#disinfo
2019-12-01
bruce
16:47:20
gogogo
pm5
19:03:28
`batch_discover.py` now runs daily on middle2.
pm5
19:04:22
There are some problems with duplicated article url hash. Here is the log: https://middle2.com/project/cronlog/tainan-sun-500796
2019-12-02
wenyi
05:00:19
wenyi
05:20:39
有發現針對一些website (e.g. 中國台灣網& udn) 會有這些錯誤,但還不太知道為什麼QQ 至少他不會被送進db
pm5
17:32:29
we can start discussing what kind of dataset can we put together before the hackathon? data visualization would probably the easiest way for ppl to contribute.
- 🙌1
chihao
20:01:30
@fockerlee there is a link to hangout in your google calendar 🙂
bruce
20:03:02
oh
chihao
20:05:38
@fockerlee 需要連結嗎?
bruce
20:06:34
我點了,但他顯示有錯誤,我在嘗試另外一個瀏覽器
chihao
20:06:41
OK

chihao
20:50:12
2019-12-04
pm5
11:38:31
@fockerlee @ayw255 @chihao updated db schema for FB posts & comments https://g0v.hackmd.io/lMQO37z6SbWNWo3R4-X_EA?view#%E8%B3%87%E6%96%99%E5%BA%AB%E6%9E%B6%E6%A7%8B
- ❤️2
主要幾個安排:FB posts & comments 都是 Article(它們都有 url),用 article_type 區分;抓下來的內容放在 FacebookPostSnapshot or FacebookCommentSnapshot;按讚數等等資料存在 reactions JSON column
看一下感覺怎麼樣?
chihao
2019-12-04 11:54:22
看看
chihao
2019-12-04 11:59:39
1. FacebookPostSnapshot → FbPostSnapshot 覺得讓他短一點
2. 感覺沒問題,但隱約覺得 comment 的 snapshot 好像可以綁在 article snapshot,不用獨立,不確定,想討論
2. 感覺沒問題,但隱約覺得 comment 的 snapshot 好像可以綁在 article snapshot,不用獨立,不確定,想討論
wenyi
2019-12-05 00:14:33
comment snapshot因為有回覆哪一篇文章以及reaction等有別於article的架構, 可能獨立出來會比較好
這讓我想到我們也可以搜集大眾新聞網站下面的留言,存在類似的架構中,以及之後youtube影片下面的留言
這讓我想到我們也可以搜集大眾新聞網站下面的留言,存在類似的架構中,以及之後youtube影片下面的留言
bruce
2019-12-05 02:12:20
我也覺得 comment 感覺獨立出另一個 table 比較方便。方便了解是屬於哪篇文章(post)下的留言,透過每個comment有一個 article_id,來知道屬於哪一篇article。如果comment跟article放在同一個table,感覺不容易分辨從屬關係。
我也覺得 comment snapshot 分開比較好(當然)。不過 comment snapshot 的 article_id 是這個 comment 的 id。reply_to 才是指向它回覆的那一篇。而且 FB comment 可以是回覆另一個 comment,所以 reply_to 所指向的另一個 Article 可能也是個 FB comment,要看 Article.article_type 決定
可能還是看我們蒐集資料的對象吧。假訊息主要出現在 post 還是 comment?如果 comment 也是常見傳播假訊息的管道之一,那獨立出來比較好。當然如果要 post & comment 綁在一起的,這也可以在後面的 pipeline 做。
pm5
11:42:43
主要幾個安排:FB posts & comments 都是 Article(它們都有 url),用 article_type 區分;抓下來的內容放在 FacebookPostSnapshot or FacebookCommentSnapshot;按讚數等等資料存在 reactions JSON column
pm5
11:43:05
看一下感覺怎麼樣?
chihao
11:54:22
看看
chihao
11:59:39
1. FacebookPostSnapshot → FbPostSnapshot 覺得讓他短一點
2. 感覺沒問題,但隱約覺得 comment 的 snapshot 好像可以綁在 article snapshot,不用獨立,不確定,想討論
2. 感覺沒問題,但隱約覺得 comment 的 snapshot 好像可以綁在 article snapshot,不用獨立,不確定,想討論
poga
16:10:05
0archive 有要爬主流新聞媒體嗎?
poga
16:15:07
看到 airtable 了,看起來是有爬
wenyi
2019-12-04 23:58:22
嗚喔 有在爬~
wenyi
2019-12-04 23:59:14
目前有爬airtable上看到的那幾個site,除了蘋果新聞網(蘋果即時有,新聞網還沒)
wenyi
23:57:31
`drop_unused` merged with branch `master` — ‘init_site.py’ is dropped from repo
wenyi
23:58:22
嗚喔 有在爬~
wenyi
23:59:14
目前有爬airtable上看到的那幾個site,除了蘋果新聞網(蘋果即時有,新聞網還沒)
2019-12-05
wenyi
00:14:33
comment snapshot因為有回覆哪一篇文章以及reaction等有別於article的架構, 可能獨立出來會比較好
這讓我想到我們也可以搜集大眾新聞網站下面的留言,存在類似的架構中,以及之後youtube影片下面的留言
這讓我想到我們也可以搜集大眾新聞網站下面的留言,存在類似的架構中,以及之後youtube影片下面的留言
bruce
02:12:20
我也覺得 comment 感覺獨立出另一個 table 比較方便。方便了解是屬於哪篇文章(post)下的留言,透過每個comment有一個 article_id,來知道屬於哪一篇article。如果comment跟article放在同一個table,感覺不容易分辨從屬關係。
pm5
09:08:15
我也覺得 comment snapshot 分開比較好(當然)。不過 comment snapshot 的 article_id 是這個 comment 的 id。reply_to 才是指向它回覆的那一篇。而且 FB comment 可以是回覆另一個 comment,所以 reply_to 所指向的另一個 Article 可能也是個 FB comment,要看 Article.article_type 決定
pm5
11:24:27
@ronnywang 我們現在 db 用掉多少硬碟空間啦?
ronnywang
11:25:03
我等等中午看看,應該是還沒佔多少…如果硬碟吃到 70% 以上我會收到警告信
ronnywang
12:51:32
目前用了 20G
ronnywang
12:51:41
主要都是 ArticleSnapshot
ronnywang
12:52:51
我把 ArticleSnapshot 啟動壓縮看看
ronnywang
12:59:53
我之前 newsdiff 的 raw html 只會保留三個月,因為原始 HTML 量真的會太多,但會永久保留解出來的title 和 body 資訊
pm5
13:01:29
Snapshot 也是件麻煩事。我之前看了一下,應該有很多文章重新 snapshot 但是文章內容其實沒有改變,改變的是 sidebar 裡最新文章列表這一類的資料。
ronnywang
13:02:35
newsdiff 那邊是解出 title, body ,title, body 有變才會存新的 snapshot
ronnywang
13:02:48
但是要 title body 就要針對每個網站都要寫 parser
ronnywang
13:03:18
現在已經收集了不少 snapshot 了,可以來實驗看看 readability 解 title, body 的效果了?
ronnywang
13:05:35
snapshot 的部份我在 newsdiff 是一個月存一個 table ,然後超過三個月就 drop table
ronnywang
13:05:47
壓縮完了,剩 5.6G
ronnywang
13:15:20
現在的資料量也可以大概預估硬碟成長量需求了?
ronnywang
13:17:01
目前 disinfo 專案在 middle2 上面的 mysql 硬碟空間還剩 40G ,但到 80% 時我就會處理加大空間了,所以 disinfo 大概還可以多用 25G 左右是我可以先不管他的
ronnywang
13:17:32
等到用到 25G 時,我們就要討論把 disinfo 獨立一台資料庫了
pm5
13:22:31
粗估一下大約可以用到⋯⋯12 月底?
pm5
13:23:33
readability 夠好的話就可以多撐很久
ronnywang
13:24:12
snapshot 的部份也可以實驗看看戳 archive.org 讓他們那邊來存
pm5
13:24:19
不然也可以發佈兩個禮拜以上的 Article 就停止 snapshot
ronnywang
13:24:44
現在 Article 會每天都 snapshot 沒設定停止日期?
pm5
13:26:31
應該沒有。也才剛開始每天跑,一個禮拜左右
ronnywang
13:27:23
如果沒設 snapshot 日期,這樣用量不是會 O(N^2) 成長 XD
pm5
13:29:01
喔,現在一篇文章最多 snapshot 7 次
wenyi
13:29:27
我有已經寫了一版解title, body 但不是用readability,所以需要每一個site存一個css selector for main text body。readability 的部分 我有看python api (https://github.com/buriy/python-readability) 但是基本上解不出來body
GitHub
fast python port of arc90's readability tool, updated to match latest readability.js! - buriy/python-readability
@ayw255 你遇到解不出來 body 的情況是怎麼樣?我今天試了一下,他有點 unicode 的問題,修掉以後我試了幾篇爬下來的文章,看起來可以解出還不錯的 body
wenyi
2019-12-09 08:01:15
@pm5 👍👍可以了,把parser更新成使用你forked的這個readability了,結果看起來不錯,明天討論一下資料要存哪裡
wenyi
13:30:19
新的code在branch `parse_article`
ronnywang
13:31:17
有的網站很討厭,會把廣告版位塞在 main text body 中,造成每次抓因為廣告不同而 main text 不同
ronnywang
13:31:23
但是其實文章沒變
ronnywang
13:40:09
另外之前 table name 好像是用第一個字大寫,像是 Article ,不過習慣上好像 table name 都會用小寫
像是 ArticleSnapshot 在 table name 會用 article_snapshot ,在程式的 class name 才用 ArticleSnapshot
像是 ArticleSnapshot 在 table name 會用 article_snapshot ,在程式的 class name 才用 ArticleSnapshot
- 😆1
chihao
14:15:22
來準備一下等一下發訊息
chihao
14:16:03
視訊工具的話,如果選 jitsi 不知道進入門檻會不會太高?
hcchien
14:47:23
@hcchien407 has joined the channel
deeper
15:14:00
@cstsai has joined the channel
yukai
17:13:25
@yukai has joined the channel
ael
17:39:48
@aelcenganda has joined the channel
kiwi
19:10:52
@auroral.13king518 has joined the channel
loooffy
19:42:45
@loooffy has joined the channel
cwkung2016
20:08:02
@cwkung2016 has joined the channel
2019-12-06
Anping
02:19:04
@zhaoanping has joined the channel
pm5
11:17:18
可能還是看我們蒐集資料的對象吧。假訊息主要出現在 post 還是 comment?如果 comment 也是常見傳播假訊息的管道之一,那獨立出來比較好。當然如果要 post & comment 綁在一起的,這也可以在後面的 pipeline 做。
2019-12-07
fly
15:41:28
> 與真人用戶不同,假帳號可能由一個人或一個集團控制,他們通常一起行動,一部分人負責發出宣傳訊息或者假消息,其他人贊同然後轉發,合成一個消息動向,吸引真人用戶加入網絡討論。
> BotSlayer 的系統收集所有符合這些條件的推文,然後儲存到一個數據庫,以供日後偵查。此外,它還連結到 Hoaxy 系統,可以得知 Twitter 帳號在一段時間內的互動情況,辨識最有影響力以及最有可能散播假消息的帳號。
<https://www.cup.com.hk/2019/12/03/botslayer-the-system-aims-to-find-and-kill-internet-bots/>
<https://osome.iuni.iu.edu/tools/botslayer/>
> BotSlayer 的系統收集所有符合這些條件的推文,然後儲存到一個數據庫,以供日後偵查。此外,它還連結到 Hoaxy 系統,可以得知 Twitter 帳號在一段時間內的互動情況,辨識最有影響力以及最有可能散播假消息的帳號。
<https://www.cup.com.hk/2019/12/03/botslayer-the-system-aims-to-find-and-kill-internet-bots/>
<https://osome.iuni.iu.edu/tools/botslayer/>
*CUP
由電腦系統操縱的假帳號(bot)干擾言論自由、帶動政治宣傳風向的普遍現象,日益引起美國互聯網研究員的關注,美國印第安納大學兩位博士生研發出 Botslayer 軟件系統,專門為媒體記者和公眾討論區服務,幫助他們找出網絡假帳號大軍,清理門戶。
 1
1
2019-12-08
LoraC
17:36:18
@shadowcrow594 has joined the channel
pm5
22:25:17
@ayw255 你遇到解不出來 body 的情況是怎麼樣?我今天試了一下,他有點 unicode 的問題,修掉以後我試了幾篇爬下來的文章,看起來可以解出還不錯的 body
pm5
22:25:35
要修掉一個 unicode 的問題:https://github.com/pm5/python-readability/commit/8e1f4ceb6af9dc7794ec7169fae8923565f73998
fast python port of arc90's readability tool, updated to match latest readability.js! - pm5/python-readability
2019-12-09
chihao
19:50:23
@pm5 @ayw255 @fockerlee 再十分鐘 dev meeting 😄
kiang
21:40:04
@kiang has joined the channel
2019-12-10
gugod
23:06:53
https://metacpan.org/source/GUGOD/NewsExtractor-v0.0.3/lib/NewsExtractor/Extractor.pm#L21
我開始漸漸將 CSS 規則加入自己做的爬蟲 NewsExtractor.pm 了
打算先依網址區別,一個站做一組 CSS 規則。
用來對付那些無法以 Readibility 演算法處理的網站。
我開始漸漸將 CSS 規則加入自己做的爬蟲 NewsExtractor.pm 了
打算先依網址區別,一個站做一組 CSS 規則。
用來對付那些無法以 Readibility 演算法處理的網站。
gugod
23:09:48
公眾人物新聞的追蹤. Contribute to g0v/people-in-news development by creating an account on GitHub.
2019-12-11
gugod
08:43:58
Contribute to perltaiwan/NewsExtractor development by creating an account on GitHub.
pei
15:11:11
@stronghead.wu has joined the channel
pofeng
16:34:39
@pofeng has joined the channel
Can
17:12:48
@can has joined the channel
gugod
20:11:33
剛發現 chinatimes.com 的新聞網頁 DOM 中有 JSON-LD 資料可以利用
- ㊙️3
gugod
2019-12-11 20:12:19
長得像這樣
``` <script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"articleSection": "生活",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.chinatimes.com/realtimenews/20191211004429-260405"
},
"headline": "作曲、繪畫難不倒 AI也能玩藝術",
"image": {"@type": "ImageObject","url":"https://images.chinatimes.com/newsphoto/2019-12-11/900/20191211004430.jpg","height":369,"width":656},"author": {"@type": "Person","name": "王寶兒" }, "url":"https://www.chinatimes.com/realtimenews/20191211004429-260405",
"description":"王寶兒/新北報導紀錄片《AI新紀元》揭示,預計203...
....
</script>```
``` <script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"articleSection": "生活",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.chinatimes.com/realtimenews/20191211004429-260405"
},
"headline": "作曲、繪畫難不倒 AI也能玩藝術",
"image": {"@type": "ImageObject","url":"https://images.chinatimes.com/newsphoto/2019-12-11/900/20191211004430.jpg","height":369,"width":656},"author": {"@type": "Person","name": "王寶兒" }, "url":"https://www.chinatimes.com/realtimenews/20191211004429-260405",
"description":"王寶兒/新北報導紀錄片《AI新紀元》揭示,預計203...
....
</script>```
gugod
2019-12-11 20:12:38
而且 “description” 欄基本上就是新聞全文了….
gugod
2019-12-12 08:20:30
自由時報也有。但 description 不是全文,並且 “author.name” 不是記者名,而是「自由時報」四個字
view-source:https://news.ltn.com.tw/news/society/breakingnews/3006341
view-source:https://news.ltn.com.tw/news/society/breakingnews/3006341
gugod
2019-12-12 08:21:50
嗯。看來就是 Slack 抓到的這一段字。(或許 Slack 就 是抓 `script[type="application/ld+json"]` )
gugod
2019-12-12 08:22:21
喔,也有可能是 og:title + og:description
ctwant.com 也有,果然是同一家的
其實 Nooho 也有。從這裡抓 datePublished 可能是個好辦法
gugod
20:12:19
長得像這樣
``` <script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"articleSection": "生活",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.chinatimes.com/realtimenews/20191211004429-260405"
},
"headline": "作曲、繪畫難不倒 AI也能玩藝術",
"image": {"@type": "ImageObject","url":"https://images.chinatimes.com/newsphoto/2019-12-11/900/20191211004430.jpg","height":369,"width":656},"author": {"@type": "Person","name": "王寶兒" }, "url":"https://www.chinatimes.com/realtimenews/20191211004429-260405",
"description":"王寶兒/新北報導紀錄片《AI新紀元》揭示,預計203...
....
</script>```
``` <script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"articleSection": "生活",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://www.chinatimes.com/realtimenews/20191211004429-260405"
},
"headline": "作曲、繪畫難不倒 AI也能玩藝術",
"image": {"@type": "ImageObject","url":"https://images.chinatimes.com/newsphoto/2019-12-11/900/20191211004430.jpg","height":369,"width":656},"author": {"@type": "Person","name": "王寶兒" }, "url":"https://www.chinatimes.com/realtimenews/20191211004429-260405",
"description":"王寶兒/新北報導紀錄片《AI新紀元》揭示,預計203...
....
</script>```
tmonk
20:35:40
@felixtypingmonkey has joined the channel
2019-12-12
gugod
08:20:30
自由時報也有。但 description 不是全文,並且 “author.name” 不是記者名,而是「自由時報」四個字
view-source:https://news.ltn.com.tw/news/society/breakingnews/3006341
view-source:https://news.ltn.com.tw/news/society/breakingnews/3006341
自由電子報
新北市海山警分局8名派出所基層員警,被檢舉自2017年起,涉嫌不實填寫「線上立破」案查獲過程,藉以浮報嘉獎,檢調10月底約談8名涉案員警到案,其中一名陳姓警員被依涉犯貪污罪收押禁見,其他7名警員分別以10到20萬元不等金額交保,新北地檢署追查發現另有2名警員涉案,昨再約談洪姓與劉姓離職警員,今晨訊後諭令洪、劉分別以10、5萬元交保。任職文聖派出所的陳員被收押後,檢方追查發現,陳員先前任職江翠派出所期間,另有洪、劉姓同事配合偽造「線上立破」文件,因此昨指揮新北市警局督察室、政風室搜索約江翠派出所及洪、劉住處,另以證人身分約談江翠派出所所長及4名員警。
gugod
08:21:50
嗯。看來就是 Slack 抓到的這一段字。(或許 Slack 就 是抓 `script[type="application/ld+json"]` )
gugod
08:22:21
喔,也有可能是 og:title + og:description
chihao
19:26:19
萬物傑克 RSS
chihao
19:26:26
@gugod ++++
chihao
19:28:48
等一下 8:00 就是 disinfoRG community hangout 囉,歡迎來玩!
網址:https://meet.jit.si/disinfo
共筆:https://g0v.hackmd.io/BChGrPg-TkWsvks2ey5q6A
網址:https://meet.jit.si/disinfo
共筆:https://g0v.hackmd.io/BChGrPg-TkWsvks2ey5q6A
chihao
19:40:31
作者 github id 是 `DIYgod` 😆
reason1130
23:59:47
@reason1130 has joined the channel
2019-12-13
pm5
12:14:02
上次 @fockerlee 講到可以用 airtable 來釋出一些資料。因為 airtable API 確實蠻好用的,我想可以用釋出部份資料的方式來解決資料量的問題。這個「部份資料」的篩選可以想一下對資料分析比較有意義的方式,像是針對一個新聞事件,釋出事件後 3 天內所有網站的發佈文章資料,或是釋出所有內文有特定關鍵詞的發文資料
- ❤️3
 1
1
gugod
2019-12-13 12:36:46
或許可以試著算出與指定關鍵詞相關的其他關鍵詞
gugod
2019-12-13 12:37:52
作個詞與詞之間的 pagerank table 之類的
gugod
12:36:46
或許可以試著算出與指定關鍵詞相關的其他關鍵詞
gugod
12:37:52
作個詞與詞之間的 pagerank table 之類的
2019-12-14
gugod
18:54:15
來丟個問題:先不論事實成份多少與立場問題,各位覺得一篇新聞的「製作品質」,該怎麼來定義? (thread)
- 🙌2
gugod
2019-12-14 18:55:20
我在寫爬蟲 ( NewsExtractor / people-in-news ) 時一面也在想這個問題。但只想得一些隨意的評量標準。
gugod
2019-12-14 18:58:19
比方說:
1. 要有「標題」「日期時間」「記者名」「內文」這四欄位。
2. 內文 與 標題 所闡述的主題應相符 (否則就是「名不符實」,偏向 disinfomation 那一側的寫作法)
1. 要有「標題」「日期時間」「記者名」「內文」這四欄位。
2. 內文 與 標題 所闡述的主題應相符 (否則就是「名不符實」,偏向 disinfomation 那一側的寫作法)
gugod
2019-12-14 18:59:41
3. 內文所闡述事件的時間不應與目前時間相距太遠。(舊聞)
gugod
2019-12-14 19:07:43
4. 內文與標題不應出現「網友」兩字
粗略觀察起來,大致上用了「網友」兩字的新聞內文都是帶一點虛假成分。或是「網友表示〇〇〇」為文中主要論點的支持論點,但去搜尋又找不到網友是在哪裡表示〇〇〇。變成是一種「虛的參考來源」。
粗略觀察起來,大致上用了「網友」兩字的新聞內文都是帶一點虛假成分。或是「網友表示〇〇〇」為文中主要論點的支持論點,但去搜尋又找不到網友是在哪裡表示〇〇〇。變成是一種「虛的參考來源」。
gugod
2019-12-14 19:08:42
(不過是有點看狀況。如果「網友」本身是文章主題可能就不算)
tkirby
2019-12-14 20:06:29
感覺要參考這本書
tkirby
2019-12-14 20:06:53
tkirby
2019-12-14 20:13:11
裡面也有在探討不實訊息:
tkirby
2019-12-14 20:13:31
限定在新聞的話,可能寫作格式?前 3 個段落的長度、句數、全文裡驚嘆號或某些特殊符號的數量
我覺得製作品質是一個技術性的東西,與真實不真實、有沒有操控的意圖,不大有關係。可以有製作精良的假消息,也可以有透露事實的流言。另外製作品質本身也沒有好或不好的區別,只有適不適合,或者說適合在哪種消息管道裡流通的差別。
但是到了「新聞」這種特別的傳播體系裡的內容製作品質,就有一些好與不好的判準了。
gugod
2019-12-15 10:31:31
> 我覺得製作品質是一個技術性的東西,與真實不真實、有沒有操控的意圖,不大有關係。
我個人的直覺與此稍有不同。 「不精良」的東西,製做過程通常不耗時力。而「事實成分低少」的新聞文字,製做起來也比較不秏時力[*]。
做事實查核很費力,但如果有方法能很快速而大致上篩選、區別出「精質」與「粗糙」的新聞文字的話,或許一定程度上可以將此方法做為轉守為攻的工具。
[*]: 這一點是我個人假設
我個人的直覺與此稍有不同。 「不精良」的東西,製做過程通常不耗時力。而「事實成分低少」的新聞文字,製做起來也比較不秏時力[*]。
做事實查核很費力,但如果有方法能很快速而大致上篩選、區別出「精質」與「粗糙」的新聞文字的話,或許一定程度上可以將此方法做為轉守為攻的工具。
[*]: 這一點是我個人假設
gugod
2019-12-15 10:33:00
一定程度上就像食品被要求以特定包裝、成份表,以及生產履歷那樣。
gugod
2019-12-15 12:20:01
「文章配圖」這點不錯:
> 假若一篇長篇文章配圖來源不明(可能是盜圖)或是花一點小錢買來的圖庫內容(很容易辨識),這篇文章多半有問題;
> 假若一篇長篇文章配圖來源不明(可能是盜圖)或是花一點小錢買來的圖庫內容(很容易辨識),這篇文章多半有問題;
gugod
2019-12-15 12:21:03
至少能以圖片搜尋引擎去快速而簡單地檢查
tkirby
2019-12-15 12:58:33
大家覺得像這樣的新聞 品質上有什麼問題呢? https://tw.appledaily.com/new/realtime/20131022/278921/
gugod
2019-12-15 22:36:52
除了「內文所述這件事情跟我基本上無關」、可能就是它很短,資訊量也很少。推測,大概也不需要多少時間與心力就可以被製作出來。
記者名有標示還可以。
再我對「今早」這個時間表示格式有點意見,我認為內文的時間也要盡可能精確。如果只是把微博發文拷貝下來,至少可以把原文的發文時間一起標出。
記者名有標示還可以。
再我對「今早」這個時間表示格式有點意見,我認為內文的時間也要盡可能精確。如果只是把微博發文拷貝下來,至少可以把原文的發文時間一起標出。
chihao
2019-12-18 23:30:52
「網友」有時候還會被進一步縮寫成「網」,真的很煩。
gugod
18:55:20
我在寫爬蟲 ( NewsExtractor / people-in-news ) 時一面也在想這個問題。但只想得一些隨意的評量標準。
gugod
18:58:19
比方說:
1. 要有「標題」「日期時間」「記者名」「內文」這四欄位。
2. 內文 與 標題 所闡述的主題應相符 (否則就是「名不符實」,偏向 disinfomation 那一側的寫作法)
1. 要有「標題」「日期時間」「記者名」「內文」這四欄位。
2. 內文 與 標題 所闡述的主題應相符 (否則就是「名不符實」,偏向 disinfomation 那一側的寫作法)
- ❤️1
gugod
18:59:41
3. 內文所闡述事件的時間不應與目前時間相距太遠。(舊聞)
gugod
19:07:43
4. 內文與標題不應出現「網友」兩字
粗略觀察起來,大致上用了「網友」兩字的新聞內文都是帶一點虛假成分。或是「網友表示〇〇〇」為文中主要論點的支持論點,但去搜尋又找不到網友是在哪裡表示〇〇〇。變成是一種「虛的參考來源」。
粗略觀察起來,大致上用了「網友」兩字的新聞內文都是帶一點虛假成分。或是「網友表示〇〇〇」為文中主要論點的支持論點,但去搜尋又找不到網友是在哪裡表示〇〇〇。變成是一種「虛的參考來源」。
- 🙌1
gugod
19:08:42
(不過是有點看狀況。如果「網友」本身是文章主題可能就不算)
tkirby
20:06:29
感覺要參考這本書

tkirby
20:13:11
裡面也有在探討不實訊息:
2019-12-15
pm5
08:57:25
限定在新聞的話,可能寫作格式?前 3 個段落的長度、句數、全文裡驚嘆號或某些特殊符號的數量
pm5
08:58:15
OOPS! 新鮮事
說到台灣的新聞媒體,嗯,大家都知道的事情就不多說了...畢竟平常被罵沒營養、只會抄臉書和行車紀錄器也不是一天兩天的事情了,那最近就有批踢踢網友討論到,在新聞媒體常用的播報詞彙裡面,有那些是常聽到又讓人
- 1

pm5
09:14:24
我覺得製作品質是一個技術性的東西,與真實不真實、有沒有操控的意圖,不大有關係。可以有製作精良的假消息,也可以有透露事實的流言。另外製作品質本身也沒有好或不好的區別,只有適不適合,或者說適合在哪種消息管道裡流通的差別。
pm5
09:25:06
但是到了「新聞」這種特別的傳播體系裡的內容製作品質,就有一些好與不好的判準了。
pm5
09:56:27
@ayw255 how is it going? After some thoughts I believe it'd be better if we put parsers in the same git repo, at least for the current stage of the project.
We can probably add a `ArticleParser` dir under project root for the parsers. They can have their own db settings and migrations there. We can also just rename `codes` dir to `NewsScrapper` to better reflect its functions, and move news db settings and migrations to some subdir.
This "semi-gigantic repo" project structure would make it easier to deploy to middle2.
wenyi
2019-12-15 10:13:31
@pm5 parser is almost done now in branch ‘parser’ in codes/parser.py. waiting for @chihao for new db and/or elasticsearch for it to be fully functional.
wenyi
2019-12-15 10:13:51
Umm the code structure sounds fine to me
wenyi
2019-12-15 10:15:42
But, I wonder why parser needs a sub dir, why don’t we just put env settings in the same .env folder and maybe named them as, for example, ‘PARSER_DB_URL’
wenyi
2019-12-15 10:16:24
Since parser only has need 1 code? Unless we are looking to develop more codes for post-processing the parsed results (and decided to put them in the same repo)
oh we can use `PARSER_DB_URL` and shared `.env` and Python dependencies. It's just that I am anticipating more post-processing code for FB, Twitter, maybe YouTube etc.
Parser db schema proposal https://g0v.hackmd.io/lMQO37z6SbWNWo3R4-X_EA?view#Parser-database-schema
...and a revised project structure https://github.com/disinfoRG/NewsScraping/tree/parserdb
chihao
2019-12-15 17:03:46
@ayw255 sorry I’m lagging behind on the middle2 front. Will pick that up!
I think it will be some time before we have 2 mysql db? Guess we will have to put scrapper and parser data in the same place for now.
chihao
2019-12-16 11:12:33
I’m not sure if we can have 2 mysql dbs in the same middle2 project yet. (I should have started this process earlier. My apologies.) I could just start a new middle2 project and a new db in that project?
chihao
2019-12-16 11:15:01
OK starting one now
That was fast.
We could also do that. Then we need a new repo for parsers.
Here we go.
chihao
2019-12-16 11:20:40
Done 🙂 new db for parsed content in new middle2 project `taoyuan-chu-975484`
chihao
2019-12-16 11:21:02
I’ve added @pm5 @ayw255 @fockerlee to the new middle2 project as well
chihao
2019-12-16 11:21:36
Turns out you can switch between mysql dbs in phpmyadmin across middle2 projects 🤔
chihao
2019-12-16 11:22:11
Again, I should have done this earlier. Sorry 😞
Well, for a project like this to build a data pipeline, in the end it is better if we own the infrastructure to some extend. But we probably are not going to *really* need that in the first 6 months.
Because a data pipeline consists of a set of data storage/files/db connected with many processing lines in between, each db might be accessed by more than one codebases with different purposes in mind. So it's usually better if a db is not *owned* by anyone of the codebases but is maintained individually.
And so deploying that kind of projects is a bit more involved, usually employs Puppet or Ansible or some infrastructure-as-code tool.
And when the data volume is getting really high or when the pipeline topology gets complicated, dbs would start to restrict their access with APIs, so that changes to their internal schemas don't propagate through the project so quickly that it breaks.
But we are not at that stage yet. We can let the scrapper project owns a db, the parser project owns another. Either a gigantic repo or two separated projects would do, since middle2 projects can share dbs among projects.
pm5
09:59:57
We can probably add a `ArticleParser` dir under project root for the parsers. They can have their own db settings and migrations there. We can also just rename `codes` dir to `NewsScrapper` to better reflect its functions, and move news db settings and migrations to some subdir.
pm5
10:04:55
This "semi-gigantic repo" project structure would make it easier to deploy to middle2.
wenyi
10:13:31
@pm5 parser is almost done now in branch ‘parser’ in codes/parser.py. waiting for @chihao for new db and/or elasticsearch for it to be fully functional.
wenyi
10:13:51
Umm the code structure sounds fine to me
wenyi
10:15:42
But, I wonder why parser needs a sub dir, why don’t we just put env settings in the same .env folder and maybe named them as, for example, ‘PARSER_DB_URL’
wenyi
10:16:24
Since parser only has need 1 code? Unless we are looking to develop more codes for post-processing the parsed results (and decided to put them in the same repo)
pm5
10:29:12
oh we can use `PARSER_DB_URL` and shared `.env` and Python dependencies. It's just that I am anticipating more post-processing code for FB, Twitter, maybe YouTube etc.
- 🙌2
- 1
gugod
10:31:31
> 我覺得製作品質是一個技術性的東西,與真實不真實、有沒有操控的意圖,不大有關係。
我個人的直覺與此稍有不同。 「不精良」的東西,製做過程通常不耗時力。而「事實成分低少」的新聞文字,製做起來也比較不秏時力[*]。
做事實查核很費力,但如果有方法能很快速而大致上篩選、區別出「精質」與「粗糙」的新聞文字的話,或許一定程度上可以將此方法做為轉守為攻的工具。
[*]: 這一點是我個人假設
我個人的直覺與此稍有不同。 「不精良」的東西,製做過程通常不耗時力。而「事實成分低少」的新聞文字,製做起來也比較不秏時力[*]。
做事實查核很費力,但如果有方法能很快速而大致上篩選、區別出「精質」與「粗糙」的新聞文字的話,或許一定程度上可以將此方法做為轉守為攻的工具。
[*]: 這一點是我個人假設
gugod
10:33:00
一定程度上就像食品被要求以特定包裝、成份表,以及生產履歷那樣。
pm5
10:39:42
Parser db schema proposal https://g0v.hackmd.io/lMQO37z6SbWNWo3R4-X_EA?view#Parser-database-schema
- 🙌2
pm5
10:41:11
...and a revised project structure https://github.com/disinfoRG/NewsScraping/tree/parserdb
gugod
12:18:10
https://medium.com/@tunaBR/%E5%88%A4%E5%AE%9A%E6%96%B0%E8%81%9E%E5%85%A7%E5%AE%B9%E5%93%81%E8%B3%AA%E7%9A%84%E5%8F%A6%E9%A1%9E%E6%96%B9%E6%B3%95-%E7%B6%B2%E9%A0%81%E7%B5%90%E6%A7%8B%E5%88%86%E6%9E%90-bfcf4e990df8
我的想法跟這篇文章裡提到的「新聞品質評分計畫」跟好像很類似
我的想法跟這篇文章裡提到的「新聞品質評分計畫」跟好像很類似
Medium
本文是筆者一系列內容品質評分系統研究的一環。只要簡單查看任何HTML頁面的組成要素,就能得到許多內容可靠性的線索。問題在於各大內容傳播平台,並沒有在這些線索上花過心思。
gugod
12:20:01
「文章配圖」這點不錯:
> 假若一篇長篇文章配圖來源不明(可能是盜圖)或是花一點小錢買來的圖庫內容(很容易辨識),這篇文章多半有問題;
> 假若一篇長篇文章配圖來源不明(可能是盜圖)或是花一點小錢買來的圖庫內容(很容易辨識),這篇文章多半有問題;
gugod
12:21:03
至少能以圖片搜尋引擎去快速而簡單地檢查
tkirby
12:58:33
大家覺得像這樣的新聞 品質上有什麼問題呢? https://tw.appledaily.com/new/realtime/20131022/278921/
蘋果新聞網
【蔡維歆╱台北報導】歐陽妮妮今一早起床,拿起一件很久沒穿的外套,結果竟意外發現外套口袋裡有200塊,讓她又驚又喜,於是在微博發了一篇文。她笑...
- 🤔2
chihao
17:03:46
@ayw255 sorry I’m lagging behind on the middle2 front. Will pick that up!
gugod
22:36:52
除了「內文所述這件事情跟我基本上無關」、可能就是它很短,資訊量也很少。推測,大概也不需要多少時間與心力就可以被製作出來。
記者名有標示還可以。
再我對「今早」這個時間表示格式有點意見,我認為內文的時間也要盡可能精確。如果只是把微博發文拷貝下來,至少可以把原文的發文時間一起標出。
記者名有標示還可以。
再我對「今早」這個時間表示格式有點意見,我認為內文的時間也要盡可能精確。如果只是把微博發文拷貝下來,至少可以把原文的發文時間一起標出。
2019-12-16
pm5
11:11:36
I think it will be some time before we have 2 mysql db? Guess we will have to put scrapper and parser data in the same place for now.
chihao
11:12:33
I’m not sure if we can have 2 mysql dbs in the same middle2 project yet. (I should have started this process earlier. My apologies.) I could just start a new middle2 project and a new db in that project?
chihao
11:15:01
OK starting one now
pm5
11:17:37
That was fast.
pm5
11:19:01
We could also do that. Then we need a new repo for parsers.
pm5
11:19:51
Here we go.
chihao
11:20:40
Replied to a thread: 2019-12-15 09:56:27
Done 🙂 new db for parsed content in new middle2 project `taoyuan-chu-975484`
chihao
11:21:02
I’ve added @pm5 @ayw255 @fockerlee to the new middle2 project as well
chihao
11:21:36
Turns out you can switch between mysql dbs in phpmyadmin across middle2 projects 🤔
chihao
11:22:11
Again, I should have done this earlier. Sorry 😞
pm5
11:29:45
Well, for a project like this to build a data pipeline, in the end it is better if we own the infrastructure to some extend. But we probably are not going to *really* need that in the first 6 months.
- 👍1
pm5
11:33:20
Because a data pipeline consists of a set of data storage/files/db connected with many processing lines in between, each db might be accessed by more than one codebases with different purposes in mind. So it's usually better if a db is not *owned* by anyone of the codebases but is maintained individually.
- 1
pm5
11:35:47
And so deploying that kind of projects is a bit more involved, usually employs Puppet or Ansible or some infrastructure-as-code tool.
pm5
11:39:01
And when the data volume is getting really high or when the pipeline topology gets complicated, dbs would start to restrict their access with APIs, so that changes to their internal schemas don't propagate through the project so quickly that it breaks.
pm5
11:42:05
But we are not at that stage yet. We can let the scrapper project owns a db, the parser project owns another. Either a gigantic repo or two separated projects would do, since middle2 projects can share dbs among projects.
- 👍1
Ping Lin
18:14:57
@ping.lin has joined the channel
2019-12-17
cookie_dog
17:21:01
@iverylikedog has joined the channel
2019-12-18
chihao
23:29:39
Just finished tonight’s live fact-checking session for the presidential policy presentations.
chihao
23:30:03
Note for the data set: remember to decide on the license.
chihao
23:30:52
「網友」有時候還會被進一步縮寫成「網」,真的很煩。
2019-12-19
Chen
01:28:20
@iping.ch has joined the channel
wenyi
06:12:38
@chihao @pm5 @fockerlee 大松投影片 第一版
1. [英文] https://docs.google.com/presentation/d/10dlv6ouTGGKbJSR6xWAendaCP_D3UFRK2fowz5F_V0o/edit?usp=sharing
2. [中文] https://docs.google.com/presentation/d/1G8LN9jXWYjEQc95XAXkIE4ynXow65ahxwK5GtvL6Gjg/edit?usp=sharing
1. [英文] https://docs.google.com/presentation/d/10dlv6ouTGGKbJSR6xWAendaCP_D3UFRK2fowz5F_V0o/edit?usp=sharing
2. [中文] https://docs.google.com/presentation/d/1G8LN9jXWYjEQc95XAXkIE4ynXow65ahxwK5GtvL6Gjg/edit?usp=sharing
 1
1- ❤️1
wenyi
2019-12-21 01:41:15
@chihao @pm5 @fockerlee any comments or things to add? Should we use the chinese or english version?
chihao
2019-12-21 01:43:42
@ayw255 it’s been a hectic day here in Tainan. Hold on let me see!
chihao
2019-12-21 01:48:16
@ayw255 ++ I think it looks really good :) I’ll update some text tomorrow. I’m not sure if we should use Mandarin or English version... slides aside, would you like to speak in Mandarin or English for the 3-minute pitch?
chihao
2019-12-21 01:48:40
Gotta get some sleep now... I’ll come back to this early morning :)
wenyi
2019-12-21 01:48:52
sure sure! night night
wenyi
2019-12-21 06:01:20
I can do the pitch in English, and also if there are ~20 audiences who don’t understand mandarin I think it’s better to use English?
wenyi
2019-12-21 09:12:45
Anyways, I’m on the dev meeting google hangout
one moment
wenyi
2019-12-21 09:34:19
Np! I’ll log in ~ 10 am
Let's pitch in English, since we registered as one of the FtO projects.
Filled in the links to the datasets and minihackathon schedule.
Relax
19:17:15
@healthya2776 has joined the channel
2019-12-21
wenyi
01:41:15
@chihao @pm5 @fockerlee any comments or things to add? Should we use the chinese or english version?
chihao
01:43:42
@ayw255 it’s been a hectic day here in Tainan. Hold on let me see!
chihao
01:48:16
@ayw255 ++ I think it looks really good :) I’ll update some text tomorrow. I’m not sure if we should use Mandarin or English version... slides aside, would you like to speak in Mandarin or English for the 3-minute pitch?
chihao
01:48:40
Gotta get some sleep now... I’ll come back to this early morning :)
wenyi
01:48:52
sure sure! night night
chewei 哲瑋
03:43:30
@chewei has joined the channel
wenyi
06:01:20
I can do the pitch in English, and also if there are ~20 audiences who don’t understand mandarin I think it’s better to use English?
paulpengtw
08:53:21
@paulpengtw has joined the channel
wenyi
09:12:45
Anyways, I’m on the dev meeting google hangout
pm5
09:33:25
one moment
pm5
09:36:24
Let's pitch in English, since we registered as one of the FtO projects.
chihao
13:11:23
@ayw255 ++ for the pitch!
hkazami
13:15:33
@mail.hkazami has joined the channel
ronnywang
13:47:08
昨天跟 Bruce 提到我要開源我這邊爬檔案廣告庫的程式,https://github.com/ronnywang/fb-ad-lib
Contribute to ronnywang/fb-ad-lib development by creating an account on GitHub.
 2
2
ronnywang
13:47:50
主要是用 nodejs 的 casperjs 抓 HTML 下來,然後用 PHP parse
pm5
13:56:38
內容農場 dataset in CSV https://drive.google.com/open?id=1oVA-4W3HPbtnVoudlwfuLCtCYoiUSp80
- ❤️1
pm5
13:57:14
新聞內容 dataset in CSV https://drive.google.com/open?id=1efDrL8Q3guQ6yjT6E1bdndBJqZ9P6YYs
fly
15:04:20
A block list for ublock and other adblocker / 純公益阻擋共媒跟內容農場 - festum/anti-bias-media
gugod
2019-12-21 15:12:56
gugod
2019-12-21 15:13:20
(hohser 也是個 browser ext.)
酷,原來可以在 search engine 擋下
gugod
15:12:56
Highlight or Hide Search Engine Results. Contribute to pistom/hohser development by creating an account on GitHub.
 1
1
gugod
15:13:20
(hohser 也是個 browser ext.)
pm5
15:58:25
我們沒有爬上報呀?
看起來是同一篇文章在怒吼 https://nooho.net/2019/11/DPPfraud27471/
應該可以用 text diff 連起來
喔... 怒吼是轉 Yahoo,Yahoo 是轉上報
chihao
2019-12-21 16:07:13
哎唷喂呀

pm5
16:00:58
upmedia.mg
民進黨不分區立委名單難產13日擠出草案。值得注意的是,由行政院長蘇貞昌力推,位列第一的原住民族代表洪簡......
pm5
16:01:23
應該可以用 text diff 連起來
pm5
16:02:11
喔... 怒吼是轉 Yahoo,Yahoo 是轉上報
chihao
16:07:13
哎唷喂呀
2019-12-22
pm5
07:35:17
我們的中時電子報可能沒有抓完整。從政治版首頁看起來估計一天有個 160~180 篇,但 scrapper db 裡只抓到 4206 篇
pm5
08:37:47
ctwant.com 也有,果然是同一家的
pm5
09:24:24
我們抓到的最後一篇是 http://www.qiqi.today/show/882067
琦琦看新聞
香港警方圍捕香港理工大學瀑力分子的行動踏入第六天。據香港《星島日報》報道,一批瀑徒仍留守在香港理工大學校園與警方對峙,目前氣氛平靜。從今天(22日)凌晨至清早,先後再有約14人自願離開,估計留於校內的人數約有50人。報道稱,選擇在凌晨時分一同離開的其中6人,手牽手由正門走出,在防瀑警察監視下,走入對...
pm5
09:24:36
蘋果公司生產的iPhone 系列手機,可以說是開拓多了智慧型手機的市場,開啟了3G時代,前幾年喬布斯的逝世也讓國內熱議了許久,蘋果可以說是喬布斯一手帶大的孩子,這位蘋果之父離開後,也有人說蘋果已經不是蘋果了,但在庫克的帶領下雖然沒有喬布斯時代的突破,還是中規中矩,在中國依舊占就著主要市場。有調皮的網...
2019-12-23
chihao
19:29:02
@pm5 @ayw255 @fockerlee dev meeting in 30 mins 🙂
gugod
21:23:46
https://zht.globalvoices.org/2019/11/29/30049/ // seems revelant
Global Voices 繁體中文
推特在聲明中表示,由20萬推特帳號共同組成的龐大網軍正試圖削弱香港運動的合法性。
- 🤔1
chihao
2019-12-23 22:04:29
Related link: https://www.readr.tw/series/Twitter
chihao
22:04:29
Related link: https://www.readr.tw/series/Twitter
Readr
8 月 19 日,Twitter 公佈了刪除疑似中國網軍帳號的震撼消息。Twitter 將 936 個「源自中國」的帳號停權,並表示這些帳號近期發表大量與香港「反送中」運動有關的假訊息。READr 分析 Twitter 官方釋出資料的幾個發現
pm5
22:11:26
@fockerlee 平常要方便看網頁裡的 JSON-LD 詮釋資料的話,也可以裝這個 addon http://osds.openlinksw.com/
2019-12-24
chihao
09:28:49
\@mail.hkazami/ 0archive airtable 目前僅開放給確定加入開發的開發者編輯 🙇 不過有 read-only 版本 https://airtable.com/shrKvjXMO7GaUg1vd 😄

- 👍1
hkazami
2019-12-24 15:37:28
沒事沒事,我只是看到它問我要不要request access就先按下去再說XD
chihao
2019-12-24 15:37:42
好 😆
hkazami
15:37:28
沒事沒事,我只是看到它問我要不要request access就先按下去再說XD
chihao
15:37:42
好 😆
Victoria Welborn
17:46:53
@vwelborn has joined the channel
chihao
17:47:18
Hi @vwelborn 🙂 welcome to #disinfo. This is where most discussions about 0archive happends 🙂
- 🙂1
Victoria Welborn
2019-12-27 09:01:29
Thank you @chihao and everyone else!!
I wanted to ask the group two things:
1. I am hoping to spend some time with one of you for an interview on g0v and more specifically information on 0archive (as an example of g0v's work) https://g0v.hackmd.io/@kVqWpZq8R12VCa4i1N68UA/SJiTyGyJ8/edit. I will be in town the 6-12, and wanted to see if one person might be available and willing for an on camera interview for the video (who is comfortable speaking primarily in English)? I hope it will only be about an hour of your time (we are also happy to conceal identity if folks would prefer).
2. I wanted to see how this group would feel about a camera attending the mini-hackathon on the 4th to take some b-roll for the video.
Happy to provide more information, thank you all for your time and help :)) We are SO excited to tell the amazing story of the amazing work you all are doing!
I wanted to ask the group two things:
1. I am hoping to spend some time with one of you for an interview on g0v and more specifically information on 0archive (as an example of g0v's work) https://g0v.hackmd.io/@kVqWpZq8R12VCa4i1N68UA/SJiTyGyJ8/edit. I will be in town the 6-12, and wanted to see if one person might be available and willing for an on camera interview for the video (who is comfortable speaking primarily in English)? I hope it will only be about an hour of your time (we are also happy to conceal identity if folks would prefer).
2. I wanted to see how this group would feel about a camera attending the mini-hackathon on the 4th to take some b-roll for the video.
Happy to provide more information, thank you all for your time and help :)) We are SO excited to tell the amazing story of the amazing work you all are doing!
Hi Victoria! There are four of us (@chihao @ayw255 @fockerlee and me) working on 0archive now, with help from others in this channel. I for one would be happy to talk about the project and g0v. As for filming the mini-hackathon, personally I am fine with that, but I imagine we should see if most of the people coming to the hackathon are okay to be filmed, since we haven't mentioned that in registration?
chihao
2019-12-28 10:27:38
@pm5++ I could join as well 🙌 also +1 on asking participants before filming during hackathon.
chihao
2019-12-28 10:29:08
@vwelborn do you mind registering to the hackathon on 1/4? This way I can send you the location just like other participants 🙂
chihao
2019-12-28 10:29:23
Registration is here → https://forms.gle/kqffyonCYWTdeUgk8
Victoria Welborn
2019-12-28 11:14:37
Of course! The only thing is that I will unfortunately be arriving on the 5th so the camera crew (which will only be two other people) will attend without me on the 4th, but I will still register! How would you suggest seeing if people going to the hackathon would mind be filmed?
That would be great about the two of you being filmed and interviewed! Will there also be another hackathon on the 8th? If so, we could hold your interviews there (before, during, or after) at the event.
That would be great about the two of you being filmed and interviewed! Will there also be another hackathon on the 8th? If so, we could hold your interviews there (before, during, or after) at the event.
chihao
2019-12-28 11:20:42
@vwelborn
(1) Either you register or the camera crew register. Either way, might be best to link me, pm5, you, and the camera crew together in the same email thread.
(2) Ask the participants on site. If they refuse, don’t film them.
(3) Events on the 8th are hosted by other projects. I personally am not sure if I’m attending yet. I usually decide on that night if I’m swinging by and bringing beer 😛
(1) Either you register or the camera crew register. Either way, might be best to link me, pm5, you, and the camera crew together in the same email thread.
(2) Ask the participants on site. If they refuse, don’t film them.
(3) Events on the 8th are hosted by other projects. I personally am not sure if I’m attending yet. I usually decide on that night if I’m swinging by and bringing beer 😛
Victoria Welborn
2019-12-28 11:39:07
Perfect - that all sounds great! I will register them and link you all in the same email thread.
As for your interview and @pm5's interview - would either of you be open to perhaps us meeting up separately from the hackathon to do the interview? Maybe just let me know a few dates/times that work (and a preferred location - I can find one if you prefer).
As for your interview and @pm5's interview - would either of you be open to perhaps us meeting up separately from the hackathon to do the interview? Maybe just let me know a few dates/times that work (and a preferred location - I can find one if you prefer).
Victoria Welborn
2019-12-28 11:41:02
And just to clarify - on the 8th the only events that are happening are these two?: (I'm still working on this list - https://g0v.hackmd.io/HaIQVQpLQ8i-ixUDyXtBCQ)
• 1/8 (Wed) vTaiwan mini-hackathon
• Location: Social Innovation Experiment Center, Room A9, 99, Section 3, Ren-ai Road, Taipei
• 1/8 (Wed) disfactory mini-hackathon
• Location: Citizen of the Earth (Taipei Office), 9F 28 Beiping East Road, Taipei
Thank you!
• 1/8 (Wed) vTaiwan mini-hackathon
• Location: Social Innovation Experiment Center, Room A9, 99, Section 3, Ren-ai Road, Taipei
• 1/8 (Wed) disfactory mini-hackathon
• Location: Citizen of the Earth (Taipei Office), 9F 28 Beiping East Road, Taipei
Thank you!
chihao
2019-12-28 12:03:38
Wow this seems like a lot of work! Are there alternative ways to do the interview on 1/4?
Victoria Welborn
2019-12-30 12:03:20
Unfortunately I won't be in Taiwan on the fourth and am the only person conducting the interviews, I'm sorry! However, I'm happy to come to a location that is convenient for you during the 5-12!
Victoria Welborn
2019-12-30 12:06:57
Otherwise, maybe I can just interview one of you, if that would be less stress :)
chihao
2019-12-31 00:10:31
Not sure what’s a good solution here, but I think missing the 1/4 event is indeed unfortunate 😩 I’m a bit worried about the camera crew on 1/4. Would they be self-guided? 🤔
Victoria Welborn
2019-12-31 01:49:31
It would just be one or two people with one camera taking some broll video, which they know how to do in a non intrusive way, but if it's a problem we can just get broll footage on the 8th instead!
Victoria Welborn
2019-12-31 01:51:24
What do you think about me interviewing you and/or pm5 on a separate day and location?
Victoria Welborn
2020-01-02 02:34:11
Hi @chihao and @pm5 happy new year! I spoke to the production company and Luke - my POC there - said he’d happily interview you both on the 4th at the hackathon, without me (if that still works for you both)! I will introduce you both to him via email shortly. Thank you for your patience and understanding!
chihao
2020-01-03 15:25:47
📧 sent 😉
2019-12-25
fly
09:46:40
https://github.com/danny0838/content-farm-terminator 有沒有一個類似這個又能讓群眾共識決擋下農場網站的服務呢,這個用 G form 中心化管理,我覺得這樣管理員太辛苦
「終結內容農場」瀏覽器套件 / Content Farm Terminator browser extension - danny0838/content-farm-terminator
- 👍1
chihao
2019-12-25 13:29:47
那就要來設計共識決的機制囉 😁
發現若只是標示農場,那麼以顏色濃度來表示回報是農場的人數,來提示農場可能性等級,或許就沒有這麼「絕對」
chihao
10:24:03
@pm5 @ayw255 @fockerlee disinf0thon 報名表做好了,你們覺得呢?https://docs.google.com/forms/d/e/1FAIpQLSeo4vsBzAXGUPYW2_grAuf_Gr9hCe3eIcaaL3tDP_asgVnJ9g/viewform
- 🙌1
- ❤️1
加一個「所填寫的資料僅做為 g0v disinfoRG 舉辦不實訊息松使用」?
chihao
2019-12-25 10:49:18
\已加/
wenyi
2019-12-25 11:10:04
Looks good!! 小提議 “exact location will be emailed to you once registration info is verified” 改成 “We’d email you the exact location once the registration is confirmed.”
chihao
2019-12-25 11:11:10
我是想避免 `We` 😆
chihao
2019-12-25 11:11:30
不知道還有沒有需要加別的欄位 🤔
「你可以做什麼」?
chihao
2019-12-25 11:18:39
專長之類的嗎?
yes
chihao
2019-12-25 11:32:19
然後 @bil 就搶先報名了 😆
chihao
2019-12-25 11:32:36
已加:「你的技能」
可惡@mrorz 私訊我「這裡有一個松」我就愉快的報名了XDDDD
鄰鄰技能:會走路的中文網路謠言資料庫
鄰鄰技能:會走路的中文網路謠言資料庫
chihao
2019-12-25 11:37:09
好我幫你加 😆 @mrorz 不要逃避(?)
chihao
2019-12-25 11:38:42
揀日不如撞日,人算不如社群算,那就開放報名囉 😆 等一下來寫文案
isabelhou
2019-12-26 08:52:21
XD
chihao
10:36:02
另外 0archive 的 HackMD book https://g0v.hackmd.io/@chihao/0archive/ 😄
HackMD
# 0archive 零時檔案局 :closed_book: ## 想跳坑嗎 - [跳坑指南](<https://g0v.hackmd.io/cdctnMJWQpKWQYhSxB8sCw>) - [Roadmap](/L1
- 👍1
pm5
10:44:47
加一個「所填寫的資料僅做為 g0v disinfoRG 舉辦不實訊息松使用」?
chihao
10:49:18
\已加/
pm5
11:07:43
第一份資料集釋出了,可以來重新盤點一下期待與 roadmap?我先丟了一些想法在這裡 https://g0v.hackmd.io/@chihao/0archive/%2FL1l9m6joRhCWhmGFZYAO5A
# 0archive 零時檔案局 :closed_book: ## 想跳坑嗎 - [跳坑指南](<https://g0v.hackmd.io/cdctnMJWQpKWQYhSxB8sCw>) - [Roadmap](/L1
- 🙌4
chihao
2019-12-26 20:41:54
@mail.hkazami @tkirby 來 tag 有說想跳坑的 Steven 和 kirby 😛
hkazami
2019-12-26 23:31:12
拜讀中XD
wenyi
11:10:04
Looks good!! 小提議 “exact location will be emailed to you once registration info is verified” 改成 “We’d email you the exact location once the registration is confirmed.”
- 🙌1
chihao
11:11:10
我是想避免 `We` 😆
chihao
11:11:30
不知道還有沒有需要加別的欄位 🤔
pm5
11:17:44
「你可以做什麼」?
chihao
11:18:39
專長之類的嗎?
pm5
11:30:23
yes
chihao
11:32:19
然後 @bil 就搶先報名了 😆
chihao
11:32:36
已加:「你的技能」
bil
11:36:35
可惡@mrorz 私訊我「這裡有一個松」我就愉快的報名了XDDDD
鄰鄰技能:會走路的中文網路謠言資料庫
鄰鄰技能:會走路的中文網路謠言資料庫
chihao
11:37:09
好我幫你加 😆 @mrorz 不要逃避(?)
chihao
11:38:42
揀日不如撞日,人算不如社群算,那就開放報名囉 😆 等一下來寫文案
gugod
13:04:32
[知識好好玩] 【哲學S03E06】民調都是假的啦!? 談歸納論證幾個需注意的推論 #
https://podplayer.net/?id=89999317 via @PodcastAddict
----
這節目裡講到幾種邏輯概念,似乎可以用來幫助定義新聞品質
https://podplayer.net/?id=89999317 via @PodcastAddict
----
這節目裡講到幾種邏輯概念,似乎可以用來幫助定義新聞品質
chihao
13:29:47
那就要來設計共識決的機制囉 😁
fly
13:53:44
酷,原來可以在 search engine 擋下
fly
14:01:43
Replied to a thread: 2019-12-25 09:46:40
發現若只是標示農場,那麼以顏色濃度來表示回報是農場的人數,來提示農場可能性等級,或許就沒有這麼「絕對」

fly
14:06:10
有沒有一個類似這個又能讓群眾共識決擋下農場網站的服務呢,這個用 G form 中心化管理,我覺得這樣管理員太辛苦 若只是標示農場,那麼以顏色濃度來表示回報是農場的人數,來提示農場等級,或許就沒有這麼「絕對」 目前的標示方式,只有是非,新生出來的 domain 無法馬上反應顯得較沒效率
gugod
14:19:50
我印象中這個 browser extention 可以直接從指定網址抓網址名單下來。是個有點類似 adblock 的做法。
- 👍1
目前有 g0v 版農場名單 API 嗎?類似 https://danny0838.github.io/content-farm-terminator/files/blocklist/content-farms.txt
fly
15:42:24
坑主回好快
> 只要有人願意架伺服器寫程式,把結果輸出成網路黑名單放在特定網址即可,不過建置和維護都有成本,做這個也不容易營利,就看有沒有人願意做了……
> 只要有人願意架伺服器寫程式,把結果輸出成網路黑名單放在特定網址即可,不過建置和維護都有成本,做這個也不容易營利,就看有沒有人願意做了……
Leo Chang
發現若只是標示農場,那麼以顏色濃度來表示回報是農場的人數,來提示農場可能性等級,或許就沒有這麼「絕對」
- Forwarded from #disinfo
- 2019-12-25 14:01:43
fly
15:43:07
Replied to a thread: 2019-12-25 14:19:50
目前有 g0v 版農場名單 API 嗎?類似 https://danny0838.github.io/content-farm-terminator/files/blocklist/content-farms.txt
chihao
16:14:13
不實訊息到底長什麼樣子呢?🤔 下週六 1/4 是 disinf0thon 第零次不實訊息松,一起來研究吧。
報名由此去 → https://forms.gle/kqffyonCYWTdeUgk8
報名由此去 → https://forms.gle/kqffyonCYWTdeUgk8
Google Docs
不實訊息到底長什麼樣子呢?一起來研究吧。 :alarm_clock: 時間:2020/1/4 10:30-17:30 :round_pushpin: 地點:台北市(報名確認後以 email 通知) :wave: 主辦單位:g0v disinfoRG 不實資訊研究組、0archive 《零時檔案局》團隊 :alarm_clock: Time: 2020/1/4 10:30-17:30 :round_pushpin: Location: Taipei City (exact location will be emailed to you once registration info is verified) :wave: Host: g0v disinfoRG & 0archive 你所填寫的資料僅做為 g0v disinfoRG 舉辦不實訊息松使用。Info you submitted is only used by g0v disinfoRG for the purpose of hosting disinfo hackathons.
- ❤️2
2019-12-26
wenyi
06:49:25
@pm5 kknews & 壹讀 在middle2上面跑被擋了(週一dev meetings時提到用selenium但抓不到東西的兩個網站),看起來是ip的問題,試著幾個proxy 但拿回來空白的html,有什麼可能的解法嗎?@ronnywang
ronnywang
2019-12-26 09:55:49
他們前面有用 cloudflare ,然後被 cloudflare 擋的?
ronnywang
2019-12-26 09:58:01
kknews 好像是擋了 aws 和 linode IP ?
ronnywang
2019-12-26 10:00:39
ronnywang
2019-12-26 10:01:22
看看要不要在 hicloud 租一個最小機器架 proxy 當跳板 XD hicloud 應該不至於被擋
ronnywang
2019-12-26 10:10:43
hicloud 最小台的每月 360 NTD
ronnywang
2019-12-26 10:12:46
如果連 hicloud 也被擋的話,最保險就是花錢拉一條實體中華電信 ADSL ,然後用個 raspberry pi 來當 proxy ,只要 ip 被擋就自動重新撥接換 IP
ronnywang
2019-12-26 11:13:29
想說開個 hicloud 來試試看好了,結果 hicloud 的機器開通竟然是人工作業….
ronnywang
2019-12-26 11:14:20
等了半小時還沒開好…然後閒閒沒事看看他授權條款,結果發現裡面寫到「乙方使用本服務以秒、時、日、月計費者之最短租期為為連續租用一個月」,所以不能用個一小時就關掉…
chihao
2019-12-26 11:40:30
ronny 各種 solution 參上 😆
ronnywang
2019-12-26 11:53:28
hicloud 開主機一個小時還沒開好…..
hcchien
2019-12-26 12:03:50
“擋了 aws 和 linode IP ?” 那 gcs 呢
ronnywang
2019-12-26 12:04:11
gcs 我還沒試,想說直接試個最不可能被擋的 XD
ronnywang
2019-12-26 12:04:46
有人手上有 gcs 的 server 可以直接試的嗎?
ronnywang
2019-12-26 12:06:30
chihao
2019-12-26 12:08:32
得到 302
chihao
2019-12-26 12:09:10
然後就會拿到 `正在驗證您的訪問請求` `系統偵測到您的電腦網路發出了異常流量,您需經驗證才能訪問我們的網站。`
chihao
2019-12-26 12:09:21
我手上的 GCP vm
DigitalOcean 也被擋
ronnywang
2019-12-26 12:55:07
我放棄 HiCloud 了….我來貢獻我家的 光世代動態 IP 好了
chihao
2019-12-26 12:55:28
HiCloud → ByeCloud
噗
ronnywang
2019-12-26 14:13:01
終於開好 hicloud 了 XD
ronnywang
2019-12-26 14:13:08
hicloud 沒有被擋
ronnywang
2019-12-26 16:14:32
ok, 我這邊可以提供兩個跳板支援
1. HiCloud
2. 我家的光世代 + raspberry pi
前者成本大概 300 NTD / month ,速度比較快一些(一定比 raspberry pi 快),但缺點是換 IP 不方便,假如 IP 被擋需要手動去網頁界面換 IP 或換新機器
後者不需要額外成本(可能有極少的電費 XD),IP 被擋只要重連 PPPoE 就好,這部份可以做到 API 化,缺點是 raspberry pi 本身速度慢,還有一個是用了我本人的 Hinet 帳號,這點不確定會不會有什麼問題
1. HiCloud
2. 我家的光世代 + raspberry pi
前者成本大概 300 NTD / month ,速度比較快一些(一定比 raspberry pi 快),但缺點是換 IP 不方便,假如 IP 被擋需要手動去網頁界面換 IP 或換新機器
後者不需要額外成本(可能有極少的電費 XD),IP 被擋只要重連 PPPoE 就好,這部份可以做到 API 化,缺點是 raspberry pi 本身速度慢,還有一個是用了我本人的 Hinet 帳號,這點不確定會不會有什麼問題
chihao
2019-12-26 16:15:05
我正想推坑你就被搶先跳了!?😆
@ronnywang 用 raspberry pi 的話,你最近有時間弄嗎?大概多久可以架好?
我是想說 raspberry pi 可以包好容易安裝的話,就可以多找幾個人裝起來 round robin
chihao
2019-12-26 20:42:39
真・分散式
chihao
2019-12-26 20:44:22
把後段架構加入 roadmap \o/
isabelhou
08:52:21
XD
ronnywang
09:55:49
他們前面有用 cloudflare ,然後被 cloudflare 擋的?
ronnywang
09:58:01
kknews 好像是擋了 aws 和 linode IP ?
ronnywang
10:10:43
hicloud 最小台的每月 360 NTD
ronnywang
10:12:46
如果連 hicloud 也被擋的話,最保險就是花錢拉一條實體中華電信 ADSL ,然後用個 raspberry pi 來當 proxy ,只要 ip 被擋就自動重新撥接換 IP
- 1
ronnywang
11:13:29
想說開個 hicloud 來試試看好了,結果 hicloud 的機器開通竟然是人工作業….
ronnywang
11:14:20
等了半小時還沒開好…然後閒閒沒事看看他授權條款,結果發現裡面寫到「乙方使用本服務以秒、時、日、月計費者之最短租期為為連續租用一個月」,所以不能用個一小時就關掉…
- ⌛1
- 😮3
isabelhou
11:30:44
好喔
ronnywang
11:53:28
hicloud 開主機一個小時還沒開好…..
hcchien
12:03:50
“擋了 aws 和 linode IP ?” 那 gcs 呢
ronnywang
12:04:11
gcs 我還沒試,想說直接試個最不可能被擋的 XD
ronnywang
12:04:46
有人手上有 gcs 的 server 可以直接試的嗎?
ronnywang
12:06:30
chihao
12:08:32
得到 302
chihao
12:09:10
然後就會拿到 `正在驗證您的訪問請求` `系統偵測到您的電腦網路發出了異常流量,您需經驗證才能訪問我們的網站。`
chihao
12:09:21
我手上的 GCP vm
pm5
12:47:13
DigitalOcean 也被擋
ronnywang
12:55:07
我放棄 HiCloud 了….我來貢獻我家的 光世代動態 IP 好了
chihao
12:55:28
HiCloud → ByeCloud
pm5
12:58:00
噗
ronnywang
14:13:01
終於開好 hicloud 了 XD
chihao
15:33:27
來了來了 ⚠️ 《報導者》的報導 https://www.twreporter.org/topics/information-warfare-business
twreporter.org
《報導者》追蹤數月,揭發藏身在網路背後帶風向的「資訊戰商人」真面目。他們之中有些是握有數據和技術的政治行銷公司,也有操弄Facebook和Google演算法的工程師,政治和企業主向他們下單,讓他們在言論市場裡,操作不平等的訊息戰。
- ❤️5
ronnywang
16:14:32
ok, 我這邊可以提供兩個跳板支援
1. HiCloud
2. 我家的光世代 + raspberry pi
前者成本大概 300 NTD / month ,速度比較快一些(一定比 raspberry pi 快),但缺點是換 IP 不方便,假如 IP 被擋需要手動去網頁界面換 IP 或換新機器
後者不需要額外成本(可能有極少的電費 XD),IP 被擋只要重連 PPPoE 就好,這部份可以做到 API 化,缺點是 raspberry pi 本身速度慢,還有一個是用了我本人的 Hinet 帳號,這點不確定會不會有什麼問題
1. HiCloud
2. 我家的光世代 + raspberry pi
前者成本大概 300 NTD / month ,速度比較快一些(一定比 raspberry pi 快),但缺點是換 IP 不方便,假如 IP 被擋需要手動去網頁界面換 IP 或換新機器
後者不需要額外成本(可能有極少的電費 XD),IP 被擋只要重連 PPPoE 就好,這部份可以做到 API 化,缺點是 raspberry pi 本身速度慢,還有一個是用了我本人的 Hinet 帳號,這點不確定會不會有什麼問題
chihao
16:15:05
我正想推坑你就被搶先跳了!?😆
pm5
16:57:15
@ronnywang 用 raspberry pi 的話,你最近有時間弄嗎?大概多久可以架好?
chihao
20:42:39
真・分散式
chihao
20:44:22
把後段架構加入 roadmap \o/
hkazami
23:31:12
拜讀中XD
2019-12-27
Victoria Welborn
09:01:29
Replied to a thread: 2019-12-24 17:47:18
Thank you @chihao and everyone else!!
I wanted to ask the group two things:
1. I am hoping to spend some time with one of you for an interview on g0v and more specifically information on 0archive (as an example of g0v's work) https://g0v.hackmd.io/@kVqWpZq8R12VCa4i1N68UA/SJiTyGyJ8/edit. I will be in town the 6-12, and wanted to see if one person might be available and willing for an on camera interview for the video (who is comfortable speaking primarily in English)? I hope it will only be about an hour of your time (we are also happy to conceal identity if folks would prefer).
2. I wanted to see how this group would feel about a camera attending the mini-hackathon on the 4th to take some b-roll for the video.
Happy to provide more information, thank you all for your time and help :)) We are SO excited to tell the amazing story of the amazing work you all are doing!
I wanted to ask the group two things:
1. I am hoping to spend some time with one of you for an interview on g0v and more specifically information on 0archive (as an example of g0v's work) https://g0v.hackmd.io/@kVqWpZq8R12VCa4i1N68UA/SJiTyGyJ8/edit. I will be in town the 6-12, and wanted to see if one person might be available and willing for an on camera interview for the video (who is comfortable speaking primarily in English)? I hope it will only be about an hour of your time (we are also happy to conceal identity if folks would prefer).
2. I wanted to see how this group would feel about a camera attending the mini-hackathon on the 4th to take some b-roll for the video.
Happy to provide more information, thank you all for your time and help :)) We are SO excited to tell the amazing story of the amazing work you all are doing!
 1
1- 😎1
fly
09:54:41
> 如同一般內容農場,「密訊」的內容五花八門,包含最能吸引點閱的寵物文章和心理測驗;但點開文章列表,卻可發現其組成幾乎9成都是標註為「新聞」分類的文章。
> 《報導者》根據事實查核平台「Cofacts」的資料庫來進行比對,發現所有檢舉內容中,光是針對「密訊」,就提出過39篇待查證要求,而其中正確訊息僅有4篇
>
> 為了追尋「密訊」流量的去處,《報導者》更使用CrowdTangle工具進行分析,發現它的文章主要都是流入成員萬人以上的泛藍粉專和社團,包括「2020韓國瑜總統後援會(總會)」、「青天白日正義力量」、「監督年金改革行動聯盟」、「靠北民進黨」和「反蔡英文聯盟」等社群內;其中,「青天白日正義力量」這個擁有10萬人粉絲的專頁,更直接將密訊網址列在自己的介紹欄位中。
>
> 屢敗屢戰的「密訊」沒有輕易倒下。事隔一週不到,就出現了新的網址「pplomo.com」(註),截至12月24日前,這個網站依舊可以在Facebook上被使用者轉載。層層封鎖中,「密訊」不倒。
>
> 在關注資訊戰的台北大學犯罪學研究所助理教授沈伯洋眼裡,「密訊」猶如一台「宣傳特定政治意識的宣傳機器」,即便所有人都有自己的立場, 但如果幕後是特定國家伸手利用特定資訊來干擾認知,那麼在這場「改變認知」的戰爭中,台灣就會是輸家。
https://www.twreporter.org/a/information-warfare-business-content-farm-mission
> 《報導者》根據事實查核平台「Cofacts」的資料庫來進行比對,發現所有檢舉內容中,光是針對「密訊」,就提出過39篇待查證要求,而其中正確訊息僅有4篇
>
> 為了追尋「密訊」流量的去處,《報導者》更使用CrowdTangle工具進行分析,發現它的文章主要都是流入成員萬人以上的泛藍粉專和社團,包括「2020韓國瑜總統後援會(總會)」、「青天白日正義力量」、「監督年金改革行動聯盟」、「靠北民進黨」和「反蔡英文聯盟」等社群內;其中,「青天白日正義力量」這個擁有10萬人粉絲的專頁,更直接將密訊網址列在自己的介紹欄位中。
>
> 屢敗屢戰的「密訊」沒有輕易倒下。事隔一週不到,就出現了新的網址「pplomo.com」(註),截至12月24日前,這個網站依舊可以在Facebook上被使用者轉載。層層封鎖中,「密訊」不倒。
>
> 在關注資訊戰的台北大學犯罪學研究所助理教授沈伯洋眼裡,「密訊」猶如一台「宣傳特定政治意識的宣傳機器」,即便所有人都有自己的立場, 但如果幕後是特定國家伸手利用特定資訊來干擾認知,那麼在這場「改變認知」的戰爭中,台灣就會是輸家。
https://www.twreporter.org/a/information-warfare-business-content-farm-mission
曾創「一週被Facebook分享次數最多」紀錄,內容農場密訊在選舉相關社群廣傳。為何它能夠數度下架又重生?背後又是誰在操作?
chihao
10:20:00
嗯,剛剛有人寄信到 g0v-talks,二月有一個叫做 US-TW tech challenge against disinfo 的活動,供大家參考 https://disinfocloud.com/taiwan-tech-challenge
hkazami
2019-12-27 22:08:55
這活動的背後是誰啊……?
chihao
2019-12-28 09:11:17
@mail.hkazami 是美國國務院,來信貼在這裡了 https://g0v.hackmd.io/AHY4VqrkSbWrl9-zjX4Mdg
mengting
14:01:15
@mengting has joined the channel
bruce
17:24:46
想問1/4的第零次松可以公開在不止是disinfo 的地方宣傳嗎?像是粉絲頁或個人限時動態
chihao
17:39:43
我覺得可以耶!
chihao
17:58:47
另外想跟 @pm5 @ayw255 @fockerlee 公開討論的就是 1/18,會覺得需要選後小松,還是想要休息?因為剛好是第一個 deadline 附近,也許 cowork 也不錯。另一個資訊是 1/18 jothon 預計舉辦基礎松,有跟 @besslee 談到併松,但又覺得有點擠 😛
bruce
2019-12-27 23:04:12
我目前覺得cowork +1
cowork
wenyi
2019-12-28 06:12:20
Cowork ++
chihao
2019-12-28 11:50:38
哦嗚好 \o/ 那麼,我有請 @besslee 幫我們預留1/18 NPO Hub 獨立一間會議室,我們可以直接用(bess++)當天白天在 4F 公共區域會是 g0v 基礎松,晚上則會有一個分享會(還不要爆雷好了),大家覺得這樣如何,或者想另找場地也沒問題。 @ayw255 @fockerlee @pm5
bruce
2019-12-28 13:41:23
好耶
bess
17:58:51
@besslee has joined the channel
pm5
20:27:27
Hi Victoria! There are four of us (@chihao @ayw255 @fockerlee and me) working on 0archive now, with help from others in this channel. I for one would be happy to talk about the project and g0v. As for filming the mini-hackathon, personally I am fine with that, but I imagine we should see if most of the people coming to the hackathon are okay to be filmed, since we haven't mentioned that in registration?
- 🙌2
Sofia
20:51:34
@sofia has joined the channel
hkazami
22:08:55
這活動的背後是誰啊……?
bruce
23:04:12
我目前覺得cowork +1
pm5
23:32:31
cowork
2019-12-28
wenyi
06:12:20
Cowork ++
chihao
10:27:38
@pm5++ I could join as well 🙌 also +1 on asking participants before filming during hackathon.
chihao
10:29:08
@vwelborn do you mind registering to the hackathon on 1/4? This way I can send you the location just like other participants 🙂
chihao
10:29:23
Registration is here → https://forms.gle/kqffyonCYWTdeUgk8
Victoria Welborn
11:14:37
Of course! The only thing is that I will unfortunately be arriving on the 5th so the camera crew (which will only be two other people) will attend without me on the 4th, but I will still register! How would you suggest seeing if people going to the hackathon would mind be filmed?
That would be great about the two of you being filmed and interviewed! Will there also be another hackathon on the 8th? If so, we could hold your interviews there (before, during, or after) at the event.
That would be great about the two of you being filmed and interviewed! Will there also be another hackathon on the 8th? If so, we could hold your interviews there (before, during, or after) at the event.
chihao
11:20:42
@vwelborn
(1) Either you register or the camera crew register. Either way, might be best to link me, pm5, you, and the camera crew together in the same email thread.
(2) Ask the participants on site. If they refuse, don’t film them.
(3) Events on the 8th are hosted by other projects. I personally am not sure if I’m attending yet. I usually decide on that night if I’m swinging by and bringing beer 😛
(1) Either you register or the camera crew register. Either way, might be best to link me, pm5, you, and the camera crew together in the same email thread.
(2) Ask the participants on site. If they refuse, don’t film them.
(3) Events on the 8th are hosted by other projects. I personally am not sure if I’m attending yet. I usually decide on that night if I’m swinging by and bringing beer 😛
Victoria Welborn
11:39:07
Perfect - that all sounds great! I will register them and link you all in the same email thread.
As for your interview and @pm5's interview - would either of you be open to perhaps us meeting up separately from the hackathon to do the interview? Maybe just let me know a few dates/times that work (and a preferred location - I can find one if you prefer).
As for your interview and @pm5's interview - would either of you be open to perhaps us meeting up separately from the hackathon to do the interview? Maybe just let me know a few dates/times that work (and a preferred location - I can find one if you prefer).
Victoria Welborn
11:41:02
And just to clarify - on the 8th the only events that are happening are these two?: (I'm still working on this list - https://g0v.hackmd.io/HaIQVQpLQ8i-ixUDyXtBCQ)
• 1/8 (Wed) vTaiwan mini-hackathon
• Location: Social Innovation Experiment Center, Room A9, 99, Section 3, Ren-ai Road, Taipei
• 1/8 (Wed) disfactory mini-hackathon
• Location: Citizen of the Earth (Taipei Office), 9F 28 Beiping East Road, Taipei
Thank you!
• 1/8 (Wed) vTaiwan mini-hackathon
• Location: Social Innovation Experiment Center, Room A9, 99, Section 3, Ren-ai Road, Taipei
• 1/8 (Wed) disfactory mini-hackathon
• Location: Citizen of the Earth (Taipei Office), 9F 28 Beiping East Road, Taipei
Thank you!
chihao
11:50:38
哦嗚好 \o/ 那麼,我有請 @besslee 幫我們預留1/18 NPO Hub 獨立一間會議室,我們可以直接用(bess++)當天白天在 4F 公共區域會是 g0v 基礎松,晚上則會有一個分享會(還不要爆雷好了),大家覺得這樣如何,或者想另找場地也沒問題。 @ayw255 @fockerlee @pm5
- ❤️1
- 1
- 👍1
- 1
chihao
12:03:38
Wow this seems like a lot of work! Are there alternative ways to do the interview on 1/4?
bruce
13:41:23
好耶
pm5
16:59:31
@fockerlee 你問的留言的 reply_to 內容,應該可以用 MySQL 的 `LAST_INSERT_ID()` 在 INSERT post 的時候就拿到,就不用再 query 一次了 https://dev.mysql.com/doc/refman/5.7/en/getting-unique-id.html
2019-12-30
pm5
08:18:48
@fockerlee 我好像吃壞肚子了,今天下午無法
isabelhou
2019-12-30 11:13:34
保重
bruce
2019-12-30 12:07:13
沒問題!保重!
isabelhou
11:13:34
保重
Victoria Welborn
12:03:20
Unfortunately I won't be in Taiwan on the fourth and am the only person conducting the interviews, I'm sorry! However, I'm happy to come to a location that is convenient for you during the 5-12!
Victoria Welborn
12:06:57
Otherwise, maybe I can just interview one of you, if that would be less stress :)
bruce
12:07:13
沒問題!保重!
allenlinli
16:18:41
@allenlinli has joined the channel
pm5
18:33:21
@ayw255 proxy 的問題看起來是 requests 用的 urllib3 有問題 https://github.com/urllib3/urllib3/issues/1520
Why is it that urllib3 doesn&#39;t allow proxy access to HTTPS sites? See poolmanager.py#L416. This limitation seems to be also reflected in the requests library as well. poolmanager.py#L416 def co...
scrapy 不用是 urllib3,它也有一樣的問題嗎?
wenyi
2019-12-30 18:45:36
@pm5 Scrapy沒有試欸,都在用selenium,因為kknews & 壹讀都是需要用selenium開的網站
selenium需要用extention (因為需要帳密authenticate), 用Chrome 有成功過,可是在headless的情形下無法使用(等於死路一條因為在linux不用headless就會crash),看起來Firefox是可以用extension in headless mode,但目前還沒成功Q
selenium需要用extention (因為需要帳密authenticate), 用Chrome 有成功過,可是在headless的情形下無法使用(等於死路一條因為在linux不用headless就會crash),看起來Firefox是可以用extension in headless mode,但目前還沒成功Q
@ronnywang proxy 可以用 token 認證,不要用 basic auth 嗎?
對耶我們需要的是 selenium,我都忘了
ronnywang
2019-12-30 19:34:06
我現在 Proxy 是用 apache 來做
```<VirtualHost *:443>
ProxyRequests On
ProxyVia On
<Proxy *>
AuthType basic
AuthName "private area"
AuthUserFile /srv/passwd
Require valid-user
Order allow,deny
Allow from all
</Proxy>
</VirtualHost>```
設定如上
```<VirtualHost *:443>
ProxyRequests On
ProxyVia On
<Proxy *>
AuthType basic
AuthName "private area"
AuthUserFile /srv/passwd
Require valid-user
Order allow,deny
Allow from all
</Proxy>
</VirtualHost>```
設定如上
lexifdev
2019-12-31 00:25:27
(I read it by Google Transalte. if translator works correctly~)
if you want to access web resources that behind ‘Basic Authentication’, you can do it easley by requests (without complex configurations of Selenium.)
```requests.get('https://api.github.com/user', auth=HTTPBasicAuth('user', 'pass'))```
https://requests.readthedocs.io/en/master/user/authentication/
if you want to access web resources that behind ‘Basic Authentication’, you can do it easley by requests (without complex configurations of Selenium.)
```requests.get('https://api.github.com/user', auth=HTTPBasicAuth('user', 'pass'))```
https://requests.readthedocs.io/en/master/user/authentication/
@sl thanks ❤️
We are trying to crawl a few of the web sites and facebook that requires selenium, though. Otherwise they do not response with meaningful contents.
lexifdev
2020-01-01 10:44:57
yeah. many websites are cannot crawl without real browser based tool.
but I always try this once.
every time I crawl Facebook, I use mobile website (https://iphone.facebook.com/ or https://iphone.facebook.com/). it has also ‘noscript’ version.
some sites that blocked by ‘User-Agent’ or ‘Referer’ are can avoid by
```session = requests.Session()
session.headers.update('Referer', 'https://~~~') # or
session.headers.update('User-Agent', 'Mozilla/5.0 ~~~~')```
(maybe you already know)
but I always try this once.
every time I crawl Facebook, I use mobile website (https://iphone.facebook.com/ or https://iphone.facebook.com/). it has also ‘noscript’ version.
some sites that blocked by ‘User-Agent’ or ‘Referer’ are can avoid by
```session = requests.Session()
session.headers.update('Referer', 'https://~~~') # or
session.headers.update('User-Agent', 'Mozilla/5.0 ~~~~')```
(maybe you already know)
pm5
18:35:12
scrapy 不用是 urllib3,它也有一樣的問題嗎?
wenyi
18:45:36
@pm5 Scrapy沒有試欸,都在用selenium,因為kknews & 壹讀都是需要用selenium開的網站
selenium需要用extention (因為需要帳密authenticate), 用Chrome 有成功過,可是在headless的情形下無法使用(等於死路一條因為在linux不用headless就會crash),看起來Firefox是可以用extension in headless mode,但目前還沒成功Q
selenium需要用extention (因為需要帳密authenticate), 用Chrome 有成功過,可是在headless的情形下無法使用(等於死路一條因為在linux不用headless就會crash),看起來Firefox是可以用extension in headless mode,但目前還沒成功Q
pm5
19:25:14
@ronnywang proxy 可以用 token 認證,不要用 basic auth 嗎?
pm5
19:25:32
對耶我們需要的是 selenium,我都忘了
ronnywang
19:34:06
我現在 Proxy 是用 apache 來做
```<VirtualHost *:443>
ProxyRequests On
ProxyVia On
<Proxy *>
AuthType basic
AuthName "private area"
AuthUserFile /srv/passwd
Require valid-user
Order allow,deny
Allow from all
</Proxy>
</VirtualHost>```
設定如上
```<VirtualHost *:443>
ProxyRequests On
ProxyVia On
<Proxy *>
AuthType basic
AuthName "private area"
AuthUserFile /srv/passwd
Require valid-user
Order allow,deny
Allow from all
</Proxy>
</VirtualHost>```
設定如上
2019-12-31
chihao
00:10:31
Not sure what’s a good solution here, but I think missing the 1/4 event is indeed unfortunate 😩 I’m a bit worried about the camera crew on 1/4. Would they be self-guided? 🤔
lexifdev
00:25:27
(I read it by Google Transalte. if translator works correctly~)
if you want to access web resources that behind ‘Basic Authentication’, you can do it easley by requests (without complex configurations of Selenium.)
```requests.get('https://api.github.com/user', auth=HTTPBasicAuth('user', 'pass'))```
https://requests.readthedocs.io/en/master/user/authentication/
if you want to access web resources that behind ‘Basic Authentication’, you can do it easley by requests (without complex configurations of Selenium.)
```requests.get('https://api.github.com/user', auth=HTTPBasicAuth('user', 'pass'))```
https://requests.readthedocs.io/en/master/user/authentication/
- ❤️1
Victoria Welborn
01:49:31
It would just be one or two people with one camera taking some broll video, which they know how to do in a non intrusive way, but if it's a problem we can just get broll footage on the 8th instead!
Victoria Welborn
01:51:24
What do you think about me interviewing you and/or pm5 on a separate day and location?
ronnywang
09:41:20
@ayw255 大約兩小時前開始主機就有記憶體被吃完的情況,是不是有在做什麼更新呢?
wenyi
2019-12-31 09:42:45
@ronnywang 除了昨晚加幾個site進去跑之外沒做什麼改變耶,會是新網站的原因嗎🤔
ronnywang
2019-12-31 09:43:48
每一個 site 都是獨立的 process 在跑嗎?
wenyi
2019-12-31 09:45:44
有一支程式會幫每一個site開一支spider跑,用multiprocessing 所以同時會有幾個spiders一起跑
ronnywang
2019-12-31 09:45:51
我幫 disinfo 開一台獨立的主機好了 XD 看來現在記憶體用量會比較大了
wenyi
2019-12-31 09:54:28
有可能是新的網站東西太多抓得沒完沒了,我來設定一下depth limit
wenyi
09:42:45
@ronnywang 除了昨晚加幾個site進去跑之外沒做什麼改變耶,會是新網站的原因嗎🤔
ronnywang
09:43:48
每一個 site 都是獨立的 process 在跑嗎?
wenyi
09:45:44
有一支程式會幫每一個site開一支spider跑,用multiprocessing 所以同時會有幾個spiders一起跑
ronnywang
09:45:51
我幫 disinfo 開一台獨立的主機好了 XD 看來現在記憶體用量會比較大了
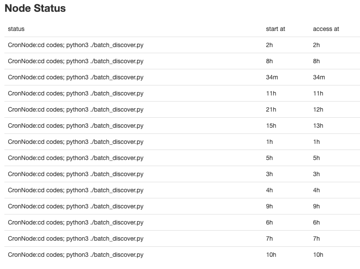
ronnywang
10:15:59
看起來 hourly cron 都跑不完,一直累積著
ronnywang
10:17:56
要不要加一個判斷,如果 hourly cron 發現自己跑超過 60 分鐘的話,就立刻結束自己
ronnywang
10:18:33
然後我手動把超過一小時的 cron 先 kill 掉

chihao
10:21:52
著火了嗎 😢 感謝 mrorz 回報,我晚點修
mrorz
2019-12-31 11:41:43
似乎是權限問題
chihao
2019-12-31 11:51:29
修好了,目前 airtable 只開放專案成員編輯,其他人是 read-only https://airtable.com/shrd0utGHlTWmQsYt
ronnywang
10:35:47
使用上不需要改變什麼,之後 middle2 會自動把 disinfo 新的 request 都用那台專屬的 Linode 處理
mrorz
11:41:43
似乎是權限問題
pm5
11:55:48
@sl thanks ❤️
pm5
11:56:59
We are trying to crawl a few of the web sites and facebook that requires selenium, though. Otherwise they do not response with meaningful contents.
chihao
15:13:39
爬爬爬 🐛
pm5
15:14:33

{kind=link}
ronnywang
15:33:53
batch_discover.py 現在還是有跑不完的問題喔
那來加 --run-time-limit 的檢查好了
現在我們有辦法自己從 shell 砍掉跑不完的 cronjob 嗎?
ronnywang
2019-12-31 17:01:19
不行 XD
ronnywang
2019-12-31 17:01:31
那我來砍掉囉
XD 那現在在跑的先幫我們砍掉吧,然後我先設成 daily run
不對,我現在改成 daily 它又會跑下去 XD
我先把那個 cronjob 刪掉好了
先簡單粗暴地加上 58 分鐘後 killall,放回 hourly cronjob 去跑
昨天晚上重新開始 hourly 跑 batch_discover 了。看 log 感覺都有順利被砍掉,不知道 memory 情況如何?
特別是 selenium 有沒有順利 kill 掉
ronnywang
2020-01-01 13:23:12
應該是有正常砍掉,看起來沒有再累積了
感謝 🙏 新年快樂
pm5
16:30:13
@fockerlee fb 欄位開好了https://g0v.hackmd.io/@chihao/0archive/https%3A%2F%2Fg0v.hackmd.io%2FlMQO37z6SbWNWo3R4-X_EA
# 0archive 零時檔案局 :closed_book: ## 想跳坑嗎 - [跳坑指南](<https://g0v.hackmd.io/cdctnMJWQpKWQYhSxB8sCw>) - [Roadmap](/L1
`Site` 加了 `site_info`,`FBPostSnapshot` 加了 `fb_post_info` 和 `author_info` 減了 `fb_post_id`,`FBCommentSnapshot` 加了 `fb_comment_info` 和 `author_info` 減了 `fb_comment_id`。新加的都是 JSON 欄位
bruce
2019-12-31 16:36:56
好!感謝!
pm5
16:31:45
`Site` 加了 `site_info`,`FBPostSnapshot` 加了 `fb_post_info` 和 `author_info` 減了 `fb_post_id`,`FBCommentSnapshot` 加了 `fb_comment_info` 和 `author_info` 減了 `fb_comment_id`。新加的都是 JSON 欄位
pm5
16:33:27
那來加 --run-time-limit 的檢查好了
bruce
16:36:56
好!感謝!
pm5
17:01:00
現在我們有辦法自己從 shell 砍掉跑不完的 cronjob 嗎?
ronnywang
17:01:19
不行 XD
ronnywang
17:01:31
那我來砍掉囉
pm5
17:02:03
XD 那現在在跑的先幫我們砍掉吧,然後我先設成 daily run
pm5
17:03:52
不對,我現在改成 daily 它又會跑下去 XD
pm5
17:04:12
我先把那個 cronjob 刪掉好了
ronnywang
17:37:03
啊 sorry ,不小心 kill 掉某人的 bash
chihao
18:32:02
立法院今天三讀通過「反滲透法」,民進黨團、國民黨團、時代力量黨團都提出修正動議,最後民進黨以人數優勢下午成功闖關。首家獲中國政府同意落地的台灣媒體《大師鏈》在反滲透法三讀通過後急忙發出聲明,怒批反滲透法為惡法,並宣布將暫時「放棄台灣市場」。落地北京的網路平台《大師鏈》是首家獲中國同意進駐的台灣媒體,藍委曾明宗、國民黨榮譽主席連戰等國民黨人士都表達支持,不過因《大師鏈》延攬前國安局長丶軍情局長加入,更被外界懷疑背後有「紅色力量」,引發熱議。
chihao
18:32:21
來爬《大師鏈》?😆 https://www.masterchain.media/
masterchain.media
大師鏈旨在構建一個以AI技術為基礎的,全球華人價值內容平台。 匯聚全球各地頂尖大師與專家輸出高質量內容, 打造全球華人深度媒體新能量。 基於AI技術的「大師孵化器平台」,人人都是自己領域的「大師」。 這是一個相互賦能的AI價值生態!