#rsshub
2023-02-11
yellowsoar
18:44:21
@yellowsoar has joined the channel
yukai
18:44:29
@yukai has joined the channel
yukai
18:46:38
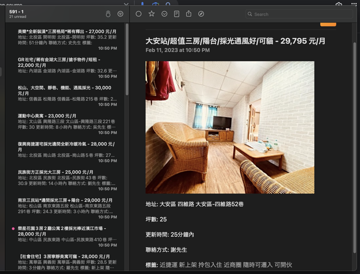
先來做 591 to RSShub 的
yukai
18:46:38
先來做 591 to RSShub 的
2023-02-12
yukai
00:27:38
yukai
2023-02-13 22:12:21
@yellowsoar 合併啦~~
yukai
2023-02-13 22:12:31
我再來寫 group 的
yukai
00:27:38
*该 PR 相关 Issue / Involved issue* 無 *完整路由地址 / Example for the proposed route(s)* ``` /591/rent/:query? ``` *新 RSS 检查列表 / New RSS Script Checklist* ☑︎ 新的路由 New Route ☑︎ 跟随 <https://docs.rsshub.app/joinus/script-standard.html|v2 路由规范> Follows <https://docs.rsshub.app/en/joinus/script-standard.html|v2 Script Standard> ☑︎ 文档说明 Documentation ☑︎ 中文文档 CN ☑︎ 英文文档 EN ☐ 全文获取 fulltext ☐ 使用缓存 Use Cache ☐ 反爬/频率限制 anti-bot or rate limit? ☐ 如果有, 是否有对应的措施? If yes, do your code reflect this sign? ☐ <https://docs.rsshub.app/joinus/pub-date.html|日期和时间> <https://docs.rsshub.app/en/joinus/pub-date.html|date and time> ☐ 可以解析 Parsed ☐ 时区调整 Correct TimeZone ☐ 添加了新的包 New package added ☐ `Puppeteer` *说明 / Note*
- 👍1
yukai
2023-02-13 22:12:21
@yellowsoar 合併啦~~
yukai
2023-02-13 22:12:31
我再來寫 group 的
2023-02-13
yukai
22:12:21
@yellowsoar 合併啦~~
yukai
22:12:31
我再來寫 group 的
2023-02-14
yukai
12:51:36
用了一陣子感覺官方的 cache 時間稍長,對於房屋資訊來說沒有那麼即時 QQ
yukai
2023-02-14 12:52:06
不知道能不能針對個別 routing 調整快取時間
yukai
2023-02-15 00:01:45
再更新,好像只是排序設定錯誤,用時間排序的話,NetNewsWire 一小時能夠 refresh 一次,也還算堪用
yukai
2023-02-15 14:42:40
發現有個 https://www.pikapods.com/ 好方便!
yukai
2023-02-15 21:28:20
剛剛 host 了,版本不能動,有點難用
yukai
2023-02-15 21:28:26
pikapods
yukai
12:51:36
用了一陣子感覺官方的 cache 時間稍長,對於房屋資訊來說沒有那麼即時 QQ
yukai
2023-02-14 12:52:06
不知道能不能針對個別 routing 調整快取時間
yukai
2023-02-15 00:01:45
再更新,好像只是排序設定錯誤,用時間排序的話,NetNewsWire 一小時能夠 refresh 一次,也還算堪用
yukai
2023-02-15 14:42:40
發現有個 https://www.pikapods.com/ 好方便!
yukai
2023-02-15 21:28:20
剛剛 host 了,版本不能動,有點難用
yukai
2023-02-15 21:28:26
pikapods
yukai
12:52:06
不知道能不能針對個別 routing 調整快取時間
2023-02-15
yukai
00:01:45
再更新,好像只是排序設定錯誤,用時間排序的話,NetNewsWire 一小時能夠 refresh 一次,也還算堪用
yukai
14:42:40
發現有個 https://www.pikapods.com/ 好方便!
yukai
21:28:20
剛剛 host 了,版本不能動,有點難用
yukai
21:28:26
pikapods
2023-02-16
yukai
19:41:58
@yellowsoar 剛好遇到 proxy 的問題,facebook 社團的爬蟲一定要在臺灣 IP 也能用,所以需要架在臺灣或是用其他的 proxy?
yukai
2023-02-16 19:44:14
比如這一頁,用無痕開的話 Surfshark 的 IP 也會變成需要登入 https://mbasic.facebook.com/groups/464870710346711
yukai
2023-02-16 19:49:45
用 tor exit node 設定 tw 也有機會被檔
yukai
2023-02-19 21:21:49
用 GCP taiwan region 的機器也被擋 XDrz
yellowsoar
2023-02-20 00:51:32
對,我一年前就是卡在這裡,還沒有空想要怎麼繞過去
╮( ̄▽ ̄“”)╭
╮( ̄▽ ̄“”)╭
yukai
19:41:58
@yellowsoar 剛好遇到 proxy 的問題,facebook 社團的爬蟲一定要在臺灣 IP 也能用,所以需要架在臺灣或是用其他的 proxy?
yukai
2023-02-16 19:44:14
比如這一頁,用無痕開的話 Surfshark 的 IP 也會變成需要登入 https://mbasic.facebook.com/groups/464870710346711
yukai
2023-02-16 19:49:45
用 tor exit node 設定 tw 也有機會被檔
yukai
2023-02-19 21:21:49
用 GCP taiwan region 的機器也被擋 XDrz
yellowsoar
2023-02-20 00:51:32
對,我一年前就是卡在這裡,還沒有空想要怎麼繞過去
╮( ̄▽ ̄“”)╭
╮( ̄▽ ̄“”)╭
yukai
19:44:14
比如這一頁,用無痕開的話 Surfshark 的 IP 也會變成需要登入 https://mbasic.facebook.com/groups/464870710346711
yukai
19:49:45
用 tor exit node 設定 tw 也有機會被檔
2023-02-19
yukai
21:21:49
用 GCP taiwan region 的機器也被擋 XDrz
2023-02-20
yellowsoar
00:51:32
對,我一年前就是卡在這裡,還沒有空想要怎麼繞過去
╮( ̄▽ ̄“”)╭
╮( ̄▽ ̄“”)╭
2023-02-24
yukai
18:36:26
噴火獸號:裴列恩之艦
Bibliogram has a feature to generate RSS / Atom feeds and I’m using it a lot. However, there are a few limitations, which also applies to RSSHub. First, Bibliogram on your IP address could be blocked by Instagram. This happens so often that a big part of discussion around Bibliogram is centered around this. I’ve tried a few solutions to this: Flowing the traffic through VPNs: doesn’t work, Instagram/FB has required login on all server IP sections by default. Flowing the traffic through “residential proxies": most residential proxies are not really ethical because they rely on embedding exit nodes to third-party applications. Application developers may integrate with their SDKs and the users of the application will be used as exit nodes, most often without clearly communicating the risks and benefits to them. Flowing the traffic through Cloudflare workers: same as VPNs, server IP ranges are mostly blocked. There’s also an added issue that each request from Cloudflare workers will use randomly different outbound IPs, and it’s not possible to bind to a single one. Flowing the traffic through mobile internet IPs: most mobile internet providers utilize carrier-grade NATs (CGNAT) so that tons of devices will use the same public IP. To avoid collateral damage of banning a ton of devices, IG/FB is very tolerant with the mobile IPs. Barely any rate limiting at all. However mobile IPs are expensive (compared to other solutions), to save data quota, I had to set up Squid proxy to route only the most critical requests (the main HTML file or some API calls) through the mobile internet while keeping the others (CDN requests) using an existing link. Flowing the traffic through the dynamic IP address provided by my home ISP: this is the solution that I settled on. I can configure the modem to re-dial PPPoE periodically to obtain different IPs. See Multihome for Docker containers for my PPPoE and docker setup. However, despite all of this, request quotas towards FB/IG is still a scarce resource. So that’s why I thought: once I crawled a page and generated a RSS feed, how can I benefit others safely? Second, when only using a simple reverse proxy, every request is handed directly over to Bibliogram, without any caching. So that means every update pull from the RSS reader will trigger a new crawl, consuming precious quota. So I realized it was necessary to set up caching on the reverse proxy. Third, the images in the RSS feed entries are originally served by FB/IG’s CDNs. The URL looks like: In the GET parameters contains a access key which is only valid for around a week (according to my testing). After which the CDN will no longer serve the file. The file is still there but you have to crawl the original post source again to get a new access key. However, once the RSS feed entry is published, the reader usually doesn’t update the entry. Even if it does, crawling the same post still eats up precious request quota. The best solution I can currently think of is to cache the image with Nginx as well. It will take up disk spaces but the images are already heavily compressed, so usually just a few hundred kilobytes a piece. Disk spaces also isn’t expensive nowadays. For RSSHub which just point the image src to CDNs, I’ll have to modify the code and make it point to Nginx. For Bibliogram, it already rewrites the image src to /imageproxy/Cj_XXXX.jpg, which can be easily cached by Nginx. Nginx proxy_store Enter Nginx proxy_store. Nginx proxy_store basically just saves a copy of the response on disk, with path equivalent to the request URI. It’s usually used to set up mirrors, of which objects usually don’t expire. However it does not offer expire functionality, so objects will have to be deleted from the cache manually. Nginx geo: differentiating client IPs The geo directive sets a nginx config variable to different values depending on the client IP address. This is useful for us to: Give trusted IPs access to the crawler (Bibliogram or RSSHub) and the cache. Give untrusted IPs access to only the cache. This way, untrusted IPs can’t make our crawlers crawl, but they can still use the contents the crawler has already generated. Putting it all together I marked the config sections “Section N" to explain the config flow. geo $whitelist { default static;#only allowed to cache 1.2.3.0/24 app;#allowed to invoke app } server { listen 443 ssl http2; listen [::]:443 ssl http2; server_name ; access_log /var/log/nginx/bibliogram.access.log; error_log /var/log/nginx/bibliogram.error.log; root /var/www/html; # sendfile on; tcp_nopush on; tcp_nodelay on; # # Section 1 location / { root /var/www/bibliogram; try_files $uri @${whitelist}; add_header X-Tier "tryfiles"; } # Don't cache the user html page, otherwise the filename will conflict # with the directory name /u//rss.xml # Section 2 location ~ /u/[\w\._-]*$ { root /var/www/bibliogram; try_files $uri @${whitelist}_nocache; add_header X-Tier "tryfiles_nocache"; } # Section 3 location @static { root /var/www/bibliogram; try_files $uri =404; } # Section 4 location @static_nocache { root /var/www/bibliogram; try_files $uri =404; } # Section 5 location @app { proxy_pass proxy_redirect off; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; proxy_store on; proxy_store_access user:rw group:rw all:r; proxy_temp_path /tmp/; add_header X-Tier "app_cache"; root /var/www/bibliogram; } # Section 6 location @app_nocache { proxy_pass proxy_redirect off; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; add_header X-Tier "app_nocache"; root /var/www/bibliogram; } ssl_certificate /etc/letsencrypt/live/bibliogram2/fullchain.pem; # managed by Certbot ssl_certificate_key /etc/letsencrypt/live/bibliogram2/privkey.pem; # managed by Certbot } This settings enable to following behavior: For trusted client IPs, the $whitelist variable will be set to app Section 1: if the URI is already cached, serve from the cache, if not go to the named location @$whitelist, which expands to @app (Section 5). Section 5: pass the request to Bibliogram, save the response under /var/www/bibliogram. For untrusted client IPs, the $whitelist variable will be set to static Section 1: if the URI is already cached, serve from the cache, if not go to the named location @$whitelist, which expands to @static (Section 3). Section 3: the same configuration as Section 1, which serves from the cache. If the URI is not present in cache, 404 is returned. This special case takes precedence over case 1 and 2. If request URI ends in /u/, which is the URI for HTML rendered pages of a user. The response should never be cached, because this page is only visited from browsers, and I want Bibliogram to crawl for the latest information for the user. This configuration also forbids untrusted IPs from accessing user HTML pages, since The the responses are never cached and the untrusted IPs can only access the cache. (Maybe I’ll change this in the future.) Result It turns out that, strangely, my RSS reader (Inoreader) will request a RSS feed file very frequently. Before setting up caching, this would make Bibliogram start to crawl Instagram every time, wasting the request quota. I guess this is because Inoreader uses the RSS lastBuildDate attribute to determine next crawl time. And since Bibliogram generates a new feed file every time Inoread…
yukai
2023-02-24 18:43:58
結果解法是 ~~中華電信浮動 IP + 定期重播嗎~~ 😂
yellowsoar
2023-03-03 17:26:43
對,0archive 好像也是這樣,這個解法和花錢租用 rotating proxy 是差不多的
yellowsoar
2023-03-03 17:37:11
另一個解法是用 PaaS 定期重啟換 IP
yukai
18:36:26
yukai
2023-02-24 18:43:58
結果解法是 ~~中華電信浮動 IP + 定期重播嗎~~ 😂
yellowsoar
2023-03-03 17:26:43
對,0archive 好像也是這樣,這個解法和花錢租用 rotating proxy 是差不多的
yellowsoar
2023-03-03 17:37:11
另一個解法是用 PaaS 定期重啟換 IP
yukai
18:43:58
結果解法是 ~~中華電信浮動 IP + 定期重播嗎~~ 😂