#itaigi
2018-12-02
sing5hong5
23:01:30
@liz 我是感覺itaigi閣愛做誠濟功能。是講親像peace講的,無人專心做itaigi,進步的進度有影慢。
若照伊的建議揣贊助,一个工程師改網站,一个負責FB、線跤活動,按呢itaigi較有法度發揮閣較大的影響。
若照伊的建議揣贊助,一个工程師改網站,一个負責FB、線跤活動,按呢itaigi較有法度發揮閣較大的影響。
- 👍1
2018-12-03
2018-12-05
2018-12-06
sing5hong5
07:52:11
@liz 咱ê小編若有欲學,我嘛ē-tàng tshuā XD
sing5hong5
07:56:23
@leo424y 台語辨識效果誠好!
liz
07:56:31
小編無工程師………
sing5hong5
07:56:47
銘彥--ah
sing5hong5
07:57:46
我拜六問看覓,若做的人對台語有興趣是上好
sing5hong5
08:01:12
@leo424y 這是vad image + tdnnf-16k的結果?
- 👍1
這是 8k 的,這個16k https://youtu.be/RFX-dyMeTRY
miaoski
09:54:49
自動辨識嗎?
sing5hong5
09:55:58
是--iooh
sing5hong5
09:55:58
是--iooh
miaoski
10:18:19
!! 強!
miaoski
10:20:26
TDNNF-16K 是 https://github.com/twgo/gu2-im1_pian7-sik4_offline/commit/0d5e63058f791c9c95be85c2f5e1659008339ca7 ?
GitHub
Contribute to twgo/gu2-im1_pian7-sik4_offline development by creating an account on GitHub.
miaoski
10:21:14
https://github.com/twgo/twgo-exp/issues/150 有語料庫著是好…. QQ
我tang-tse push tdnnf-220-16k tdnnf-219-16k 結果220走兩擺(38,, 39)
liz
11:36:02
有夠讚
liz
11:36:17
真正有夠讚
liz
11:36:36
大松我順紲報告?
fly
14:38:42
這是 8k 的,這個16k https://youtu.be/RFX-dyMeTRY
fly
14:39:55
上一部是8k 這部 16k 但目前語料未開源,不知道該不該公開分享呢? @sing5hong5 也怕你工作接到手軟 XD
sing5hong5
14:49:04
@leo424y 開會的時候問高明達老師?
fly
14:49:26
好主意,我等下問
sing5hong5
14:53:37
先講我拜一辭職--ah。賰 @leo424y tih做。
@miaoski 訓練模型script是在 https://github.com/twgo/siann1-hak8_boo5-hing5_nnet3/blob/master/Dockerfile
那個是前端ajax而已
@liz 重點是語料無開源,需要用買的。我這幾工有leh問敢有學術授權,若無就是愛去tsong錢--ah。
@miaoski 訓練模型script是在 https://github.com/twgo/siann1-hak8_boo5-hing5_nnet3/blob/master/Dockerfile
那個是前端ajax而已
@liz 重點是語料無開源,需要用買的。我這幾工有leh問敢有學術授權,若無就是愛去tsong錢--ah。
nnet3聲學模型訓練. Contribute to twgo/siann1-hak8_boo5-hing5_nnet3 development by creating an account on GitHub.
 1
1- 🔮1
- 💳1
sing5hong5
14:59:37
全部語料愛百萬thóng--neh
a-chioh
18:36:55
hi there
a-chioh
18:36:57
cool !
a-chioh
18:39:13
@sing5hong5 what corpus is it ? how expensive ?
sing5hong5
18:43:45
NT 1 million
a-chioh
18:44:28
wow
a-chioh
18:44:36
any link ?
sing5hong5
18:50:06
Second: Tw01,tw02 corpus in http://www.airitilibrary.com/Publication/alDetailedMesh?docid=1027376x-201312-201401060002-201401060002-81-96
airitilibrary.com
本論文的主要研究為使用語音辨識及結合語音評分,對未整理的台語語料進行初步的篩選。藉由機器先過濾掉有問題的音檔,如錄音音量過小、太多雜訊、錄音音檔內容有誤等情形,取代傳統人工聽測費時的做法。本論文可分為三個階段,分別是:「基礎聲學模型訓練」、「語音評分與錯誤原因標記」及「效能評估」。於基礎聲學模型訓練階段,以長庚大學提供的台語語料ForSD (Formosa Speech Database)為材料,使用隱藏式馬可夫模型(Hidden Markov Model, HMM)進行聲學模型的訓練。聲學模型單位分別為:單音素聲學模型(Monophone acoustic model)、音節內右相關雙連音素聲學模型(Biphone acoustic model)及音節內左右相關三連音素聲學模型(Triphone acoustic model),其針對測試語料進行自由音節解碼辨識網路(Free syllable decoding)的音節辨識率(Syllable accuracy)最佳結果分別為:27.20%、43.28%、45.93%。於語音評分與錯誤原因標記階段,將於基礎聲學模型訓練階段已訓練好的左右相關三連音素聲學模型,對待整理的語料進行語音評分,而將其評分結果依照門檻值分為三部分,分別為低分區、中間值區及高分區。且針對低分區部分語料進行人工標記,標記其錯誤原因,再對其擷取特徵,使用支持向量機(Support Vector Machine, SVM)訓練出分類器,最後以該分類器對低分區語料進行二次檢驗,將低分區語料分為可用語料及不良語料。於效能評估階段,將原先訓練語料分別加入「未整理語料」、「中間值區及高分區語料」、「高分區語料」進行聲學模型的訓練,比較篩選語料前、後效能,其音節辨識率結果分別為:40.22%、41.21%、44.35%。由結果看來,經過篩選後語料所訓練出的聲學模型與未經篩選語料所產生的聲學模型,其辨識率的差別最高可達4.13%,證實本論文所提的方法,藉由語音評分確實能有效的自動篩選掉有問題的語句。This research focuses on validating a Taiwanese speech corpus by using speech recognition and assessment to automatically find the potentially problematic utterances. There are three main stages in this work: acoustic model training, speech assessment and error labeling, and performance <http://evaluation.In|evaluation.In> the acoustic model training stage, we use the For SD (Formosa Speech Database), provided by Chang Gung University (CGU), to train hidden Markov models (HMMs) as the acoustic models. Monophone, biphone (right context dependent), and triphone HMMs are tested. The recognition net is based on free syllable decoding. The best syllable accuracies of these three types of HMMs are 27.20%, 43.28%, and 45.93% <http://respectively.In|respectively.In> the speech assessment and error labeling stage, we use the trained triphone HMMs to assess the unvalidated parts of the dataset. And then we split the dataset as low-scored dataset, mid-scored dataset, and high-score dataset by different thresholds. For the low-scored dataset, we identify and label the possible cause of having such a lower score. We then extract features from these lower-scored utterances and train an SVM classifier to further examine if each of these low-scored utterances is to be <http://removed.In|removed.In> the performance evaluation stage, we evaluate the effectiveness of finding problematic utterances by using 2 subsets of For SD, TW01, and TW02 as the training dataset and one of the following: the entire unprocessed dataset, both mid-scored and high-scored dataset, and high-scored dataset only. We use these three types of joint dataset to train and to evaluate the performance. The syllable accuracies of these three types of HMMs are 40.22%, 41.21%, 44.35% respectively.From the previous result, the disparity of syllable accuracy between the HMMs trained by unprocessed dataset and processed dataset can be 4.13%. Obviously, it proves that the processed dataset is less problematic than unprocessed dataset. We can use speech assessment automatically to find the potential problematic utterances.
liz
18:51:09
@sing5hong5 拜六當面討論一下
johnny
18:51:24
@sing5hong5: 抱歉現在才回 server 的事,現在放 linode 的是 db.itaigi.tw,放 middle2 的是 itaigi.tw ( seo server ),其實 middle2 也架好 db.itaigi.tw了,只是之前 middle2 有點問題所以先換回 linode,linode那台也可以 rebuild 成其他版本,再看怎麼樣跟我說哦
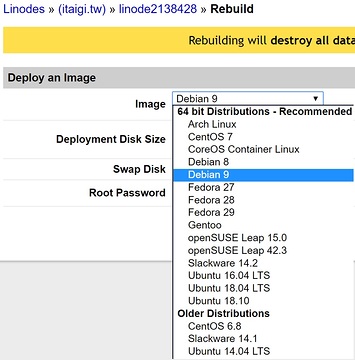
liz
18:52:13
@johnny 現在server的費用是你出的嗎?
johnny
2018-12-06 18:54:03
恩對,但很少錢啦,目前我可以繼續付沒問題,比較是管理上的問題,再看看@sing5hong5 覺得怎麼樣方便
不要這樣啦 !可以給我付嗎?
a-chioh
18:52:27
空空的
johnny
18:54:03
恩對,但很少錢啦,目前我可以繼續付沒問題,比較是管理上的問題,再看看@sing5hong5 覺得怎麼樣方便
2018-12-07
sing5hong5
06:29:33
johnny 花不少耶,10美金*31匯率*30(2016/7~2018/12)=NT 9300
如果有要找贊助,就用那個單位開vm,或想辦法放進middle2,再補johnny或middle2的費用
如果有要找贊助,就用那個單位開vm,或想辦法放進middle2,再補johnny或middle2的費用
fly
10:28:25
https://www.youtube.com/watch?v=RFX-dyMeTRY
羅馬字改成有調的了,若與漢字併排有時會滿滿的字,不知道各位覺得拆成兩種好嗎[漢字]、[漢字加羅馬字有調符],又,預設用哪個好呢?
羅馬字改成有調的了,若與漢字併排有時會滿滿的字,不知道各位覺得拆成兩種好嗎[漢字]、[漢字加羅馬字有調符],又,預設用哪個好呢?
ronnywang
10:29:37
@johnny 你之前有把 db.itagi.tw 放到 middle2 成功過嗎?你說遇到的狀況是什麼呢?
johnny
2018-12-07 21:38:27
蠻久以前了,那時候 middle2 會需要重開,後來你好像有找到問題
可以先幫@sing5hong5 開個 middle2 帳號,我請他試試看 db.itaigi.tw
可以先幫@sing5hong5 開個 middle2 帳號,我請他試試看 db.itaigi.tw
sing5hong5
2018-12-07 22:05:53
@johnny 是因為python3 kah celery的rabbitMq,所以無法度裝?
johnny
2018-12-08 22:36:44
@sing5hong5: 我記得不是,是他當時底層系統的問題, db api instance 當時是可以正常使用的
fly
13:01:27
@liz 對於影片辨識字幕,中研的高老師覺得結果還不理想,不希望被提到,若要分享大概就說是目前有這樣的成果,可以私下了解,或許可找丞宏!學幾招
liz
20:08:38
好 那我就不提了
liz
20:09:29
今天臨下班前才想到還沒去填提案,一看不得了,搶到最後一格………
liz
20:10:21
不要這樣啦 !可以給我付嗎?
johnny
21:38:27
蠻久以前了,那時候 middle2 會需要重開,後來你好像有找到問題
可以先幫@sing5hong5 開個 middle2 帳號,我請他試試看 db.itaigi.tw
可以先幫@sing5hong5 開個 middle2 帳號,我請他試試看 db.itaigi.tw
sing5hong5
22:05:53
@johnny 是因為python3 kah celery的rabbitMq,所以無法度裝?
2018-12-08
a-chioh
00:05:06
@sing5hong5這是2004年的語料庫! 兩年前,給我看的那個呢?(高老師做的?我不太記得)
sing5hong5
2018-12-08 06:21:25
https://iptt.sinica.edu.tw/site/datas/detail/1917/16/109/87/0/
中研院台語語音資料庫(twASIS2017)
中研院台語語音資料庫(twASIS2017)
a-chioh
2018-12-08 16:59:24
感謝!(不過從法國用手機看都是空的,明天再看)
sing5hong5
2018-12-10 06:33:46
twisas.
sing5hong5
06:21:25
https://iptt.sinica.edu.tw/site/datas/detail/1917/16/109/87/0/
中研院台語語音資料庫(twASIS2017)
中研院台語語音資料庫(twASIS2017)
liz
09:52:01
工程師在哪裡QQ
tmonk
10:00:01
@felixtypingmonkey has joined the channel
liz
10:08:55
這則我先暫時編寫初步想法,等比較成熟、完整,也有人有空做時,大家再來定案。 這兩項已有具體想法: 正規化google sheet→前端介面讓更多人參與:模仿政治獻金案雙輸入+檢查,可加入放測驗,就不用審核資格。提高正確率、減少背後團隊的工作量、容易參與。 目前資料庫中非正規用字(來源是線頂辭典):用上面同樣的方式來全面除錯。 以下還在想做法: 3. 如何防止「求講法」出現很多錯誤資料?或如何...
liz
10:08:58
今天主要任務
liz
10:09:13
我等一下要先離開,大約一點半回來
grass
10:34:19
今日鍵盤參與XD
allison.chen
10:35:48
@allison.chen has joined the channel
Reke_WMTW
10:40:04
@reke has joined the channel
Alex Su
11:16:51
@minsiansu has joined the channel
sing5hong5
11:45:13
有人tih問,台南佗位有thang學羅馬字~
shiami
2018-12-18 17:48:23
Tâi-lâm ē-sái mn̄g Tâi-lô-hōe, ū teh khui. Siā-tāi mā ū.
liz
12:15:44
固定開課的好像沒有,都是有時有專案,短期課程,線上自學資源比較多,如果現場有人想學,我等一下可以馬上開小班教
sing5hong5
12:38:52
阮tī 108~
glll4678
13:30:09
閩南語臺羅輸入方案,為RIME輸入法所設計. Contribute to a-thok/rime-hokkien development by creating an account on GitHub.
yfcai
14:56:31
@yfcai has joined the channel
chihyuchen28
16:21:17
@chihyuchen28 has joined the channel
chihyuchen28
16:21:38
哈囉~
johnny
22:36:44
@sing5hong5: 我記得不是,是他當時底層系統的問題, db api instance 當時是可以正常使用的
2018-12-10

2018-12-11
2018-12-12
2018-12-13
fly
19:34:09
你的名字上線了,超棒的!我推了個 pr 以配合主頁style https://github.com/g0v/itaigi/pull/500 且開了個 issue https://github.com/g0v/itaigi/issues/501
2018-12-14
fnnkio
13:07:48
@iaceob has joined the channel
fnnkio
13:13:54
fnnkio
13:14:02
這個問題我已經修復了
fnnkio
13:14:22
該如何提交上去 新建 branch 還是 pr
可以fork後開branch發 pr
fnnkio
2018-12-14 14:52:43
好的
fnnkio
2018-12-14 14:53:21
pr 合到 master ?
Good job 有擷圖就更方便確認結果啦。 @sing5hong5 覺得如何?
fnnkio
2018-12-14 16:24:41
推啦
sing5hong5
2018-12-14 16:37:28
@leo424y 你感覺好就merge,免問我
fnnkio
13:14:30
😂
linekin
13:31:26
@linekin has joined the channel
fly
14:16:58
可以fork後開branch發 pr
fly
14:23:09
help.github.com
If you've forked a repository and made changes to the fork, you can ask that the upstream repository accept your changes by creating a pull request. …
fnnkio
14:52:43
好的
fnnkio
14:53:21
pr 合到 master ?
fly
15:25:09
Good job 有擷圖就更方便確認結果啦。 @sing5hong5 覺得如何?
liz
15:55:59
你的名字被拿去亂玩!!! 這種玩法會得到錯誤資訊,我覺得不行,小編打算在查詢頁加上說明,目前不知道有誰可以處理,我把要放的說明文字也放在這邊。
liz
15:56:36
溫馨提醒:只能查姓名,否則可能會得到錯誤發音!
💯台語小教室💯 ➡️ 姓名發音通則
台語漢字常有多種發音,姓名發音通則為:姓用白話音、名用文讀音。
以上規則當然也有例外:
👉姓的特例
例如「謝」姓有 Tsiā、Siā 兩種發音,各地腔調習慣不同,應該尊重名從主人的原則,以本人自己的發音為準。
也有少數習慣讀成文讀音的姓,像「林」讀 Lîm 不讀 Nâ,「馬」通常讀 Má 不讀 Bé 等等。
另外也有一些文白讀翻轉的情形。舉例來說,「孫」姓原本通行白話音 Sng,但民間有漸漸轉成文讀音 Sun 的趨勢。
👉名的特例
名的部分,雖然一般會照字面用文讀音念,但有時父母長輩是用口語詞、白話音來取名。例如陳「水扁」是叫「Tsuí-pínn」而非文讀音「Suí-pián」,李「江却」是念「Kang-khioh」而不是「Kang-khiok」。有時候還會有「文+白」或「白+文」的組合。
因此,「姓用白話音、名用文讀音」只是大原則,不見得百分之百正確。例外的情況,有可能是臺語原本的習慣,或甚至是特定地區、家族或個人的發音,最好的方式還是向本人確認。
💯台語小教室💯 ➡️ 姓名發音通則
台語漢字常有多種發音,姓名發音通則為:姓用白話音、名用文讀音。
以上規則當然也有例外:
👉姓的特例
例如「謝」姓有 Tsiā、Siā 兩種發音,各地腔調習慣不同,應該尊重名從主人的原則,以本人自己的發音為準。
也有少數習慣讀成文讀音的姓,像「林」讀 Lîm 不讀 Nâ,「馬」通常讀 Má 不讀 Bé 等等。
另外也有一些文白讀翻轉的情形。舉例來說,「孫」姓原本通行白話音 Sng,但民間有漸漸轉成文讀音 Sun 的趨勢。
👉名的特例
名的部分,雖然一般會照字面用文讀音念,但有時父母長輩是用口語詞、白話音來取名。例如陳「水扁」是叫「Tsuí-pínn」而非文讀音「Suí-pián」,李「江却」是念「Kang-khioh」而不是「Kang-khiok」。有時候還會有「文+白」或「白+文」的組合。
因此,「姓用白話音、名用文讀音」只是大原則,不見得百分之百正確。例外的情況,有可能是臺語原本的習慣,或甚至是特定地區、家族或個人的發音,最好的方式還是向本人確認。
fnnkio
16:24:41
推啦
2018-12-18
sing5hong5
11:05:51
標案名稱 台語文創意園區委外經營管理
預算金額 3,000,000元
截止投標 107/12/26 08:30
http://web.pcc.gov.tw/tps/tpam/main/tps/tpam/tpam_tender_detail.do?searchMode=common&scope=F&primaryKey=52698925
招標規範:https://www.dropbox.com/s/4ktfzhrhg6vh2pv/08-3-%E6%8B%9B%E6%A8%99%E8%A6%8F%E7%AF%841207.docx?dl=0
預算金額 3,000,000元
截止投標 107/12/26 08:30
http://web.pcc.gov.tw/tps/tpam/main/tps/tpam/tpam_tender_detail.do?searchMode=common&scope=F&primaryKey=52698925
招標規範:https://www.dropbox.com/s/4ktfzhrhg6vh2pv/08-3-%E6%8B%9B%E6%A8%99%E8%A6%8F%E7%AF%841207.docx?dl=0
web.pcc.gov.tw
[機關名稱]彰化縣文化局[標案名稱]前瞻基礎建設推動藝文專業場館升級計畫-彰化縣政府整建計畫-台語文創意園區委外經營管理[標案案號]CHCAB108-008
shiami
17:48:23
Tâi-lâm ē-sái mn̄g Tâi-lô-hōe, ū teh khui. Siā-tāi mā ū.
2018-12-20
liz
14:00:32
在這邊請教一個問題,維基百科的內文可以合法爬下來當語料嗎?有沒有什麼方法,可以針對其中的某個分類,爬該分類的所有文字內容?一樣是當作語料使用。
- 👍2
shangkuanlc
2019-01-30 09:32:49
成功了嗎?抱歉現在才看到,應該可以用query的方式來要資料,如果想要維基媒體基金會的人幫忙,我可以上phabricator問
a-chioh
15:39:27
不用爬
2018-12-21
liz
08:21:55
謝謝 我試試看
sing5hong5
08:48:17
@glll4678 rime有夠好用,會家己記詞,Linux ê 誠方便~
https://github.com/i3thuan5/rime-taigi
https://github.com/i3thuan5/rime-taigi
Rime台語輸入法詞表 (Taiwanese Input Schema for Rime). Contribute to i3thuan5/rime-taigi development by creating an account on GitHub.
 1
1- 👍1
fly
10:59:02
可以喔,有什麼實際需求呢,我可以做!
Liz462liz lin
在這邊請教一個問題,維基百科的內文可以合法爬下來當語料嗎?有沒有什麼方法,可以針對其中的某個分類,爬該分類的所有文字內容?一樣是當作語料使用。
- Forwarded from #itaigi
- 2018-12-20 14:00:32
不是iTaigi要用的,是我工作上遇到的問題,比如我要把分類為「生物」的所有條目文字內容都抓下來這樣。
liz
17:00:38
不是iTaigi要用的,是我工作上遇到的問題,比如我要把分類為「生物」的所有條目文字內容都抓下來這樣。
2018-12-22
2018-12-26
sing5hong5
23:03:23
[Kang-siong Ho̍k-bū]Lâi tsia̍h-toh, Tsia̍h phîng-an, Siā Tâi-uân
[工商服務]來食桌,食平安,謝臺灣
Kiong-hí Kok-ka Gí-giân Huat-tián-huat sam-tho̍k thong-kuè kah Tâi-gí Tián-sī-tâi ī-sǹg thong-kuè,
恭喜國家語言發展法三讀通過佮台語電視台預算通過,
(慶祝國家語言發展法三讀通過和台語電視台預算通過,)
ta̍k-ke sio-tsio lâi tsia̍h bué-gê!
逐家相招來食尾牙!
(大家一起來吃尾牙!)
7 uī tsóng-phòo tsò-hué lâi pān-toh, tuì in ê tshiú-lōo tsia̍h-tshut tâi-uân ê hó-tsu-bī.
7位總舖做伙來辦桌,對in的手路食出臺灣的好滋味。
(7位總舖師一起辦桌,從他們的拿手菜吃出臺灣的好滋味。)
Koh khah tiōng-iàu ê sī, tsia̍h-toh tiō-sī ài kap khuànn-hì!
閣較重要的是,食桌就是愛敆看戲!
(更重要的是,吃辦桌就是要看戲!)
Iau-tshiánn-tio̍h Siann-ngóo-tsiu Pòo-tē-hì kah Sin-gē-hong Kua-á-hì lâi piànn-tâi.
邀請著聲五洲布袋戲佮新藝芳歌仔戲來拚台。
(邀請到聲五洲布袋戲跟新藝芳歌仔戲來拚場。)
Huan-gîng ta̍k-ke 1/20 lé-pài lâi kàu Lo̍k-káng Po-lê Má-tsóo-king kám-siū lán ê Tâi-uân-bī.
歡迎逐家1/20禮拜來到鹿港玻璃媽祖宮感受咱的臺灣味。
(歡迎大家1/20星期日來到鹿港玻璃媽祖宮感受我們的臺灣味。)
Siông-sè luē-iông lán lóng ē tī FB pun-tiunn!
詳細內容咱攏會佇FB分張!
(詳細內容我們都會在FB分享!)
FB:https://www.facebook.com/%E5%B0%BE%E7%89%99-%E7%9B%B8%E6%8F%AA%E5%90%83%E6%A1%8C-%E6%84%9F%E8%AC%9D%E8%87%BA%E7%81%A3-605451989890923/
Pò-miâ(報名):http://followculture.strikingly.com/
[工商服務]來食桌,食平安,謝臺灣
Kiong-hí Kok-ka Gí-giân Huat-tián-huat sam-tho̍k thong-kuè kah Tâi-gí Tián-sī-tâi ī-sǹg thong-kuè,
恭喜國家語言發展法三讀通過佮台語電視台預算通過,
(慶祝國家語言發展法三讀通過和台語電視台預算通過,)
ta̍k-ke sio-tsio lâi tsia̍h bué-gê!
逐家相招來食尾牙!
(大家一起來吃尾牙!)
7 uī tsóng-phòo tsò-hué lâi pān-toh, tuì in ê tshiú-lōo tsia̍h-tshut tâi-uân ê hó-tsu-bī.
7位總舖做伙來辦桌,對in的手路食出臺灣的好滋味。
(7位總舖師一起辦桌,從他們的拿手菜吃出臺灣的好滋味。)
Koh khah tiōng-iàu ê sī, tsia̍h-toh tiō-sī ài kap khuànn-hì!
閣較重要的是,食桌就是愛敆看戲!
(更重要的是,吃辦桌就是要看戲!)
Iau-tshiánn-tio̍h Siann-ngóo-tsiu Pòo-tē-hì kah Sin-gē-hong Kua-á-hì lâi piànn-tâi.
邀請著聲五洲布袋戲佮新藝芳歌仔戲來拚台。
(邀請到聲五洲布袋戲跟新藝芳歌仔戲來拚場。)
Huan-gîng ta̍k-ke 1/20 lé-pài lâi kàu Lo̍k-káng Po-lê Má-tsóo-king kám-siū lán ê Tâi-uân-bī.
歡迎逐家1/20禮拜來到鹿港玻璃媽祖宮感受咱的臺灣味。
(歡迎大家1/20星期日來到鹿港玻璃媽祖宮感受我們的臺灣味。)
Siông-sè luē-iông lán lóng ē tī FB pun-tiunn!
詳細內容咱攏會佇FB分張!
(詳細內容我們都會在FB分享!)
FB:https://www.facebook.com/%E5%B0%BE%E7%89%99-%E7%9B%B8%E6%8F%AA%E5%90%83%E6%A1%8C-%E6%84%9F%E8%AC%9D%E8%87%BA%E7%81%A3-605451989890923/
Pò-miâ(報名):http://followculture.strikingly.com/
followculture.strikingly.com
辦桌不僅僅是一群人的聚餐,而是重要的時間、對的人一起享用美食,「辦桌謝平安」是最佳寫照,遠方親友來參與謝天地的重要時刻,歡聚感恩,更在食物上呈現傳統與流行。
- ❤️1