#ai-learning
2024-09-02
kiang
14:49:49
Mark Chang
各位g0v夥伴你們好
我是聯發創新基地(MR)的工程師Mark Chang。聯發創新基地預計在近期陸續開源台灣FineWeb預訓練等級資料集,想邀請各方共襄盛舉,一同壯大台灣的AI基礎。
專案緣起:
台灣/繁體中文AI長遠發展最重要的兩件基礎分別是資料與算力,其次才是模型,而台灣目前缺乏預訓練等級的開源資料,
因此MR希望打造這個基於FineWeb技術的開源資料集,希望可以彌補這個缺口。
為什麼FineWeb技術那麼重要?
FineWeb 是 HuggingFace 開源的一套資料包和資料處理方法,HuggingFace 團隊對每一步過濾的成效都進行了對比式驗證以檢測其有效性,最終證明其方法成果優於其他方法。
為目前資料處理的State-of-the-art,詳細可參考連結:https://huggingface.co/datasets/HuggingFaceFW/fineweb
不過FineWeb過濾掉其他語言只留下英文,所以這個專案我們修改其程式碼並適配繁體中文上,進而產生fineweb-traditional-chinese資料集。
我們預計開源計畫時刻表:
• 9/3 開源CC-MAIN-2024-30 50GB
• 9/15 開源CC-MAIN-2024-33 50GB (共100GB)
• 9/30 開源CC-MAIN-2024-26 50GB
• 10/15 開源CC-MAIN-2024-22 50GB(共200GB)
• 10/30 開源CC-MAIN-2024-18 50GB
• 11/15 開源CC-MAIN-2024-SEP 50GB(共300GB)
• 11/30 開源CC-MAIN-2024-OCT 50GB
• 12/15 開源CC-MAIN-2024-10 50GB(共400GB)
• 12/30 開源CC-MAIN-2024-NOV 50GB
• 2025/1/15 開源CC-MAIN-2023-50 50GB(共500GB)
• 2025/1/30 開源CC-MAIN-2023-40 50GB
• 2025/2/15 開源CC-MAIN-2023-23 50GB(共600GB)
• 2025/2/28 開源CC-MAIN-2025-DEC 50GB
• 2025/3/15 開源CC-MAIN-2025-JAN 50GB(共700GB)
• 2025/3/30 開源CC-MAIN-2023-14 50GB
• 2025/4/15 開源CC-MAIN-2023-06 50GB(共800GB)
• 2025/4/30 開源CC-MAIN-2025-FEB 50GB
• 2025/5/15 開源CC-MAIN-2025-MAR 50GB(共900GB)
• 2025/5/30 開源CC-MAIN-2025-APR 50GB
• 2025/6/15 開源CC-MAIN-2022-49 50GB(共1TB)
• 2025/6/30 開源CC-MAIN-2022-40 50GB
• 2025/7/15 開源CC-MAIN-2022-33 50GB(共1.1TB)
• 2025/7/30 開源CC-MAIN-2022-27 50GB
• 2025/8/15 開源CC-MAIN-2025-MAY 50GB(共1.2TB)
• 2025/8/30 開源CC-MAIN-2025-JUNE 50GB
• 2025/9/15 開源CC-MAIN-2025-JULY 50GB(共1.3TB)
我們想邀請您一同健全這個開源計畫:
由於品質高且量級大的預訓練資料開源只是個起點,因此MR想邀請您一同為台灣開源社群做出貢獻,
我們列了一些(包含但不限)可能的後續貢獻,想邀請您一同參與和宣傳。
l 基於fineweb-traditional-chinese開發進一步過濾資料的方法
l 基於fineweb-traditional-chinese訓練開源模型
l 使用Model Based Filtering作用在fineweb-traditional-chinese來打造更高品質的資料
l 基於fineweb-traditional-chinese來產生synthetic data
l 基於fineweb-traditional-chinese來建立台灣詞彙庫
l 基於fineweb-traditional-chinese來建立台灣知識圖譜
讓我們一同做出里程碑的貢獻,如果你們對於這個計畫有興趣,麻煩請寄信給:Yi-Chang.Chen@mtkresearch.com
後續我們會再約一場線上會議做細部的討論,感謝!
- Forwarded from #general
- 2024-09-02 14:35:15
- 💡3
Mark Chang
22:56:34
@ckmarkoh has joined the channel
2024-09-15
meg
23:12:30
@msiu has joined the channel
2024-09-17
kiang
01:36:20
kiang
01:36:20
2024-09-27
annahung
11:53:29
@fbiannahung has joined the channel

2024-09-28
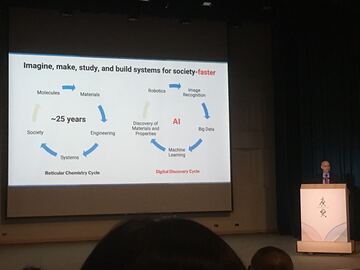
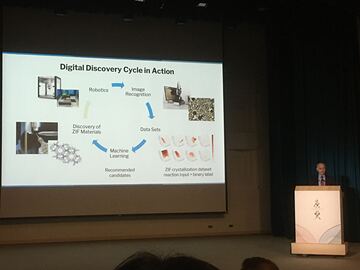
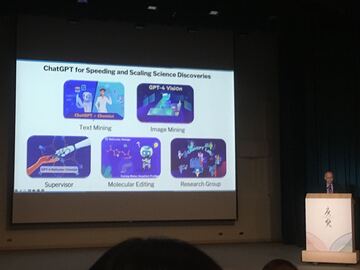

2024-09-29
linmangue_slack
19:40:08
@linmangue_slack has joined the channel
Teemo
21:59:28
eslite.com
AI.抄襲.智財權:從數位時代到生成式AI崛起,新科技徹底改變創作方式。為智慧財產權帶來顛覆性衝擊,引發種種爭議。本書從各種知名有趣的案例切入解析,反思生活中可能碰