters in the link, for example http://line.me/R/msg/text/?14%E9%96%93%E5%85%A8%E7%90%83%E6%9C%80%E5%A5%87%E6%80%AA%E7%9A%84%E9%A3%AF%E5%BA%97%EF%BC%8C%E5%8F%AA%E7%B5%A6%E5%96%9C%E6%AD%A1%E6%96%B0%E9%AE%AE%E6%84%9F%E7%9A%84%E5%86%92%E9%9A%AA%E5%AE%B6%E9%81%8A%E5%AE%A2%EF%BC%81%0D%0Ahttps://www.teepr.com/50197/jasonhuang/%e7%9b%a4%e9%bb%9e%e5%85%a8%e7%90%8314%e9%96%93%e6%9c%80%e7%8d%a8%e6%a8%b9%e4%b8%80%e6%a0%bc%e7%9a%84%e9%a3%af%e5%ba%97%ef%bc%8c%e5%85%b6%e4%bb%96%e4%b8%80%e8%88%ac%e7%9a%84%e9%a3%af%e5%ba%97%e5%ae%8c/ We can fix this by fixing the article link patterns we have.
2) Somehow the crawler went back a lot further than it did before, in some cases retrieved articles on for example China Times as far back as 2017, which ... isn't really a bad thing. But it just took too long and we can't do this again in the next run.
The code is in `new_discover.py` in the master branch.
wenyi
2020-01-13 10:16:07
@pm5 I had the spider to “follow” links on the article pages on the PTT branch that merged last Thursday (and set default depth to 5 to complement), the previous spider does not follow article pages but only category tabs or “next pages”; I think this is the reason why the crawler went a lot further
wenyi
2020-01-13 10:16:41
should we set it back then?
It may be that, but I think the main reason is a bug I introduced, so that the spiders disregard the default depth. I am testing a fix now.
pm5
12:01:17
1) Some links to line.me and linkedin were also crawled. This is probably because of the URL parameters in the link, for example http://line.me/R/msg/text/?14%E9%96%93%E5%85%A8%E7%90%83%E6%9C%80%E5%A5%87%E6%80%AA%E7%9A%84%E9%A3%AF%E5%BA%97%EF%BC%8C%E5%8F%AA%E7%B5%A6%E5%96%9C%E6%AD%A1%E6%96%B0%E9%AE%AE%E6%84%9F%E7%9A%84%E5%86%92%E9%9A%AA%E5%AE%B6%E9%81%8A%E5%AE%A2%EF%BC%81%0D%0Ahttps://www.teepr.com/50197/jasonhuang/%e7%9b%a4%e9%bb%9e%e5%85%a8%e7%90%8314%e9%96%93%e6%9c%80%e7%8d%a8%e6%a8%b9%e4%b8%80%e6%a0%bc%e7%9a%84%e9%a3%af%e5%ba%97%ef%bc%8c%e5%85%b6%e4%bb%96%e4%b8%80%e8%88%ac%e7%9a%84%e9%a3%af%e5%ba%97%e5%ae%8c/ We can fix this by fixing the article link patterns we have.
social-plugins.line.me
Let users see your website through LINE. The LINE it! Button can be installed on smartphone website and apps.
pm5
12:03:25
2) Somehow the crawler went back a lot further than it did before, in some cases retrieved articles on for example China Times as far back as 2017, which ... isn't really a bad thing. But it just took too long and we can't do this again in the next run.
pm5
12:04:39
The code is in `new_discover.py` in the master branch.
2020-01-13
julian07027
09:25:28
@julian07027 has joined the channel
wenyi
10:16:07
@pm5 I had the spider to “follow” links on the article pages on the PTT branch that merged last Thursday (and set default depth to 5 to complement), the previous spider does not follow article pages but only category tabs or “next pages”; I think this is the reason why the crawler went a lot further
wenyi
10:16:41
should we set it back then?
pm5
11:16:30
It may be that, but I think the main reason is a bug I introduced, so that the spiders disregard the default depth. I am testing a fix now.
pm5
11:28:48
發現我們會抓自由時報的 print 版
wenyi
2020-01-13 11:52:35
喔喔!我來改一下article的pattern
wenyi
2020-01-13 11:59:22
改好airtable & 更新到db了,應該不會再抓到/print
pm5
11:29:02
https://news.ltn.com.tw/news/politics/breakingnews/3038253/print 與 https://news.ltn.com.tw/news/politics/breakingnews/3038253 都會抓一份
自由電子報
民進黨第三選區提名人吳怡農昨天落選,卻有大批民眾鼓勵他選市長,吳怡農今天表示,敗選人應該在隔天沒有資格談市長,希望大家給他多一點時間沉澱。被問起未來下一步為何、是否選台北市長,吳怡農表示,敗選人應該在隔天沒有資格談市長,但希望大家給他多一點時間沉澱、思考下一步要怎麼做。吳說,如果選舉當天被問起未來規劃,他會講接下來四年在國會的計畫,但事情變得非常快,他也說,四個月前他連要在哪區選舉都不知道,現在最重要的是大家給他一些時間,他會盡快與大家報告。
wenyi
11:52:35
喔喔!我來改一下article的pattern
wenyi
11:59:22
改好airtable & 更新到db了,應該不會再抓到/print
wenyi
12:00:09
話說proxy ip 好像 (暫時?) 被kknews擋了,可能剛剛一次抓太多,晚上再來試試是不是一樣被擋
2020-01-14
pm5
08:09:30
@ronnywang 最近又抓了不少文章,先問一下硬碟空間還有多少?爬蟲有些問題要再修一下,之後應該可以砍掉一些不需要抓的東西
pm5
08:15:25
@chihao @ayw255 @fockerlee 昨天沒有排這禮拜的工作。大家記得自己到 meeting notes 寫自己這禮拜要做什麼,還有看一下這個月的計劃要不要修改喔。
- 1
bruce
08:55:09
好
chihao
09:18:27
好 \o/
wenyi
09:57:26
好!
chihao
12:41:49
\o/ @fockerlee @ayw255 ++
hcchien
15:17:43
呼叫所有科技人,聯手對抗不實資訊!AIT很高興在此宣布「美台科技挑戰賽」即將開跑!「美台科技挑戰賽」是一項由美國國務院贊助的公開競賽,邀請所有科技人一起展示對抗政治宣傳和不實資訊的技術!這場為期兩天的挑戰賽將於2020年2月19日至20日在台北舉行,目標為展現並支持有助於相關人士了解、揭露並抗衡不實資訊和政治宣傳的科技解決方案。「美台科技挑戰賽」由AIT及美國國務院全球參與中心(GEC)共同主辦,...
 2
2
2020-01-15
chihao
08:55:12
@ayw255 db 裡既有的 `Article` 我已經把屬於 Ptt 的文章類別改成 `PTT` 囉,用 `site_id` 來判斷的
tkirby
17:09:59
@julian07027 Kirby!
ronnywang
17:10:22
@tkirby Ronny!
tkirby
17:10:49
@julian07027 的頭像是Kirby
chihao
17:10:57
@ronnywang chihao!
chihao
17:11:06
可惡慢了
chihao
18:25:41
@pm5 @ayw255 @fockerlee 因為這週六 cowork,下週一再 meeting 是不是時間太近了?如果覺得會,我提議改成 1/22 週三,也許可以約實體見面?詢問三位的意見。
2020-01-16
a-chioh
23:42:08
嗨!
a-chioh
23:42:50
我繼續(亂?)玩topic modeling
2020-01-17
a-chioh
00:04:34
(just a draft I'm not sure how robust is RShiny for this kind of public use)
a-chioh
00:06:08
用一天 (2978文章)
a-chioh
00:08:16
(用"box select"或"lasso select"就可以看到文章,也可是把topics 刪掉,刪掉後topic space 就被重新算出來)
Jerry
01:48:37
@jerryhophy has joined the channel
a-chioh
16:32:05
也許應該找一段時間討論我可以怎麼幫忙
a-chioh
16:32:40
因為無法參加hackathon,我不太清楚
2020-01-18
julialiu
03:41:55
他們引用資料的來源,還有用資料的方式it should be data driven, 最好不要引導讀者立場,open end 的方式讓人有思考的空間,記者的問問題的專業度跟人品(在我找到更好字之前先用這字)
- 👍1
julialiu
03:45:40
請問要怎麼訂月報
chihao
12:53:27
好啊來 hangout @a-chioh @pm5 農曆年後如何?😆 @a-chioh 在哪個時區?
- ✔️1
a-chioh
2020-01-18 16:20:24
😄 UTC+1 (西歐)
pm5
16:05:38
 陳清波(1949年-),法號三元,是台灣的風水師,《精靈寶可夢GO》玩家,因同時以數十台手機遊玩《精靈寶可夢GO》聞名。 陳清波出身台南六甲,原本家境不錯,後來因為屢遭天災,家道中落,便因此失學。他孩童時期做過放牛、洗衣煮飯、砍柴、賣芋頭冰、舞龍舞獅等工作。在29歲時,陳清波和父親、弟弟一起在三重的工地從事建築工作,因吊索負重過重而斷裂,意外把他從八樓甩到地下室,身受重傷。陳清波表示自己因此躺在床上40天,並休養了一年,他認為自己大難不死,必須救人,因此到宮廟裡拜師學習風水,成為道教法師。陳三元在孫子的介紹下接觸《精靈寶可夢GO》,並在2016年9月14日開始玩。某日他在腳踏車上安裝了9支手機並同時遊玩的舉動被路人拍下,照片被上傳至網路上後爆紅,還登上美國網路論壇Reddit,讓陳三元成為網路名人,並被稱為「寶可夢阿伯」。2018年6月,他被遊戲網站exp.gg在新北市土城區發現行蹤,受到媒體大幅報導,他表示,如果不需接客,則會出外遊玩《精靈寶可夢GO》。 之後,他的腳踏車上安裝了更多手機,到2019年3月時已安裝22支,同年8月時擴展到42支,9月中秋節後擴展到45支,而腳踏車前的菜籃裡則是數顆工業用的電池。陳三元每天通常會花四個小時以上在玩《精靈寶可夢GO》,有時還會玩到凌晨四點,遊玩動機是預防阿茲海默症。他原本只玩一支手機,入迷之後添購了十多支手機,並特地改裝電池,增加可以在外遊玩的時間,這些手機除了遊玩《精靈寶可夢GO》,沒有其它用途,而這些裝備可以從腳踏車上拆卸下來,裝上背帶後背在身上。由於手機很多,陳三元不時會忘記繳費。陳三元在網路爆紅後除了引起媒體採訪,還在2019年取代了韓國演員孔劉,接下華碩新款手機ZenFone Max Pro (M2)的代言。
陳清波(1949年-),法號三元,是台灣的風水師,《精靈寶可夢GO》玩家,因同時以數十台手機遊玩《精靈寶可夢GO》聞名。 陳清波出身台南六甲,原本家境不錯,後來因為屢遭天災,家道中落,便因此失學。他孩童時期做過放牛、洗衣煮飯、砍柴、賣芋頭冰、舞龍舞獅等工作。在29歲時,陳清波和父親、弟弟一起在三重的工地從事建築工作,因吊索負重過重而斷裂,意外把他從八樓甩到地下室,身受重傷。陳清波表示自己因此躺在床上40天,並休養了一年,他認為自己大難不死,必須救人,因此到宮廟裡拜師學習風水,成為道教法師。陳三元在孫子的介紹下接觸《精靈寶可夢GO》,並在2016年9月14日開始玩。某日他在腳踏車上安裝了9支手機並同時遊玩的舉動被路人拍下,照片被上傳至網路上後爆紅,還登上美國網路論壇Reddit,讓陳三元成為網路名人,並被稱為「寶可夢阿伯」。2018年6月,他被遊戲網站exp.gg在新北市土城區發現行蹤,受到媒體大幅報導,他表示,如果不需接客,則會出外遊玩《精靈寶可夢GO》。 之後,他的腳踏車上安裝了更多手機,到2019年3月時已安裝22支,同年8月時擴展到42支,9月中秋節後擴展到45支,而腳踏車前的菜籃裡則是數顆工業用的電池。陳三元每天通常會花四個小時以上在玩《精靈寶可夢GO》,有時還會玩到凌晨四點,遊玩動機是預防阿茲海默症。他原本只玩一支手機,入迷之後添購了十多支手機,並特地改裝電池,增加可以在外遊玩的時間,這些手機除了遊玩《精靈寶可夢GO》,沒有其它用途,而這些裝備可以從腳踏車上拆卸下來,裝上背帶後背在身上。由於手機很多,陳三元不時會忘記繳費。陳三元在網路爆紅後除了引起媒體採訪,還在2019年取代了韓國演員孔劉,接下華碩新款手機ZenFone Max Pro (M2)的代言。
- 2
2020-01-20
Mee
14:27:13
@mee has joined the channel
Sigrid Jin
15:21:48
@hophfg has joined the channel
fluidto
16:23:16
@kjh.appro has joined the channel
2020-01-21
ichieh
14:31:18
@chiehg0v has joined the channel
ichieh
14:31:42
嗨 disinfo 的大家,我是 g0v 揪松團的以婕,揪松團在 2020/02/02 (Sun.)預計要舉辦一場坑主小聚(坑抗 Keng of Conf),活動採邀請制,需要統計一下每個坑要給幾個邀請碼,報名收單時間為 1/29 中午 12:00 前,再麻煩想參加的朋友填寫 google 表單。
邀請碼索取表單:http://bit.ly/kenginvite
坑抗共筆:https://g0v.hackmd.io/@jothon/confkeng2020
邀請碼索取表單:http://bit.ly/kenginvite
坑抗共筆:https://g0v.hackmd.io/@jothon/confkeng2020
Google Docs
活動時間:2020/02/02 (日) 14:00 - 18:00 地點:登記完成後的 Email 會說明,注意:未登記請勿參加小聚 坑主小聚共筆:<https://g0v.hackmd.io/@jothon/confkeng2020> KKTIX 活動報名頁面:<https://g0v-jothon.kktix.cc/events/kengconf01> 本活動採邀請制,邀請碼收單時間為 1/29(三)初五 中午(12:00)。 若有任何問題請於 g0v Slack @ichieh @bess,謝謝。
2020-01-22
pm5
18:04:57
@fockerlee 我測試 fb scraper 的時候,它跑完好像不會關掉 chrome process。你那邊測試也是這樣嗎?現在測試的時候,每次 update 大概會跑多久?
bruce
18:37:06
目前是跑完,還是讓chrome留著,讓下一個cron可以接續用,所以沒有關掉,目前update 是設定一小時跑一次,這兩天cron跑下來,情形說沒有辦法全部ㄧ次在一小時內跑完
ronnywang
18:40:10
以 middle2 的架構 每次 cron 都是獨立的 docker ,所以把 chrome 留下來不會有節省時間的效果 反而會讓 middle2 認為這隻 cron 還沒跑完不會釋放資源
ronnywang
18:41:23
如果要重覆用資源的話,要用 worker 來做,worker 就是永遠都跑不完的 process
- 🙌2
- ❤️1
bruce
2020-01-29 13:54:13
想問那 worker 的 log 會建議從哪裡看?
ronnywang
2020-01-29 15:30:22
先不要用 worker 好了 XD 目前 middle2 worker 應該還很不成熟 XD (因為過去都沒人用)
bruce
2020-01-29 18:37:15
好
bruce
2020-01-29 18:50:16
那想另外問的是,我嘗試 cron 去另外寫入到指定的 log 檔案供後續的 cron 使用,另如第一次 cron 寫入到 a.log,然後第二次跑 cron 會去找 a.log 來做一些判斷,但好像會找不到,有可能是怎樣的原因嗎?
ronnywang
2020-01-29 19:13:16
每個 cron 都是獨立的 docker 和檔案系統,如果你有想要共同存取的資料,應該要用 database 而不是用檔案
bruce
2020-01-29 21:40:32
好
jiwoo
22:35:49
@jiiw.kang has joined the channel
2020-01-23
skygamer
22:50:43
@skygamer has joined the channel
skygamer
23:06:28
不曉得美玉姨或事實查核的團隊有沒有在這裡。
我看之前有人分享過AIT的「美台科技挑戰賽」,他這個很適合現成的產品參賽,審核資料後選8組團隊參加(2月19日20日兩天),最後前三名分別有5萬、10萬、25萬的獎金(美金),報名時間到明天晚上截止。
祝你們順利奪魁!
我看之前有人分享過AIT的「美台科技挑戰賽」,他這個很適合現成的產品參賽,審核資料後選8組團隊參加(2月19日20日兩天),最後前三名分別有5萬、10萬、25萬的獎金(美金),報名時間到明天晚上截止。
祝你們順利奪魁!
- 🙏1
2020-01-29
bruce
13:54:13
想問那 worker 的 log 會建議從哪裡看?
ronnywang
15:30:22
先不要用 worker 好了 XD 目前 middle2 worker 應該還很不成熟 XD (因為過去都沒人用)
bruce
18:37:15
好
bruce
18:50:16
那想另外問的是,我嘗試 cron 去另外寫入到指定的 log 檔案供後續的 cron 使用,另如第一次 cron 寫入到 a.log,然後第二次跑 cron 會去找 a.log 來做一些判斷,但好像會找不到,有可能是怎樣的原因嗎?
ronnywang
19:13:16
每個 cron 都是獨立的 docker 和檔案系統,如果你有想要共同存取的資料,應該要用 database 而不是用檔案
bruce
21:40:32
好
2020-01-30
pm5
15:38:45
@chihao @ayw255 @fockerlee 我整理了一些 data pipeline 進一步的需求在 https://g0v.hackmd.io/@chihao/0archive/%2FL1l9m6joRhCWhmGFZYAO5A
# 0archive 零時檔案局 :closed_book: ## 想跳坑嗎 - [跳坑指南 Intro](/cdctnMJWQpKWQYhSxB8sCw) - [Roadmap & Task Tracker](/L1
看你們覺得怎麼樣,下次 devs meeting 討論一下?
chihao
2020-01-30 18:23:42
pm5++ 列入討論事項
chihao
18:23:42
pm5++ 列入討論事項